Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation论文精读(逐段解析)
论文地址:https://arxiv.org/abs/2408.04804
CVPR 2024
Yifan Feng, Jiangang Huang, Shaoyi Du, Senior Member, IEEE, Shihui Ying, Jun-Hai Yong, Yipeng Li, Guiguang Ding, Rongrong Ji, Senior Member, IEEE Yue Gao, Senior Member, IEEE
Abstract—We introduce Hyper-YOLO, a new object detection method that integrates hypergraph computations to capture the complex high-order correlations among visual features. Traditional YOLO models, while powerful, have limitations in their neck designs that restrict the integration of cross-level features and the exploitation of high-order feature interrelationships. To address these challenges, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGCSCS) framework, which transposes visual feature maps into a semantic space and constructs a hypergraph for high-order message propagation. This enables the model to acquire both semantic and structural information, advancing beyond conventional feature-focused learning. Hyper-YOLO incorporates the proposed Mixed Aggregation Network (MANet) in its backbone for enhanced feature extraction and introduces the HypergraphBased Cross-Level and Cross-Position Representation Network (HyperC2Net) in its neck. HyperC2Net operates across five scales and breaks free from traditional grid structures, allowing for sophisticated high-order interactions across levels and positions. This synergy of components positions Hyper-YOLO as a state-ofthe-art architecture in various scale models, as evidenced by its superior performance on the COCO dataset. Specifically, HyperYOLO-N significantly outperforms the advanced YOLOv8-N and YOLOv9-T with 12 % 12\% 12% A P v a l \mathbf{A}\mathbf{P}^{v a l} APval and 9 % 9\% 9% A P v a l \mathbf{A}\mathbf{P}^{v a l} APval improvements. The source codes are at https://github.com/iMoonLab/Hyper-YOLO.
Index Terms—Object Detection, Hypergraph, Hypergraph Nerual Networks, Hypergraph Computation
【翻译】我们介绍了Hyper-YOLO,这是一种新的目标检测方法,它集成了超图计算来捕获视觉特征之间复杂的高阶相关性。传统的YOLO模型虽然强大,但在颈部设计上存在局限性,限制了跨层特征的整合和高阶特征相互关系的利用。为了解决这些挑战,我们提出了超图计算赋能的语义收集与散布(HGCSCS)框架,该框架将视觉特征图转置到语义空间中,并构建超图进行高阶消息传播。这使得模型能够获取语义和结构信息,超越了传统的以特征为中心的学习。Hyper-YOLO在其骨干网络中融入了所提出的混合聚合网络(MANet)以增强特征提取,并在其颈部引入了基于超图的跨层跨位置表示网络(HyperC2Net)。HyperC2Net跨五个尺度运行,摆脱了传统的网格结构,允许跨层和跨位置的复杂高阶交互。这些组件的协同作用使Hyper-YOLO成为各种尺度模型中的最先进架构,这在COCO数据集上的卓越性能中得到了证明。具体地,HyperYOLO-N显著超越了先进的YOLOv8-N和YOLOv9-T,在 A P v a l \mathbf{A}\mathbf{P}^{v a l} APval上分别有 12 % 12\% 12%和 9 % 9\% 9%的改进。源代码可在https://github.com/iMoonLab/Hyper-YOLO获取。
索引词——目标检测,超图,超图神经网络,超图计算
【解析】Hyper-YOLO目标检测架构,核心思想是用超图这种数学结构来处理图像特征之间的复杂关系。传统的YOLO虽然检测效果不错,但它在处理不同层级特征融合时存在瓶颈。想象一下,图像特征就像是一个复杂的关系网络,传统方法只能看到简单的点对点连接,而超图可以同时连接多个点,形成更复杂的关系模式。HGCSCS框架的作用是将原本在图像空间中的特征映射到一个抽象的语义空间,在这个空间中构建超图结构,让特征之间可以进行更丰富的信息交换。MANet负责增强特征提取能力,而HyperC2Net则突破了传统网格限制,能够在五个不同尺度上进行特征融合。这种设计让模型不仅能理解单个特征的含义,还能掌握特征之间的复杂关联,从而显著提升检测精度。论文通过在COCO数据集上的实验证明了这种方法的有效性,相比现有先进方法有明显的性能提升。
I. INTRODUCTION
The YOLO series [1]–[11] stands out as a mainstream method in the realm of object detection, offering several advantages that cater to these diverse applications. The architecture of YOLO consists of two main components: the backbone [7], [12]–[14] and neck [10], [15], [16]. While the backbone is designed for feature extraction and has been extensively studied, the neck is responsible for the fusion of multi-scale features, providing a robust foundation for the detection of variously sized objects. This paper places a particular emphasis on the neck, which is paramount in enhancing the model’s ability to detect objects across different scales.
【翻译】YOLO系列[1]–[11]作为目标检测领域的主流方法脱颖而出,提供了满足这些多样化应用的若干优势。YOLO的架构由两个主要组件组成:骨干网络[7], [12]–[14]和颈部网络[10], [15], [16]。虽然骨干网络设计用于特征提取并已被广泛研究,但颈部网络负责多尺度特征的融合,为检测各种尺寸的目标提供了稳健的基础。本文特别强调颈部网络,它在增强模型跨不同尺度检测目标的能力方面至关重要。
【解析】YOLO目标检测框架主要分为两大部分:骨干网络负责从原始图像中提取基础的视觉特征,就像人眼看到图像时首先识别边缘、纹理、颜色等基本信息一样。而颈部网络则承担着更复杂的任务——将来自不同层级的特征进行融合整合。这种融合非常重要,因为不同层级的特征包含不同尺度的信息:浅层特征保留了细节信息,适合检测小目标;深层特征包含了语义信息,适合检测大目标。颈部网络就是要把这些不同层次的信息巧妙地结合起来,让模型既能检测到画面中的小物体,也能准确识别大物体。作者强调要重点改进颈部网络,说明这是提升检测性能的关键瓶颈所在。
Fig. 1. Comparison with other SOTA YOLO series methods on the COCO.
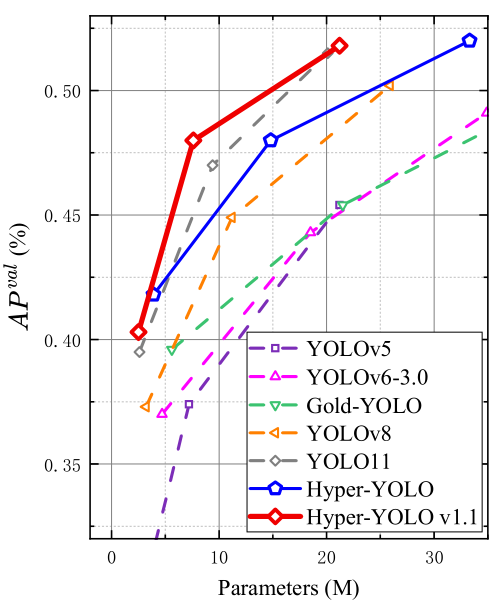
【翻译】图1. 在COCO数据集上与其他SOTA YOLO系列方法的比较。
Contemporary YOLO models have adopted the PANet [16] for their necks, which employs top-down and bottom-up pathways to facilitate a comprehensive fusion of information across scales. However, the PANet’s capability is predominantly confined to fusing features between adjacent layers and does not sufficiently address cross-level feature integration. In contrast, the gather-distribute neck design, exemplified by Gold-YOLO [10], promotes inter-layer information exchange but still falls short of facilitating cross-position interactions within the feature map. Moreover, it does not thoroughly explore the potential of feature interrelationships, particularly those involving high-order correlations. High-order correlations refer to the complex and often non-linear relationships that exist between features at different scales, positions, and semantic levels, which are critical for understanding the deeper context and interactions within visual data. It is noticed that the synergistic representation of low-level visual features and their correlations plays a critical role in the object detection task. The integration of these basic features with high-level semantic information is crucial for the accurate identification and localization of objects within a given scene. The exploration of high-order correlations underlying low-level features for semantic analysis remains a challenging yet essential topic within many computer vision tasks. This phenomenon, where the mining of such high-order relationships is commonly overlooked, may limit the performance of vision tasks.
【翻译】当代YOLO模型在其颈部网络中采用了PANet[16],它使用自顶向下和自底向上的路径来促进跨尺度信息的全面融合。然而,PANet的能力主要局限于相邻层之间的特征融合,并不能充分解决跨层特征集成问题。相比之下,以Gold-YOLO[10]为例的收集-分发颈部设计促进了层间信息交换,但仍然无法充分实现特征图内的跨位置交互。此外,它没有充分探索特征相互关系的潜力,特别是那些涉及高阶相关性的关系。高阶相关性是指存在于不同尺度、位置和语义层级的特征之间的复杂且通常非线性的关系,这对于理解视觉数据中更深层的上下文和交互至关重要。注意到低级视觉特征及其相关性的协同表示在目标检测任务中起着关键作用。这些基础特征与高级语义信息的整合对于给定场景中目标的准确识别和定位至关重要。探索低级特征背后用于语义分析的高阶相关性仍然是许多计算机视觉任务中具有挑战性但又必不可少的主题。这种通常忽视此类高阶关系挖掘的现象可能会限制视觉任务的性能。
【解析】PANet作为当前主流的特征融合方法,主要通过上下双向的信息流动来整合不同层级的特征,但这种设计存在明显的局限性。首先,它主要处理相邻层之间的特征融合,就像只能和旁边邻居交流,却无法与更远距离的层级进行直接对话。Gold-YOLO虽然在层间信息交换方面有所改进,但仍然无法实现特征图内不同空间位置之间的有效交互。更重要的是,现有方法都忽视了高阶相关性这个核心概念。高阶相关性不同于简单的两两特征关系,它描述的是多个特征之间复杂的非线性关联模式。在视觉理解中,这种高阶关系反映了图像中物体之间的复杂空间关系、语义关联以及上下文依赖。比如识别一个人,不仅要看到人的轮廓,还要理解头部、身体、四肢之间的空间配置关系,以及这些部分与背景环境的语义关联。低级特征提供了基础的视觉元素,而高阶相关性则揭示了这些元素如何组合形成有意义的视觉概念。忽视这种高阶关系就像只见树木不见森林,限制了模型对复杂视觉场景的理解能力。
In practice, hypergraphs [17], [18] are commonly employed to represent complex high-order correlations due to their enhanced expressive power over simple graphs. While edges in a simple graph are limited to connecting only two vertices, thereby greatly restricting their expressiveness, hyperedges in a hypergraph can connect two or more vertices, enabling the modeling of more intricate high-order relationships. Compared to simple graphs, hypergraphs can capture a richer set of interactions among multiple entities, which is vital for tasks that require an understanding of complex and multi-way relationships, such as object detection in computer vision, where those cross-level and cross-position correlations among feature maps are crucial.
【翻译】在实践中,超图[17], [18]由于其相对于简单图的增强表达能力,被普遍用于表示复杂的高阶相关性。虽然简单图中的边仅限于连接两个顶点,从而极大地限制了其表达能力,但超图中的超边可以连接两个或更多顶点,能够建模更复杂的高阶关系。与简单图相比,超图可以捕获多个实体之间更丰富的交互集合,这对于需要理解复杂多向关系的任务至关重要,例如计算机视觉中的目标检测,其中特征图之间的跨层级和跨位置相关性是关键的。
【解析】传统的图结构只能表示两个节点之间的连接关系,超图通过超边的概念突破了这个限制,一条超边可以同时连接多个节点,能够直接建模这种多元关系。在目标检测中,不同位置、不同层级的特征点之间存在复杂的相互依赖关系,这些关系往往不是简单的两两配对,而是多个特征共同作用的结果。超图结构正好能够捕获这种复杂的关联模式,为理解图像中物体间的空间关系、语义关联提供了更强大的数学框架。这就像从二维平面的思维跳跃到了多维空间的关系建模,大大增强了模型表达复杂视觉关系的能力。
Different from most previous works focusing on enhancing the backbone of feature extraction, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework. This framework is ingeniously conceived to enhance the feature maps extracted by the visual backbone through their transposition into an abstract semantic space, followed by the construction of an intricate hypergraph structure. The hypergraph serves as a conduit for enabling high-order message propagation among the features within this semantic space. Such an approach equips the visual backbone with the dual capability of assimilating both semantic and complex structural information, thereby overcoming the limitations of conventional semantic feature-focused learning and elevating performance beyond its traditional bounds.
【翻译】与大多数专注于增强特征提取骨干网络的先前工作不同,我们提出了超图计算赋能的语义收集与散布(HGC-SCS)框架。该框架巧妙地设计来增强视觉骨干网络提取的特征图,通过将其转置到抽象语义空间中,然后构建复杂的超图结构。超图作为管道,使得这个语义空间内特征之间能够进行高阶消息传播。这种方法使视觉骨干网络具备了同时吸收语义和复杂结构信息的双重能力,从而克服了传统以语义特征为中心的学习的局限性,并将性能提升到了传统界限之外。
【解析】提出HGC-SCS框架。以往的研究主要集中在改进骨干网络的特征提取能力。作者另辟蹊径,重点改进的是如何处理和利用已提取的特征。这个框架的工作原理可以分为三个关键步骤:首先是"收集",将来自不同层级的视觉特征统一映射到一个抽象的语义空间中,这个空间不再受限于原始图像的网格结构;然后在这个语义空间中构建超图,建立特征之间的高阶关联;最后通过超图进行消息传播,让特征之间进行充分的信息交换。这种设计的巧妙之处在于将视觉特征从固定的空间位置中解放出来,让它们在语义层面上自由交互。传统方法只能学习到每个特征的语义含义,而这个框架还能学习到特征之间的复杂结构关系,相当于既知道每个零件的功能,又明白它们如何组合成完整的机器。
Building upon the aforementioned HGC-SCS framework, we introduce Hyper-YOLO, a new YOLO method based on hypergraph computation. Hyper-YOLO, for the first time, integrates hypergraph computation within the neck component of a visual target detection network. By modeling the intricate high-order associations inherent to feature maps extracted from the backbone, Hyper-YOLO substantially enhances object detection performance. In terms of the backbone architecture, Hyper-YOLO incorporates the Mixed Aggregation Network (MANet), which amalgamates three distinctive foundational structures to enrich the flow of information and augment feature extraction capabilities, building upon the base provided by YOLOv8. In the realm of the neck, leveraging the proposed HGC-SCS framework, we achieve a multi-scale feature fusion neck known as the Hypergraph-Based Cross-Level and CrossPosition Representation Network (HyperC2Net). In contrast to conventional neck designs, HyperC2Net fuses features across five different scales, concurrently breaking away from the grid structure of visual feature maps to facilitate highorder message propagation across levels and positions. The combined enhancements in both the backbone and the neck position Hyper-YOLO as a groundbreaking architecture. The empirical results (Figure 1) on the COCO dataset attest to its significant superiority in performance, substantiating the efficacy of this sophisticated approach in advancing the field of object detection. Our contributions can be summarized as:
【翻译】基于上述HGC-SCS框架,我们引入了Hyper-YOLO,一种基于超图计算的新YOLO方法。Hyper-YOLO首次在视觉目标检测网络的颈部组件中集成了超图计算。通过建模从骨干网络提取的特征图固有的复杂高阶关联,Hyper-YOLO显著增强了目标检测性能。在骨干网络架构方面,Hyper-YOLO融入了混合聚合网络(MANet),该网络结合了三种不同的基础结构来丰富信息流并增强特征提取能力,建立在YOLOv8提供的基础之上。在颈部网络领域,利用所提出的HGC-SCS框架,我们实现了一个多尺度特征融合颈部网络,称为基于超图的跨层级和跨位置表示网络(HyperC2Net)。与传统颈部设计相比,HyperC2Net跨五个不同尺度融合特征,同时摆脱了视觉特征图的网格结构,以促进跨层级和位置的高阶消息传播。骨干网络和颈部网络的联合增强使Hyper-YOLO成为一个突破性的架构。在COCO数据集上的实验结果(图1)证明了其显著的性能优势,证实了这种复杂方法在推进目标检测领域方面的有效性。我们的贡献可以总结如下:
【解析】Hyper-YOLO是第一个将超图计算引入目标检测网络颈部的方法。整个系统采用了双重改进策略:在骨干网络部分引入MANet来增强特征提取,在颈部网络部分应用HyperC2Net来实现高阶特征融合。MANet通过整合三种不同的网络结构来丰富信息流动路径,让特征信息能够更充分地传递和交互。HyperC2Net不仅处理五个不同尺度的特征(比传统的三个尺度更全面),更重要的是彻底打破了传统的网格约束。在传统方法中,特征图中的每个位置只能与其空间邻近的位置交互,而HyperC2Net通过超图结构实现了跨层级、跨位置的自由交互,让任意位置的特征都可能建立关联,大大提升了信息整合的灵活性和有效性。
- We propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework, enhancing visual backbones with high-order information modeling and learning.
- Leveraging the proposed HGC-SCS framework, we develop HyperC2Net, an object detection neck that facilitates high-order message passing throughout semantic layers and positions. HyperC2Net markedly elevates the neck’s proficiency in distilling high-order features.
- We propose the Mixed Aggregation Network (MANet), which incorporates three types of blocks to enrich the information flow, thereby enhancing the feature extraction capabilities of the backbone.
- We present Hyper-YOLO, which incorporates hypergraph computations to enhance the model’s high-order information perception capabilities, leading to improvements in object detection. Specifically, our HyperYOLO-N achieves significant improvements in A P ˙ v a l \mathrm{A}\dot{\mathbf{P}}^{v a l} AP˙val , with a 12 % 12\% 12% increase compared to YOLOv8-N and a 9 % 9\% 9% increase compared to YOLOv9-T on the COCO dataset.
【翻译】1) 我们提出了超图计算赋能的语义收集与散布(HGC-SCS)框架,通过高阶信息建模和学习来增强视觉骨干网络。
2) 利用所提出的HGC-SCS框架,我们开发了HyperC2Net,这是一个促进语义层和位置间高阶消息传递的目标检测颈部网络。HyperC2Net显著提升了颈部网络提取高阶特征的能力。
3) 我们提出了混合聚合网络(MANet),它结合了三种类型的模块来丰富信息流,从而增强骨干网络的特征提取能力。
4) 我们提出了Hyper-YOLO,它结合超图计算来增强模型的高阶信息感知能力,从而改进目标检测。具体地,我们的HyperYOLO-N在 A P v a l \mathrm{A}{\mathbf{P}}^{val} APval上取得显著改进,与YOLOv8-N相比提高了 12 % 12\% 12%,与YOLOv9-T相比提高了 9 % 9\% 9%。
【解析】HGC-SCS为在视觉任务中应用超图计算提供了通用的方法论,这不仅适用于目标检测,还可能扩展到其他计算机视觉任务。HyperC2Net将理论框架转化为可实施的网络组件,专门用于处理多尺度特征融合中的高阶关系建模。MANet通过巧妙地结合三种不同的卷积结构,为整个系统提供了更强的特征提取基础。
II. RELATED WORK
A. YOLO Series Object Detectors
The YOLO series has been a cornerstone in real-time object detection, evolving from YOLOv1’s [1] single-stage detection to YOLOv8’s [8] performance-optimized models. Each iteration, from YOLOv4’s [3] structural refinements to YOLOv7’s [7] E-ELAN backbone, has brought significant advancements. YOLOX [9] introduced anchor-free detection, and Gold-YOLO [10] enhanced feature fusion with its Gather-andDistribute mechanism. Despite the emergence of RT-DETR [19] and other detectors, the YOLO series remains prevalent, partly due to its effective use of CSPNet, ELAN [14], and improved PANet [16] or FPN [15] for feature integration, coupled with sophisticated prediction heads from YOLOv3 [2] and FCOS [20]. YOLOv9 [21] introduces programmable gradient information and the Generalized Efficient Layer Aggregation Network to minimize information loss during deep network transmission. Building upon those YOLO methods, this paper presents Hyper-YOLO, an advanced approach that leverages hypergraph computations to enhance the complex correlation learning capabilities of the YOLO framework. Hyper-YOLO aims to improve the learning and integration of hierarchical features, pushing the boundaries of object detection performance.
【翻译】YOLO系列一直是实时目标检测的基石,从YOLOv1的[1]单阶段检测发展到YOLOv8的[8]性能优化模型。从YOLOv4的[3]结构改进到YOLOv7的[7] E-ELAN骨干网络,每一次迭代都带来了显著的进步。YOLOX [9]引入了无锚检测,Gold-YOLO [10]通过其收集-分发机制增强了特征融合。尽管RT-DETR [19]和其他检测器的出现,YOLO系列仍然普遍存在,部分原因是其有效使用CSPNet、ELAN [14]以及改进的PANet [16]或FPN [15]进行特征集成,结合了来自YOLOv3 [2]和FCOS [20]的复杂预测头。YOLOv9 [21]引入了可编程梯度信息和广义高效层聚合网络,以最小化深度网络传输过程中的信息损失。基于这些YOLO方法,本文提出了Hyper-YOLO,这是一种利用超图计算来增强YOLO框架复杂相关性学习能力的先进方法。Hyper-YOLO旨在改进分层特征的学习和集成,推动目标检测性能的边界。
【解析】YOLOv1确立单阶段检测范式;YOLOv4通过结构性改进提升检测精度;YOLOv7引入E-ELAN优化特征提取;YOLOX无锚设计;Gold-YOLO收集-分发机制改进多尺度特征融合。YOLOv9引入可编程梯度信息,解决深度网络中的信息传输损失问题,广义高效层聚合网络保障梯度信息在网络深层传播过程中的完整性。Hyper-YOLO引入超图计算增强模型对复杂特征关联的学习能力,从数学建模的角度重新审视和优化特征学习过程。
B. Hypergraph Learning Methods
A hypergraph [17], [18] can be utilized to capture these complex, high-order associations. Hypergraphs, with their hyperedges connecting multiple nodes, excel in modeling intricate relationships, as evidenced in their application to diverse domains such as social network analysis [22], [23], drug-target interaction modeling [24], [25], and brain network analysis [26], [27]. Hypergraph learning methods have emerged as a powerful tool for capturing complex and high-order correlations in data, which traditional graph-based techniques may not adequately represent. The notion of hyperedges, as discussed in Gao et al. [17], facilitates the modeling of these intricate relationships by allowing multiple nodes to interact simultaneously. Hypergraph Neural Networks (HGNN) [28] exploit these relationships, enabling direct learning from hypergraph structures through spectral methods. Building on this, General Hypergraph Neural Networks ( H G N N + ) (\mathrm{HGNN^{+}}) (HGNN+) ) [18] introduce spatial approaches for high-order message propagation among vertices, further expanding the capabilities of hypergraph learning. Despite these advancements, the application of hypergraph learning in computer vision tasks remains relatively unexplored, particularly in the areas of modeling and learning high-order associations. In this paper, we will delve into how hypergraph computations can be harnessed for object detection tasks, aiming to elevate both classification and localization accuracy by integrating the nuanced relational information that modeled by the hypergraph.
【翻译】超图[17], [18]可以用来捕获这些复杂的高阶关联。超图通过其连接多个节点的超边,在建模复杂关系方面表现卓越,这在其应用于社会网络分析[22], [23]、药物-靶点相互作用建模[24], [25]和大脑网络分析[26], [27]等多个领域中得到了证明。超图学习方法已经成为捕获数据中复杂高阶相关性的强大工具,这是传统基于图的技术可能无法充分表示的。如Gao等人[17]讨论的超边概念,通过允许多个节点同时交互来促进这些复杂关系的建模。超图神经网络(HGNN)[28]利用这些关系,通过谱方法实现从超图结构的直接学习。在此基础上,广义超图神经网络 ( H G N N + ) (\mathrm{HGNN^{+}}) (HGNN+)[18]引入了空间方法来实现顶点间的高阶消息传播,进一步扩展了超图学习的能力。尽管有这些进展,超图学习在计算机视觉任务中的应用仍然相对未被充分探索,特别是在高阶关联的建模和学习领域。在本文中,我们将深入探讨如何利用超图计算进行目标检测任务,旨在通过整合超图建模的细致关系信息来提升分类和定位精度。
【解析】超图学习是强大的数学工具。传统图论只能表达两个节点间的连接关系,而超图通过超边的概念实现了一个质的飞跃,能够同时连接任意数量的节点。这种能力使得超图特别适合处理现实世界中普遍存在的多元关系。在社会网络中,一个事件可能同时影响多个人;在药物研究中,一个药物分子可能同时与多个生物靶点产生相互作用;在神经科学中,大脑的不同区域会形成复杂的协同工作网络。HGNN通过谱方法进行学习,这意味着它利用超图的代数性质来理解和处理信息。而HGNN+则采用了空间方法,更直接地在超图的几何结构上进行消息传递。这两种方法各有优势:谱方法在理论上更加严密,而空间方法在计算上更加直观和高效。在计算机视觉领域,图像中的视觉元素之间存在着复杂的空间关系、语义关联以及上下文依赖,这些都是典型的高阶关系。传统的卷积神经网络虽然能够学习空间特征,但在捕获这种复杂的多元关系方面仍有不足。超图学习为解决这个问题提供了新的数学框架和计算工具。
III. HYPERGRAPH COMPUTATION EMPOWERED SEMANTIC COLLECTING AND SCATTERING FRAMEWORK
Unlike representation learning in computer vision only processes visual features, those hypergraph computation methods [18], [28] simultaneously process features and high-order structures. Most hypergraph computation methods rely on the inherent hypergraph structures, which cannot be obtained in most computer vision scenarios. Here, we introduce the general paradigm of hypergraph computation in computer vision, which includes hypergraph construction and hypergraph convolution. Given the feature map X \boldsymbol{X} X extracted from the neural networks, the hypergraph construction function f : X → G f:X\to{\mathcal{G}} f:X→G is adopted to estimate the potential highorder correlations among feature points in the semantic space. Then, the spectral or spatial hypergraph convolution methods are utilized to propagate high-order messages among feature points via the hypergraph structure. The generated high-order features are termed X h y p e r X_{h y p e r} Xhyper . By integrating high-order relational information into X h y p e r {\bf X}_{h y p e r} Xhyper , this hypergraph computation strategy addresses the deficiency of high-order correlations in the original feature map X \mathbf{X} X . The resultant hybrid feature map, denoted as X ′ \mathbf{X}^{\prime} X′ , emerges from the fusion of X \mathbf{X} X and X h y p e r \mathbf{X}_{\mathrm{hyper}} Xhyper . This synthesized process culminates in a semantically enhanced visual representation X ′ \mathbf{X}^{\prime} X′ , which provides more comprehensive visual feature representations from both semantic and highorder structural perspectives.
【翻译】与仅处理视觉特征的计算机视觉表示学习不同,这些超图计算方法[18], [28]同时处理特征和高阶结构。大多数超图计算方法依赖于固有的超图结构,这在大多数计算机视觉场景中无法获得。在这里,我们介绍了计算机视觉中超图计算的一般范式,包括超图构建和超图卷积。给定从神经网络提取的特征图 X \boldsymbol{X} X,采用超图构建函数 f : X → G f:X\to{\mathcal{G}} f:X→G来估计语义空间中特征点之间的潜在高阶相关性。然后,利用谱域或空间域超图卷积方法通过超图结构在特征点之间传播高阶消息。生成的高阶特征被称为 X h y p e r X_{hyper} Xhyper。通过将高阶关系信息整合到 X h y p e r {\bf X}_{hyper} Xhyper中,这种超图计算策略解决了原始特征图 X \mathbf{X} X中高阶相关性的不足。由 X \mathbf{X} X和 X h y p e r \mathbf{X}_{\mathrm{hyper}} Xhyper融合产生的混合特征图表示为 X ′ \mathbf{X}^{\prime} X′。这种合成过程最终产生语义增强的视觉表示 X ′ \mathbf{X}^{\prime} X′,从语义和高阶结构两个角度提供更全面的视觉特征表示。
【解析】超图计算与传统计算机视觉方法的差异:传统的视觉表示学习方法主要关注单一特征的提取和处理,就像每个像素点或特征点都是独立的个体。而超图计算方法的核心优势在于它能同时处理特征内容和特征之间的复杂关系结构。这种方法的挑战在于,与社交网络或生物网络等天然具有图结构的数据不同,计算机视觉中的图像数据并不直接提供超图结构。因此需要通过超图构建函数 f f f从原始特征图 X \boldsymbol{X} X中推断和建立潜在的高阶关联。这个函数实际上是在语义空间中寻找特征点之间可能存在的复杂依赖关系。接下来的超图卷积操作是整个框架的核心计算步骤,它通过谱域方法(基于超图的频域分析)或空间域方法(直接在超图的几何结构上操作)来实现高阶信息的传播。这种传播机制允许每个特征点不仅利用自身的信息,还能接收来自与其有高阶关联的其他特征点的信息。最终的特征融合过程将原始特征 X \mathbf{X} X的局部信息与经过超图处理的全局高阶信息 X h y p e r \mathbf{X}_{\mathrm{hyper}} Xhyper相结合,产生既保留原始语义内容又富含结构关系的增强表示 X ′ \mathbf{X}^{\prime} X′。
Here, we devise a general framework for hypergraph computation in computer vision, named the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGCSCS) framework. Given those feature maps extracted from CNN [29]–[34] or other backbones, our framework first collects those features and fuses them to construct the mixed feature bag X m i x e d X_{mixed} Xmixed in the semantic space. In the second step, we estimate those potential high-order correlations to construct the hypergraph structure in the semantic space. To fully utilize those high-order structure information, some related hypergraph computation methods [18], [28] can be employed. In this way, the high-order aware feature X h y p e r X_{hyper} Xhyper can be generated, which incorporates both the high-order structural and the semantic information. In the last step, we scatter the high-order structural information to each input feature map. The HGC-SCS framework can be formulated as follows:
【翻译】在这里,我们设计了一个用于计算机视觉中超图计算的通用框架,名为超图计算赋能的语义收集与散布(HGC-SCS)框架。给定从CNN [29]–[34]或其他骨干网络提取的特征图,我们的框架首先收集这些特征并将其融合以在语义空间中构建混合特征包 X m i x e d X_{mixed} Xmixed。在第二步中,我们估计这些潜在的高阶相关性以在语义空间中构建超图结构。为了充分利用这些高阶结构信息,可以采用一些相关的超图计算方法[18], [28]。通过这种方式,可以生成高阶感知特征 X h y p e r X_{hyper} Xhyper,它结合了高阶结构和语义信息。在最后一步,我们将高阶结构信息散布到每个输入特征图中。
【解析】HGC-SCS框架将抽象的超图理论转化为可实施的计算机视觉算法。在收集阶段,框架需要处理来自不同网络层级的特征图,这些特征图具有不同的空间分辨率和语义抽象级别。将它们统一到一个混合特征包 X m i x e d X_{mixed} Xmixed中,实际上是在创建一个统一的语义表示空间,这个空间不再受限于原始图像的空间布局约束。第二步的超图构建是整个框架的核心创新,它需要从混合特征中识别和建模潜在的高阶关联模式。这个过程涉及复杂的相似性计算和关系推理。超图计算阶段利用已有的成熟算法来处理构建好的超图结构,生成的 X h y p e r X_{hyper} Xhyper不仅包含了原始的语义信息,更重要的是融入了通过超图结构学习到的高阶关系知识。最后的散布阶段将这种全局的高阶信息重新分配给各个输入特征图,使得每个特征图都能受益于全局的结构信息,从而实现局部特征与全局结构的有机结合(感觉图像配准的描述符相似性也可以受益于超图的高阶关联,例如极端视角变化情况下,通过语义的强关联弥补几何结构的不一致性)。
{ X mixed ← Collecting { X 1 , X 2 , ⋯ } X hyper = HyperComputation ( X mixed ) //High-Order Learning { X 1 ′ , X 2 ′ , ⋯ } ← Scattering { ϕ ( X hyper , X 1 ) , ϕ ( X hyper , X 2 ) , ⋯ } \begin{cases} \boldsymbol{X}_{\text{mixed}} \xleftarrow{\text{Collecting}} \{\boldsymbol{X}_1, \boldsymbol{X}_2, \cdots\} \\ \boldsymbol{X}_{\text{hyper}} = \text{HyperComputation}(\boldsymbol{X}_{\text{mixed}}) \quad \text{\textit{//High-Order Learning}} \\ \{\boldsymbol{X}_1', \boldsymbol{X}_2', \cdots\} \xleftarrow{\text{Scattering}} \{\phi(\boldsymbol{X}_{\text{hyper}}, \boldsymbol{X}_1), \phi(\boldsymbol{X}_{\text{hyper}}, \boldsymbol{X}_2), \cdots\} \end{cases} ⎩ ⎨ ⎧XmixedCollecting{X1,X2,⋯}Xhyper=HyperComputation(Xmixed)//High-Order Learning{X1′,X2′,⋯}Scattering{ϕ(Xhyper,X1),ϕ(Xhyper,X2),⋯}
where { X 1 , X 2 , … } \{X_{1},X_{2},\dots\} {X1,X2,…} denotes the basic feature maps generated from the visual backbone. The “HyperComputation” denotes the second step, including hypergraph construction and hypergraph convolution, which captures those potential high-order structural information in the semantic space and generates the high-order aware feature X h y p e r X_{hyper} Xhyper . In the last line, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) denotes the feature fusion function. { X 1 ′ , X 2 ′ , ⋅ ⋅ } \left\{X_{1}^{\prime},X_{2}^{\prime},\cdot\cdot\right\} {X1′,X2′,⋅⋅} denotes the enhanced visual feature maps. In the following, we will introduce an instance of our HGC-SCS framework in object detection named HyperC2Net.
【翻译】其中 { X 1 , X 2 , … } \{X_{1},X_{2},\dots\} {X1,X2,…}表示从视觉骨干网络生成的基本特征图。"HyperComputation"表示第二步,包括超图构建和超图卷积,它捕获语义空间中的潜在高阶结构信息并生成高阶感知特征 X h y p e r X_{hyper} Xhyper。在最后一行, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)表示特征融合函数。 { X 1 ′ , X 2 ′ , ⋯ } \left\{X_{1}^{\prime},X_{2}^{\prime},\cdots\right\} {X1′,X2′,⋯}表示增强的视觉特征图。接下来,我们将介绍我们的HGC-SCS框架在目标检测中的一个实例,名为HyperC2Net。
【解析】公式描述了HGC-SCS框架的三个核心步骤。第一个等式展示了收集过程,使用特殊的箭头符号 ← Collecting \xleftarrow{\text{Collecting}} Collecting表明这是一个聚合操作,将来自不同层级的多个特征图 { X 1 , X 2 , ⋯ } \{X_1, X_2, \cdots\} {X1,X2,⋯}整合成统一的混合特征表示 X mixed X_{\text{mixed}} Xmixed。这个过程通常涉及特征对齐、尺度归一化等预处理步骤。第二个等式定义了核心的超图计算过程,HyperComputation函数封装了从超图构建到超图卷积的完整计算流程。这个函数的输入是混合特征 X mixed X_{\text{mixed}} Xmixed,输出是经过高阶关系学习的特征 X hyper X_{\text{hyper}} Xhyper。注释"High-Order Learning"强调了这一步骤的核心价值在于学习特征间的复杂高阶依赖关系。第三个等式描述了散布过程,通过特征融合函数 ϕ \phi ϕ将全局的高阶信息 X hyper X_{\text{hyper}} Xhyper与每个原始特征图 X i X_i Xi相结合,生成增强后的特征图 X i ′ X_i' Xi′。这种设计确保了每个输出特征图都同时包含其原始的局部信息和从超图学习得到的全局结构信息。HyperC2Net作为该框架在目标检测领域的具体实现,将展示如何将这种抽象的数学框架转化为实际的网络架构。
IV. METHODS
In this section, we first introduce preliminaries of YOLO notations as well as the framework of the proposed HyperYOLO. In the following, we detail the proposed two core modules, including the basic block (MANet) and neck (HyperC2Net) of our Hyper-YOLO. Finally, we analyze the relationship between Hyper-YOLO and other YOLO methods.
【翻译】在本节中,我们首先介绍YOLO符号的基础知识以及所提出的HyperYOLO框架。接下来,我们详细介绍所提出的两个核心模块,包括我们Hyper-YOLO的基本构建块(MANet)和颈部(HyperC2Net)。最后,我们分析Hyper-YOLO与其他YOLO方法之间的关系。
A. Preliminaries
The YOLO series methods [1]–[5], [7], [8], [21], [35]–[39] are typically composed of two main components: backbone and neck. The backbone [40] [13] is responsible for extracting fundamental visual features, while the neck [15] [16] [19] facilitates the fusion of multi-scale features for the final object detection. This paper proposes enhancement strategies specifically targeting these two components. For ease of description within this paper, we denote the three scale outputs of the neck as { N 3 , N 4 , N 5 } \{N_{3},N_{4},N_{5}\} {N3,N4,N5} , corresponding respectively to smallscale, medium-scale, and large-scale detection. In the feature extraction phase of the backbone, we further divide it into five stages: { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_{1},B_{2},B_{3},B_{4},B_{5}\} {B1,B2,B3,B4,B5} , which represent features at different semantic levels. A larger number indicates that the feature is a higher-level semantic feature extracted by a deeper layer of the network. More details are provided in section A.
【翻译】YOLO系列方法[1]–[5], [7], [8], [21], [35]–[39]通常由两个主要组件组成:骨干网络和颈部。骨干网络[40] [13]负责提取基础视觉特征,而颈部[15] [16] [19]促进多尺度特征的融合以进行最终的目标检测。本文提出专门针对这两个组件的增强策略。为了便于在本文中描述,我们将颈部的三个尺度输出表示为 { N 3 , N 4 , N 5 } \{N_{3},N_{4},N_{5}\} {N3,N4,N5},分别对应小尺度、中尺度和大尺度检测。在骨干网络的特征提取阶段,我们进一步将其划分为五个阶段: { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_{1},B_{2},B_{3},B_{4},B_{5}\} {B1,B2,B3,B4,B5},它们代表不同语义级别的特征。较大的数字表示该特征是由网络更深层提取的更高级语义特征。更多细节在A节中提供。
【解析】骨干网络承担着从原始像素信息中逐步抽象出语义特征的重任,这个过程遵循从局部到全局、从低级到高级的特征学习范式。颈部网络则专注于解决多尺度目标检测的核心挑战——如何有效融合不同分辨率和语义层次的特征信息。三个尺度输出 { N 3 , N 4 , N 5 } \{N_3, N_4, N_5\} {N3,N4,N5},每个尺度专门负责检测特定大小范围的目标对象。骨干网络的五阶段划分 { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_1, B_2, B_3, B_4, B_5\} {B1,B2,B3,B4,B5}刻画了特征抽象的渐进过程,YOLO这种分层设计为超图计算提供多层次特征输入,使得高阶关系建模能够跨越不同的语义抽象级别进行。
B. Hyper-YOLO Overview
Our Hyper-YOLO framework maintains the overall architecture of the typical YOLO methods, including the backbone and neck, as depicted in fig. S1. Given an image, the backbone of Hyper-YOLO leverages the proposed MANet as its core computational module, thereby augmenting the feature discernment ability of the conventional C2f module found in YOLOv8 [8]. Diverging from traditional YOLO architectures, Hyper-YOLO ingests an ensemble of five primary feature sets { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_{1},B_{2},B_{3},B_{4},B_{5}\} {B1,B2,B3,B4,B5} . In a novel stride, the neck (HyperC2Net) of Hyper-YOLO, grounded in hypergraph computational theory, integrates cross-level and cross-position information across these quintuple feature sets, culminating in the generation of final semantic features { N 3 , N 4 , N 5 } \{N_{3},N_{4},N_{5}\} {N3,N4,N5} across three distinct scales. These hierarchically structured semantic features are subsequently harnessed for the final object detection task.
【翻译】我们的Hyper-YOLO框架保持了典型YOLO方法的整体架构,包括骨干网络和颈部,如图S1所示。给定一张图像,Hyper-YOLO的骨干网络利用所提出的MANet作为其核心计算模块,从而增强了YOLOv8 [8]中常规C2f模块的特征识别能力。与传统YOLO架构不同,Hyper-YOLO接收五个主要特征集合 { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_{1},B_{2},B_{3},B_{4},B_{5}\} {B1,B2,B3,B4,B5}的集成。在一个新颖的步骤中,基于超图计算理论的Hyper-YOLO颈部(HyperC2Net)整合了这五个特征集合中的跨层级和跨位置信息,最终生成三个不同尺度的最终语义特征 { N 3 , N 4 , N 5 } \{N_{3},N_{4},N_{5}\} {N3,N4,N5}。这些层次结构化的语义特征随后被用于最终的目标检测任务。
【解析】骨干网络部分引入MANet模块,传统的C2f模块主要关注单一层级的特征处理,而MANet通过混合聚合机制能够同时处理多种类型的卷积操作,这使得特征提取过程更加丰富和全面。更重要的是,Hyper-YOLO打破了传统YOLO只使用三个尺度特征的限制,扩展到五个特征集合的处理。这种扩展不是简单的数量增加,而是为了给超图计算提供更充分的语义层次信息。HyperC2Net颈部网络引入了超图理论来处理跨层级和跨位置的复杂关联。传统的特征金字塔网络主要通过简单的上采样和下采样来融合不同尺度的特征,而超图计算能够建模更复杂的高阶关系,使得网络能够理解特征之间的深层语义关联。最终输出的三个尺度特征 { N 3 , N 4 , N 5 } \{N_3, N_4, N_5\} {N3,N4,N5}不再是简单的多尺度表示,而是经过超图高阶关系学习后的语义增强特征,这些特征包含了更丰富的上下文信息和结构关系,从而能够更好地支持复杂场景下的目标检测任务。
Fig. 2. Illustration of the proposed Mixed Aggregation Network (MANet).
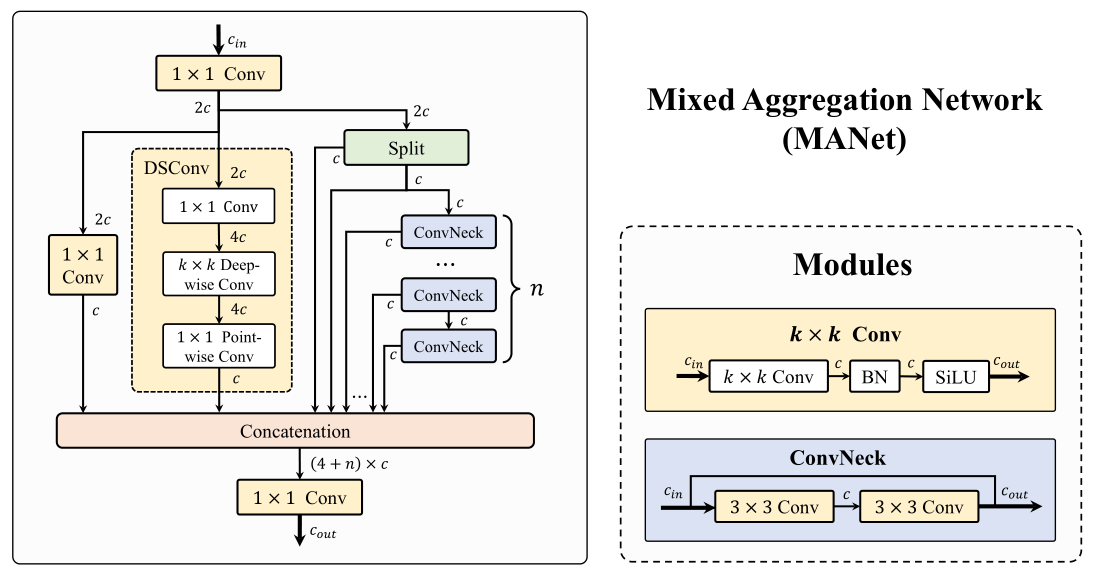
【翻译】图2. 所提出的混合聚合网络(MANet)的示意图。
Fig. 3. Illustration of hypergraph construction.

【翻译】图3. 超图构建的示意图。
C. Mixed Aggregation Network
As for the backbone of our Hyper-YOLO, to augment the feature extraction prowess of the foundational network, we devise the Mixed Aggregation Network (MANet), as shown in fig. 2. This architecture synergistically blends three typical convolutional variants: the 1 × 1 1\times1 1×1 bypass convolution for channel-wise feature recalibration, the Depthwise Separable Convolution (DSConv) for efficient spatial feature processing, and the C2f module for enhancing feature hierarchy integration. This confluence produces a more variegated and rich gradient flow during the training phase, which significantly amplifies the semantic depth encapsulated within the base features at each of the five pivotal stages. Our MANet can be formulated as follows:
【翻译】关于我们Hyper-YOLO的骨干网络,为了增强基础网络的特征提取能力,我们设计了混合聚合网络(MANet),如图2所示。该架构协同地融合了三种典型的卷积变体:用于通道级特征重校准的 1 × 1 1\times1 1×1旁路卷积、用于高效空间特征处理的深度可分离卷积(DSConv),以及用于增强特征层次集成的C2f模块。这种融合在训练阶段产生了更加多样化和丰富的梯度流,显著放大了五个关键阶段中每个阶段基础特征所封装的语义深度。我们的MANet可以表述如下:
X mid = Conv 1 ( X in ) X 1 = Conv 2 ( X mid ) X 2 = DSConv ( Conv 3 ( X mid ) ) X 3 , X 4 = Split ( X mid ) \begin{align*} \boldsymbol{X}_{\text{mid}} &= \text{Conv}_1(\boldsymbol{X}_{\text{in}}) \\ \boldsymbol{X}_1 &= \text{Conv}_2(\boldsymbol{X}_{\text{mid}}) \\ \boldsymbol{X}_2 &= \text{DSConv}(\text{Conv}_3(\boldsymbol{X}_{\text{mid}})) \\ \boldsymbol{X}_3, \boldsymbol{X}_4 &= \text{Split}(\boldsymbol{X}_{\text{mid}}) \end{align*} XmidX1X2X3,X4=Conv1(Xin)=Conv2(Xmid)=DSConv(Conv3(Xmid))=Split(Xmid)
X 5 = ConvNeck 1 ( X 4 ) + X 4 X 6 = ConvNeck 2 ( X 5 ) + X 5 ⋮ X 4 + n = ConvNeck n ( X 3 + n ) + X 3 + n } n \left. \begin{aligned} \boldsymbol{X}_5 &= \text{ConvNeck}_1(\boldsymbol{X}_4) + \boldsymbol{X}_4 \\ \boldsymbol{X}_6 &= \text{ConvNeck}_2(\boldsymbol{X}_5) + \boldsymbol{X}_5 \\ &\vdots \\ \boldsymbol{X}_{4+n} &= \text{ConvNeck}_n(\boldsymbol{X}_{3+n}) + \boldsymbol{X}_{3+n} \end{aligned} \right\} n X5X6X4+n=ConvNeck1(X4)+X4=ConvNeck2(X5)+X5⋮=ConvNeckn(X3+n)+X3+n⎭ ⎬ ⎫n
where the channel number of X m i d X_{m i d} Xmid is 2 c 2c 2c . Whereas each of X 1 , X 2 , … , X 4 + n \mathbf{X}_{1},\mathbf{X}_{2},\ldots,\mathbf{X}_{4+n} X1,X2,…,X4+n features a channel count of c c c . Finally, we fuse and compress the semantic information of the three types of features through a concatenation operation followed by a 1 × 1 1\times1 1×1 convolution to generate the X o u t X_{o u t} Xout with channel number 2 c 2c 2c , as follows:
【翻译】其中 X m i d X_{mid} Xmid的通道数为 2 c 2c 2c。而 X 1 , X 2 , … , X 4 + n \mathbf{X}_{1},\mathbf{X}_{2},\ldots,\mathbf{X}_{4+n} X1,X2,…,X4+n中的每一个特征都具有 c c c个通道。最后,我们通过连接操作将三种类型特征的语义信息进行融合和压缩,然后通过 1 × 1 1\times1 1×1卷积生成通道数为 2 c 2c 2c的 X o u t X_{out} Xout,如下所示:
X o u t = Conv o ( X 1 ∣ ∣ X 2 ∣ ∣ ⋅ ⋅ ⋅ ∣ ∣ X 4 + n ) X_{o u t}=\operatorname{Conv}_{o}(X_{1}||X_{2}||\cdot\cdot\cdot||X_{4+n}) Xout=Convo(X1∣∣X2∣∣⋅⋅⋅∣∣X4+n)
D. Hypergraph-Based Cross-Level and Cross-Position Representation Network
As for the neck of our Hyper-YOLO, in this subsection, to comprehensively fuse that cross-level and cross-position information from the backbone, we further propose the hypergraphbased cross-level and cross-position representation network (HyperC2Net), as shown in fig. 4. HyperC2Net is an implementation of the proposed HGC-SCS framework, which is able to capture those potential high-order correlations in the semantic space.
【翻译】关于我们Hyper-YOLO的颈部网络,在本小节中,为了全面融合来自骨干网络的跨层级和跨位置信息,我们进一步提出了基于超图的跨层级和跨位置表示网络(HyperC2Net),如图4所示。HyperC2Net是所提出的HGC-SCS框架的一个实现,能够捕获语义空间中的潜在高阶关联。
【解析】HyperC2Net同时处理跨层级(不同深度的特征层)和跨位置(特征图上不同空间位置)的信息交互。HGC-SCS框架是实现这种复杂信息交互的理论基础,它利用超图计算来建模这些高阶关系,使得网络能够理解特征之间更深层次的语义关联。
Fig. 4. Illstration of the proposed Hypergraph-Based Cross-Level and Cross-Position Representation Network (HyperC2Net).
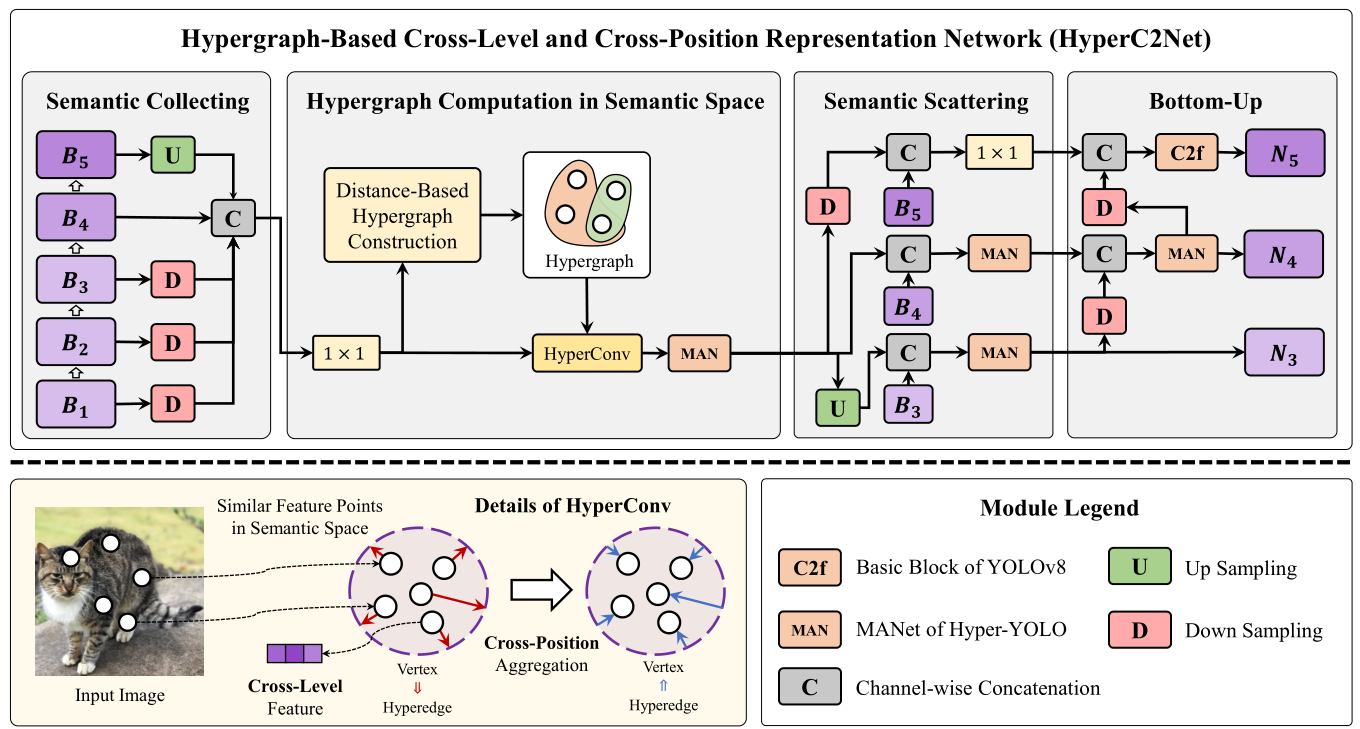
【翻译】图4. 所提出的基于超图的跨层级和跨位置表示网络(HyperC2Net)的示意图。
- Hypergraph Construction.: As illustrated in fig. S1, our backbone is segmented into five discrete stages. The feature maps from these stages are represented as { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_{1},B_{2},B_{3},B_{4},B_{5}\} {B1,B2,B3,B4,B5} . In an effort to harness hypergraph computation for elucidating the intricate high-order relationships among foundational features, we initiate the process by executing a channel-wise concatenation of the quintet of base features, thereby synthesizing cross-level visual features. A hypergraph G = { V , E } \mathcal{G}=\{\mathcal{V},\mathcal{E}\} G={V,E} is conventionally defined by its vertex set ν \nu ν and hyperedge set E \mathcal{E} E . In our approach, we deconstruct the grid-based visual features to constitute the vertex set ν \nu ν of a hypergraph. To model the neighborhood relationships within the semantic space, a distance threshold is used to construct an ϵ \epsilon ϵ -ball from each feature point, which will serve as a hyperedge, as illustrated fig. 3. An ϵ \epsilon ϵ -ball is a hyperedge that encompasses all feature points within a certain distance threshold from a central feature point. The construction of the overall hyperedge set can be defined as E = { b a l l ( v , ϵ ) ∣ v ∈ V } \mathcal{E}~=~\{b a l l(v,\epsilon)~|~v~\in~\mathcal{V}\} E = {ball(v,ϵ) ∣ v ∈ V} , where b a l l ( v , ϵ ) = { u ∣ ∣ ∣ x u − x v ∣ ∣ d < ϵ , u ∈ V } b a l l(v,\epsilon)~=~\{u~|~||\pmb{x}_{u}~-\pmb{x}_{v}||_{d}~<~\epsilon,u~\in~\mathcal{V}\} ball(v,ϵ) = {u ∣ ∣∣xu −xv∣∣d < ϵ,u ∈ V} indicate the neighbor vertex set of the specified vertex v v v . ∣ ∣ x − y ∣ ∣ d ||x-y||_{d} ∣∣x−y∣∣d is the distance function. In computations, a hypergraph G \mathcal{G} G is commonly represented by its incidence matrix H _{H} H .
【翻译】1) 超图构建:如图S1所示,我们的骨干网络被分割成五个离散阶段。来自这些阶段的特征图表示为 { B 1 , B 2 , B 3 , B 4 , B 5 } \{B_{1},B_{2},B_{3},B_{4},B_{5}\} {B1,B2,B3,B4,B5}。为了利用超图计算来阐明基础特征之间复杂的高阶关系,我们通过对五个基础特征执行通道级连接来启动这个过程,从而合成跨层级视觉特征。超图 G = { V , E } \mathcal{G}=\{\mathcal{V},\mathcal{E}\} G={V,E}通常由其顶点集 ν \nu ν和超边集 E \mathcal{E} E定义。在我们的方法中,我们将基于网格的视觉特征解构为超图的顶点集 ν \nu ν。为了建模语义空间内的邻域关系,使用距离阈值从每个特征点构建 ϵ \epsilon ϵ-球,这将作为一个超边,如图3所示。 ϵ \epsilon ϵ-球是一个超边,包含距离中心特征点一定距离阈值内的所有特征点。整体超边集的构建可以定义为 E = { b a l l ( v , ϵ ) ∣ v ∈ V } \mathcal{E}~=~\{b a l l(v,\epsilon)~|~v~\in~\mathcal{V}\} E = {ball(v,ϵ) ∣ v ∈ V},其中 b a l l ( v , ϵ ) = { u ∣ ∣ ∣ x u − x v ∣ ∣ d < ϵ , u ∈ V } b a l l(v,\epsilon)~=~\{u~|~||\pmb{x}_{u}~-\pmb{x}_{v}||_{d}~<~\epsilon,u~\in~\mathcal{V}\} ball(v,ϵ) = {u ∣ ∣∣xu −xv∣∣d < ϵ,u ∈ V}表示指定顶点 v v v的邻居顶点集。 ∣ ∣ x − y ∣ ∣ d ||x-y||_{d} ∣∣x−y∣∣d是距离函数。在计算中,超图 G \mathcal{G} G通常由其关联矩阵 H _{H} H表示。
【解析】超图构建是HyperC2Net的第一个关键步骤。想象一下传统的图就像一个城市的道路网络,每个路口是顶点,道路是边,一条边只能连接两个路口。而超图则像是一个更复杂的交通网络,其中超边可以同时连接多个路口,就像一条地铁线可以同时服务多个站点。在这里,骨干网络的五个阶段产生的特征图首先被通道级连接,这相当于将不同层次的信息汇聚到一个统一的语义空间中。然后,原本规整的网格特征被重新组织成超图的顶点。每个 ϵ \epsilon ϵ-球超边的构建基于语义距离而非空间位置,在语义上相似的特征点会被连接在一起,即使它们在原始特征图中的空间位置相距较远。 b a l l ( v , ϵ ) b a l l(v,\epsilon) ball(v,ϵ)定义了以顶点 v v v为中心、半径为 ϵ \epsilon ϵ的语义邻域,这种基于语义相似性的连接方式使得网络能够捕获跨空间位置的高阶关系。
- Hypergraph Convolution.: To facilitate high-order message passing on the hypergraph structure, we utilize a typical spatial-domain hypergraph convolution [18] with extra residual connection to perform high-order learning on vertex features as follows:
【翻译】2) 超图卷积:为了促进超图结构上的高阶消息传递,我们利用典型的空间域超图卷积[18]并添加额外的残差连接来对顶点特征执行高阶学习,如下所示:
【解析】与传统的图卷积只能在直接相连的节点间传递信息不同,超图卷积允许信息在超边内的所有节点间同时传播。一个超边内的所有特征点都可以同时参与信息交换。残差连接的加入确保了原始特征信息不会在高阶学习过程中丢失,保持特征的完整性和网络的训练稳定。
{ x e = 1 ∣ N v ( e ) ∣ ∑ v ∈ N v ( e ) x v Θ x v ′ = x v + 1 ∣ N e ( v ) ∣ ∑ e ∈ N e ( v ) x e \left\{\begin{array}{l l}{\pmb{x}_{e}=\displaystyle\frac{1}{|\mathcal{N}_{v}(e)|}\sum_{v\in\mathcal{N}_{v}(e)}\pmb{x}_{v}\Theta}\\\ {\pmb{x}_{v}^{\prime}=\pmb{x}_{v}+\displaystyle\frac{1}{|\mathcal{N}_{e}(v)|}\sum_{e\in\mathcal{N}_{e}(v)}\pmb{x}_{e}}\end{array}\right. ⎩ ⎨ ⎧xe=∣Nv(e)∣1v∈Nv(e)∑xvΘ xv′=xv+∣Ne(v)∣1e∈Ne(v)∑xe
where N v ( e ) \mathcal{N}_{v}(e) Nv(e) and N e ( v ) \mathcal{N}_{e}(v) Ne(v) are two neighbor indicate functions, as defined in [18]: N v ( e ) = { v ∣ v ∈ e , v ∈ V } \mathcal{N}_{v}(e)~=~\{v~|~v~\in~e,v~\in~\mathcal{V}\} Nv(e) = {v ∣ v ∈ e,v ∈ V} and N e ( v ) = { e ∣ v ∈ e , e ∈ E } \mathcal{N}_{e}(v)=\{e\mid v\in e,e\in\mathcal{E}\} Ne(v)={e∣v∈e,e∈E} . Θ \Theta Θ is a trainable parameter. For computational convenience, the matrix formulation of the two-stage hypergraph message passing can be defined as:
【翻译】其中 N v ( e ) \mathcal{N}_{v}(e) Nv(e)和 N e ( v ) \mathcal{N}_{e}(v) Ne(v)是两个邻居指示函数,如[18]中定义: N v ( e ) = { v ∣ v ∈ e , v ∈ V } \mathcal{N}_{v}(e)~=~\{v~|~v~\in~e,v~\in~\mathcal{V}\} Nv(e) = {v ∣ v ∈ e,v ∈ V}和 N e ( v ) = { e ∣ v ∈ e , e ∈ E } \mathcal{N}_{e}(v)=\{e\mid v\in e,e\in\mathcal{E}\} Ne(v)={e∣v∈e,e∈E}。 Θ \Theta Θ是可训练参数。为了计算方便,两阶段超图消息传递的矩阵形式可以定义为:
【解析】这些邻居指示函数定义了超图中的连接关系。 N v ( e ) \mathcal{N}_{v}(e) Nv(e)表示超边 e e e包含的所有顶点,而 N e ( v ) \mathcal{N}_{e}(v) Ne(v)表示包含顶点 v v v的所有超边。超图卷积的两阶段过程实现了复杂的信息聚合:第一阶段,每个超边通过对其包含的所有顶点特征进行加权平均来计算超边特征;第二阶段,每个顶点通过聚合其参与的所有超边信息来更新自身特征,同时保留原始特征。这种双向信息流动机制使得每个特征点都能感知到与其语义相关的所有其他特征点的信息,实现了真正的高阶关系建模。
H y p e r C o n v ( X , H ) = X + D v − 1 H D e − 1 H ⊤ X Θ \mathrm{HyperConv}(X,H)=X+D_{v}^{-1}H D_{e}^{-1}H^{\top}X\Theta HyperConv(X,H)=X+Dv−1HDe−1H⊤XΘ
where D v D_{v} Dv and D e D_{e} De represent the diagonal degree matrices of the vertices and hyperedges, respectively.
【翻译】其中 D v D_{v} Dv和 D e D_{e} De分别表示顶点和超边的对角度矩阵。
【解析】总结了超图卷积过程。 D v − 1 D_{v}^{-1} Dv−1和 D e − 1 D_{e}^{-1} De−1是归一化因子,确保了不同度数的顶点和超边得到公平的处理。 H H H是关联矩阵, H ⊤ H^{\top} H⊤是其转置,它们共同实现了从顶点到超边再到顶点的信息传递路径。超图卷积的核心思想:通过超边作为中介,实现顶点间的高阶信息交互,同时通过残差连接( X + X+ X+部分)保持原始信息。
- An Instance of HGC-SCS Framework.: By combining the previously defined hypergraph construction and convolution strategies, we introduce a streamlined instantiation of the HGC-SCS framework, termed hypergraph-based crosslevel and cross-position representation network (HyperC2Net), whose overarching definition is as follows:
【翻译】3) HGC-SCS框架的一个实例:通过结合之前定义的超图构建和卷积策略,我们引入了HGC-SCS框架的一个简化实例,称为基于超图的跨层级和跨位置表示网络(HyperC2Net),其总体定义如下:
【解析】这里将前面介绍的超图构建和超图卷积技术整合成完整的HyperC2Net网络。HyperC2Net作为颈部网络,将骨干网络提取的多层次特征进行高阶融合。
{ X mixed = B 1 ∥ B 2 ∥ B 3 ∥ B 4 ∥ B 5 X hyper = HyperConv ( X mixed , H ) N 3 , N 4 , N 5 = ϕ ( X hyper , B 3 ) , ϕ ( X hyper , B 4 ) , ϕ ( X hyper , B 4 ) \begin{equation} \begin{cases} \boldsymbol{X}_{\text{mixed}} = \boldsymbol{B}_1 \parallel \boldsymbol{B}_2 \parallel \boldsymbol{B}_3 \parallel \boldsymbol{B}_4 \parallel \boldsymbol{B}_5 \\ \boldsymbol{X}_{\text{hyper}} = \text{HyperConv}(\boldsymbol{X}_{\text{mixed}}, \boldsymbol{H}) \\ \boldsymbol{N}_3, \boldsymbol{N}_4, \boldsymbol{N}_5 = \phi(\boldsymbol{X}_{\text{hyper}}, \boldsymbol{B}_3), \phi(\boldsymbol{X}_{\text{hyper}}, \boldsymbol{B}_4), \phi(\boldsymbol{X}_{\text{hyper}}, \boldsymbol{B}_4) \end{cases} \end{equation} ⎩ ⎨ ⎧Xmixed=B1∥B2∥B3∥B4∥B5Xhyper=HyperConv(Xmixed,H)N3,N4,N5=ϕ(Xhyper,B3),ϕ(Xhyper,B4),ϕ(Xhyper,B4)
where · ∣ ∣ || ∣∣· denotes the matrix concatenation operation. ϕ \phi ϕ is the fusion function as illustrated in fig. 4 (semantic scattering module and bottom-up module). In our HyperC2Net, X m i x e d X_{m i x e d} Xmixed intrinsically contains cross-level information, as it is a fusion of backbone features from multiple levels. Additionally, by deconstructing grid features into a set of feature points within the semantic space and constructing hyperedges based on distances, our approach permits high-order message passing among vertices at varying positions within the point set. This capability facilitates the capture of cross-position information, enriching the model’s understanding of the semantic space.
【翻译】其中· ∣ ∣ || ∣∣·表示矩阵连接操作。 ϕ \phi ϕ是如图4所示的融合函数(语义散射模块和自底向上模块)。在我们的HyperC2Net中, X m i x e d X_{mixed} Xmixed本质上包含跨层级信息,因为它是来自多个层级的骨干特征的融合。此外,通过将网格特征解构为语义空间内的一组特征点并基于距离构建超边,我们的方法允许在点集内不同位置的顶点之间进行高阶消息传递。这种能力促进了跨位置信息的捕获,丰富了模型对语义空间的理解。
【解析】第一步,五个不同层级的骨干特征通过连接操作融合成 X m i x e d X_{mixed} Xmixed,这实现跨层级信息的初步整合。第二步,通过超图卷积对融合特征进行高阶关系学习,得到 X h y p e r X_{hyper} Xhyper。第三步,通过融合函数 ϕ \phi ϕ将高阶学习后的特征与原始骨干特征结合,生成最终的三个尺度输出特征。整个过程既保证了跨层级信息的有效融合,又通过超图计算实现了跨位置的高阶关系建模。值得注意的是,这种设计打破了传统网络只能处理局部邻域关系的限制,使得任意两个语义相关的特征点都可以直接进行信息交互,从而极大地增强了特征表示的丰富性和表达能力。
E. Comparison and Analysis
Advancements in the YOLO series mainly concentrate on refinements to the backbone and neck components, with a specific focus on the backbone as a pivotal element of evolution with each successive YOLO iteration. For instance, the seminal YOLO [1] framework introduced the DarkNet backbone, which has since undergone a series of enhancements, as exemplified by the ELAN (Efficient Layer Aggregation Network) module introduced in YOLOv7 [7] and the C2f (Cross Stage Partial Connections with Feedback) module unveiled in YOLOv8 [8]. These innovations have critically promoted the visual feature extraction prowess of the backbone architecture.
【翻译】YOLO系列的发展主要集中在对骨干网络和颈部组件的改进上,特别是将骨干网络作为每一代YOLO迭代演进的关键要素。例如,开创性的YOLO[1]框架引入了DarkNet骨干网络,此后经历了一系列增强,如YOLOv7[7]中引入的ELAN(高效层聚合网络)模块和YOLOv8[8]中推出的C2f(带反馈的跨阶段部分连接)模块。这些创新极大地提升了骨干架构的视觉特征提取能力。
In contrast, our Hyper-YOLO model pivots the innovation axis towards the neck component’s design. In the realm of neck architecture, leading-edge iterations such as YOLOv6 [5], YOLOv7 [7], and YOLOv8 [8] have consistently incorporated the PANet [16] (Path Aggregation Network) structure. Simultaneously, Gold-YOLO [10] has adopted an inventive gather-distribute neck paradigm. In the following, we will compare HyperYOLO’s HyperC2Net with these two classical neck architectures.
【翻译】相比之下,我们的Hyper-YOLO模型将创新轴心转向颈部组件的设计。在颈部架构领域,诸如YOLOv6[5]、YOLOv7[7]和YOLOv8[8]等前沿迭代版本一直采用PANet[16](路径聚合网络)结构。同时,Gold-YOLO[10]采用了创新的收集-分发颈部范式。下面,我们将比较HyperYOLO的HyperC2Net与这两种经典颈部架构。
The PANet architecture, despite its efficacy in fusing multiscale features via top-down and bottom-up pathways, remains constrained to the fusion of information across immediately contiguous layers. This adjacency-bound fusion modality inherently restricts the breadth of information integration within the network. HyperC2Net, on the other hand, transcends this limitation by enabling direct fusion across the quintuple levels of features emanating from the backbone. This approach engenders a more robust and diversified information flow, curtailing the connectivity gap between features of varying depths. Notably, while the gather-distribute neck mechanism introduced by Gold-YOLO exhibits the capacity to assimilate information across multiple levels, it does not inherently account for cross-positional interactions within the feature maps. The ingenuity of HyperC2Net lies in its utilization of hypergraph computations to capture the intricate highorder associations latent within feature maps. The hypergraph convolutions in the semantic domain facilitate a non-gridconstrained flow of information, empowering both crosslevel and cross-positional high-order information propagation. Such a mechanism breaks the constrain of conventional grid structures, enabling a more nuanced and integrated feature representation.
【翻译】PANet架构尽管在通过自顶向下和自底向上路径融合多尺度特征方面具有有效性,但仍然局限于相邻层之间的信息融合。这种基于邻接性的融合模式本质上限制了网络内信息整合的广度。另一方面,HyperC2Net通过实现来自骨干网络的五个层级特征的直接融合来超越这一限制。这种方法产生了更强大和多样化的信息流,缩小了不同深度特征之间的连接间隙。值得注意的是,虽然Gold-YOLO引入的收集-分发颈部机制展现了跨多个层级吸收信息的能力,但它并未本质上考虑特征图内的跨位置交互。HyperC2Net的独创性在于利用超图计算来捕获特征图中潜在的复杂高阶关联。语义域中的超图卷积促进了非网格约束的信息流,实现了跨层级和跨位置的高阶信息传播。这种机制打破了传统网格结构的约束,实现了更加细致和集成的特征表示。
The feature representations generated by HyperC2Net reflect a comprehensive consideration of both the semantic features provided by the original data backbone and the potential high-order structural features. Such an enriched feature representation is instrumental in achieving superior performance in object detection tasks. The ability of HyperC2Net to harness these intricate high-order relationships offers a significant advantage over conventional neck architectures like PANet and even recent innovations like the gather-distribute neck, underscoring the value of high-order feature processing in advancing the state-of-the-art in computer vision.
【翻译】HyperC2Net生成的特征表示反映了对原始数据骨干网络提供的语义特征和潜在高阶结构特征的综合考虑。这种丰富的特征表示对于在目标检测任务中实现优越性能具有重要意义。HyperC2Net利用这些复杂高阶关系的能力相比传统颈部架构(如PANet)甚至最近的创新(如收集-分发颈部)提供了显著优势,强调了高阶特征处理在推进计算机视觉领域最新技术方面的价值。
V. EXPERIMENTS
A. Experimental Setup
- Datasets: The Microsoft COCO dataset [41], a benchmark for object detection, is employed to assess the efficacy of the proposed Hyper-YOLO model. In particular, the Train2017 subset is utilized for training purposes, while the Val2017 subset serves as the validation set. The performance evaluation of Hyper-YOLO is carried out on the Val2017 subset, with the results detailed in table I.
【翻译】1) 数据集:采用Microsoft COCO数据集[41]这一目标检测基准来评估所提出的Hyper-YOLO模型的有效性。具体而言,Train2017子集用于训练目的,而Val2017子集作为验证集。Hyper-YOLO的性能评估在Val2017子集上进行,结果详见表I。
- Compared Methods: We select those advanced YOLO series methods, including YOLOv5 [4], YOLOv6-3.0 [5], YOLOv7 [7], YOLOv8 [8], Gold-YOLO [10], and YOLOv9 [21] for comparison. The default parameter configurations of their reported are adopted in our experiments.
【翻译】2) 对比方法:我们选择了先进的YOLO系列方法进行比较,包括YOLOv5[4]、YOLOv6-3.0[5]、YOLOv7[7]、YOLOv8[8]、Gold-YOLO[10]和YOLOv9[21]。在我们的实验中采用了它们报告的默认参数配置。
- Our Hyper-YOLO Methods: Our Hyper-YOLO is developed based on the four scales of YOLOv8 (-N, -S, -M, -L). Therefore, we modified the hyperparameters (number of convolutional layers, feature dimensions) for each stage of the Hyper-YOLO architecture, as shown in table S2, resulting in Hyper-YOLO-N, Hyper-YOLO-S, Hyper-YOLOM, and Hyper-YOLO-L. Considering that our Hyper-YOLO introduces high-order learning in the neck, which increases the number of parameters, we further reduced the parameters on the basis of Hyper-YOLO-N to form Hyper-YOLO-T. Specifically, in Hyper-YOLO-T’s HyperC2Net, the last C2f in the Bottom-Up stage is replaced with a 1 × 1 1\times1 1×1 convolution. Additionally, we noted that the latest YOLOv9 employs a new programmable gradient information transmission and prunes paths during inference to reduce parameters while maintaining accuracy. Based on YOLOv9, we developed HyperYOLOv1.1. Specifically, we replaced the neck of YOLOv9 with the HyperC2Net from Hyper-YOLO, thereby endowing YOLOv9 with the capability of high-order learning.
【翻译】3) 我们的Hyper-YOLO方法:我们的Hyper-YOLO基于YOLOv8的四个尺度(-N、-S、-M、-L)开发。因此,我们修改了Hyper-YOLO架构每个阶段的超参数(卷积层数量、特征维度),如表S2所示,从而得到Hyper-YOLO-N、Hyper-YOLO-S、Hyper-YOLO-M和Hyper-YOLO-L。考虑到我们的Hyper-YOLO在颈部引入了高阶学习,这增加了参数数量,我们在Hyper-YOLO-N的基础上进一步减少参数以形成Hyper-YOLO-T。具体而言,在Hyper-YOLO-T的HyperC2Net中,自底向上阶段的最后一个C2f被替换为 1 × 1 1\times1 1×1卷积。此外,我们注意到最新的YOLOv9采用了新的可编程梯度信息传输,并在推理期间修剪路径以在保持准确性的同时减少参数。基于YOLOv9,我们开发了HyperYOLOv1.1。具体而言,我们用来自Hyper-YOLO的HyperC2Net替换了YOLOv9的颈部,从而赋予YOLOv9高阶学习的能力。
- Other Details: To ensure an equitable comparison, we excluded the use of pre-training and self-distillation strategies for all methods under consideration, as outlined in [5] and [10]. Furthermore, recognizing the potential influence of input image size on the evaluation, we standardized the input resolution across all experiments to 640 × 640 640\times640 640×640 pixels, a common choice in the field. The evaluation is based on the standard COCO Average Precision (AP) metric. Additional implementation specifics are provided in section A and section C.
【翻译】4) 其他细节:为了确保公平比较,我们排除了所有考虑方法中预训练和自蒸馏策略的使用,如[5]和[10]中所述。此外,认识到输入图像尺寸对评估的潜在影响,我们将所有实验的输入分辨率标准化为 640 × 640 640\times640 640×640像素,这是该领域的常见选择。评估基于标准的COCO平均精度(AP)指标。其他实现细节在A节和C节中提供。
B. Results and Discussions
The results of object detection on the COCO Val2017 validation set, as shown in table I, lead to four main observations. Firstly, the proposed Hyper-YOLO method outperforms other models across all four scales. For instance, in terms of the A P v a l \mathrm{AP}^{v a l} APval metric, Hyper-YOLO achieves a performance of 41.8 % 41.8\% 41.8% at the -N scale, 48.0 % 48.0\% 48.0% at the -S scale, 52.0 % 52.0\% 52.0% at the -M scale, and 53.8 % 53.8\% 53.8% at the -L scale. Compared to the
【翻译】如表I所示,在COCO Val2017验证集上的目标检测结果产生了四个主要观察结果。首先,所提出的Hyper-YOLO方法在所有四个尺度上都优于其他模型。例如,在 A P v a l \mathrm{AP}^{v a l} APval指标方面,Hyper-YOLO在-N尺度上达到 41.8 % 41.8\% 41.8%的性能,在-S尺度上达到 48.0 % 48.0\% 48.0%,在-M尺度上达到 52.0 % 52.0\% 52.0%,在-L尺度上达到 53.8 % 53.8\% 53.8%。与
TABLE I COMPARISON OF STATE-OF-THE-ART YOLO METHODS. THE TERM “#PARA.” REFERS TO THE “NUMBER OF PARAMETER” WITHIN A MODEL. BOTH FRAMES PER SECOND (FPS) AND LATENCY WERE BENCHMARKED UNDER FP16 PRECISION USING A TESLA T4 GPU, CONSISTENT ACROSS ALL MODELS WITH TENSORRT 8.6.1. DURING OUR PRACTICAL SPEED EVALUATIONS, A NOTABLE OBSERVATION WAS THAT TENSORRT DOES NOT FULLY OPTIMIZE THE DISTANCE COMPUTATION (torch.cdist()), A CRUCIAL STEP IN HYPERGRAPH CONSTRUCTION. TO MAINTAIN A FAIR COMPARISON WITH OTHER YOLO VARIANTS, WE PRESENT ADDITIONAL RESULTS THAT ISOLATE IMPROVEMENTS TO THE BACKBONE ARCHITECTURE ALONE, INDICATED BY THE SYMBOL † \dagger † .
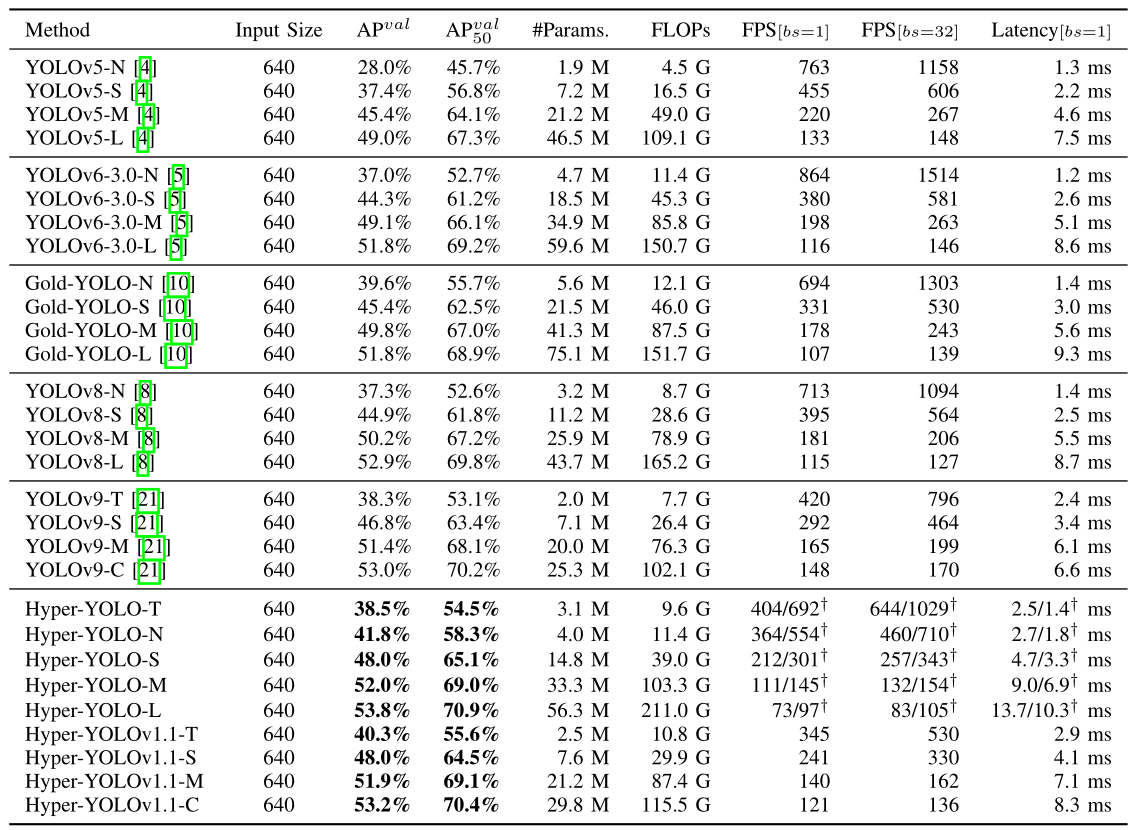
【翻译】表I 最先进YOLO方法的比较。术语"#PARA.“指的是模型内的"参数数量”。每秒帧数(FPS)和延迟都在Tesla T4 GPU上使用FP16精度进行基准测试,所有模型均使用TensorRT 8.6.1保持一致。在我们的实际速度评估中,一个显著的观察是TensorRT没有完全优化距离计算(torch.cdist()),这是超图构建中的关键步骤。为了与其他YOLO变体保持公平比较,我们提供了仅隔离骨干架构改进的额外结果,用符号 † \dagger †表示。
Gold-YOLO, Hyper-YOLO shows an improvement of 2.2, 2.6, 2.2, and 2.0, respectively. When compared to YOLOv8, the improvements are 4.5, 3.1, 1.8, and 0.9, respectively. Compared to the YOLOv9, Hyper-YOLO shows an improvement of 3.5, 1.2, 0.6, and 0.8, respectively. These results validate the effectiveness of the Hyper-YOLO method.
【翻译】Gold-YOLO相比,Hyper-YOLO分别显示了2.2、2.6、2.2和2.0的改进。与YOLOv8相比,改进分别为4.5、3.1、1.8和0.9。与YOLOv9相比,Hyper-YOLO分别显示了3.5、1.2、0.6和0.8的改进。这些结果验证了Hyper-YOLO方法的有效性。
Secondly, it is noteworthy that our method not only improves performance over Gold-YOLO but also reduces the number of parameters significantly. Specifically, there is a reduction of 28 % 28\% 28% at the − N \mathbf{-N} −N scale, 31 % 31\% 31% at the -S scale, 19 % 19\% 19% at the -M scale, and 25 % 25\% 25% at the − L -\mathrm{L} −L scale. The main reason for this is our HGC-SCS framework, which further introducs highorder learning in the semantic space comapred with the GoldYOLO’s gather-distribute mechanism. This allows our method to utilize the diverse information extracted by the backbone, including cross-level and cross-position information, more efficiently with fewer parameters.
【翻译】其次,值得注意的是,我们的方法不仅在性能上超越了Gold-YOLO,还显著减少了参数数量。具体而言,在 − N \mathbf{-N} −N尺度上减少了 28 % 28\% 28%,在-S尺度上减少了 31 % 31\% 31%,在-M尺度上减少了 19 % 19\% 19%,在 − L -\mathrm{L} −L尺度上减少了 25 % 25\% 25%。这主要归因于我们的HGC-SCS框架,与Gold-YOLO的收集-分发机制相比,它在语义空间中进一步引入了高阶学习。这使得我们的方法能够用更少的参数更高效地利用骨干网络提取的多样化信息,包括跨层级和跨位置信息。
Thirdly, considering that Hyper-YOLO shares a similar underlying architecture with YOLOv8, we found that the proposed Hyper-YOLO-T, compared to YOLOv8-N, achieved higher object detection performance 37.3 → 38.5 37.3\to38.5 37.3→38.5 in terms of A P v a l , A P^{\mathrm{val}}, APval, ) with fewer parameters 3.2 M → 3.1 M ) 3.2\mathbf{M}\to3.1\mathbf{M}) 3.2M→3.1M) . This demonstrates that the proposed HyperC2Net can achieve better feature representation learning through high-order learning, thereby enhancing detection performance. Similarly, we compared Hyper-YOLOv1.1 with YOLOv9, as both use the same backbone architecture, with the only difference being that Hyper-YOLOv1.1 employs the hypergraph-based HyperC2Net as the neck. The results show that our Hyper-YOLOv1.1 demonstrated significant performance improvements: HyperYOLOv1.1-T outperformed YOLOv9-T by 2.0 A P v a l 2.0\mathrm{AP}^{v a l} 2.0APval , and Hyper-YOLOv1.1-S outperformed YOLOv9-S by 1.2 APval. This fair comparison using the same architecture at the same scale validates the effectiveness of the proposed high-order learning method in object detection tasks.
【翻译】第三,考虑到Hyper-YOLO与YOLOv8共享相似的底层架构,我们发现所提出的Hyper-YOLO-T相比YOLOv8-N,在 A P v a l A P^{\mathrm{val}} APval方面实现了更高的目标检测性能 37.3 → 38.5 37.3\to38.5 37.3→38.5,同时参数更少 3.2 M → 3.1 M 3.2\mathbf{M}\to3.1\mathbf{M} 3.2M→3.1M。这表明所提出的HyperC2Net可以通过高阶学习实现更好的特征表示学习,从而提高检测性能。类似地,我们将Hyper-YOLOv1.1与YOLOv9进行比较,因为两者使用相同的骨干架构,唯一的区别是Hyper-YOLOv1.1采用基于超图的HyperC2Net作为颈部。结果显示我们的Hyper-YOLOv1.1表现出显著的性能改进:HyperYOLOv1.1-T在 2.0 A P v a l 2.0\mathrm{AP}^{v a l} 2.0APval上超越了YOLOv9-T,Hyper-YOLOv1.1-S在1.2 APval上超越了YOLOv9-S。这种在相同尺度使用相同架构的公平比较验证了所提出的高阶学习方法在目标检测任务中的有效性。
Finally, we observe that, compared to YOLOv8, the improvements brought by our Hyper-YOLO become more significant (from 0.9 to 4.5) as the model scale decreases (from -L to − N ϵ -\mathbf{N}_{\mathbf{\epsilon}} −Nϵ ). This is because a smaller model scale weakens the feature extraction capability and the ability to obtain effective information from visual data. At this point, high-order learning becomes necessary to capture the latent high-order correlations in the semantic space of the feature map, enriching the features ultimately used for the detection head. Furthermore, high-order message propagation based on hypergraphs in the semantic space allows direct information flow between different positions and levels, enhancing the feature extraction capability of the base network with limited parameters.
【翻译】最后,我们观察到,与YOLOv8相比,随着模型尺度的减小(从-L到 − N ϵ -\mathbf{N}_{\mathbf{\epsilon}} −Nϵ),我们的Hyper-YOLO带来的改进变得更加显著(从0.9到4.5)。这是因为较小的模型尺度削弱了特征提取能力和从视觉数据中获取有效信息的能力。此时,高阶学习变得必要,以捕获特征图语义空间中的潜在高阶相关性,丰富最终用于检测头的特征。此外,基于超图在语义空间中的高阶消息传播允许不同位置和层级之间的直接信息流,在有限参数下增强基础网络的特征提取能力。
C. Ablation Studies on Backbone
In this and the next subsection, taking into account the model’s scale, we select the Hyper-YOLO-S to conduct ablation studies on the backbone and neck.
【翻译】在本小节和下一小节中,考虑到模型的规模,我们选择Hyper-YOLO-S来对骨干网络和颈部进行消融研究。
- On Basic Block of Backbone.: We conduct ablation experiments on the proposed MANet to verify the effectiveness of the mixed aggregation mechanism proposed in the basic block, as shown in table II. To ensure a fair comparison, we utilize the same PANet [16] as the neck, used in YOLOv8 [8], so that the only difference between the two methods lies in the basic block. The experimental results clearly show that the proposed MANet outperforms the C2f module under the same neck across all metrics. This superior performance is attributed to the mixed aggregation mechanism, which integrates three classic structures, leading to a richer flow of information and thus demonstrating enhanced performance.
【翻译】1) 骨干网络的基本模块:我们对所提出的MANet进行消融实验,以验证基本模块中提出的混合聚合机制的有效性,如表II所示。为了确保公平比较,我们使用与YOLOv8[8]中相同的PANet[16]作为颈部,因此两种方法之间的唯一区别在于基本模块。实验结果清楚地表明,在相同颈部条件下,所提出的MANet在所有指标上都优于C2f模块。这种优异性能归因于混合聚合机制,它整合了三种经典结构,导致更丰富的信息流,从而展现出增强的性能。
TABLE II ABLATION STUDY ON DIFFERENT BASIC BLOCKS IN THE BACKBONE.
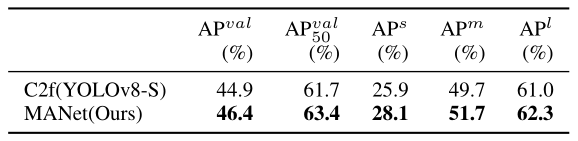
【翻译】表II 骨干网络中不同基本模块的消融研究。
- On Kernel Size of Different Stages.: We further conducted ablation experiments on the size of the convolutional kernels, an essential factor in determining the receptive field and the ability of a network to capture spatial hierarchies in data. In our experiments, k i k_{i} ki represents the kernel size of the i i i-th stage, and we used the same kernel size across all layers within each stage. As shown in table III, the optimal kernel size configuration is [3,5,5,3], which improves the A P v a l A P^{v a l} APval metric by 0.1 compared to using all kernel sizes of 3. This improvement indicates that using larger kernel sizes at the mid-stages benefits the model by enlarging the respective fields. Furthermore, we found that using large kernels (size 5) throughout all stages also improved performance, but the improvement is the same as our preferred setting.
【翻译】2) 不同阶段的卷积核大小:我们进一步对卷积核大小进行了消融实验,这是决定感受野和网络捕获数据中空间层次结构能力的重要因素。在我们的实验中, k i k_{i} ki表示第 i i i阶段的卷积核大小,我们在每个阶段内的所有层中使用相同的卷积核大小。如表III所示,最优的卷积核大小配置是[3,5,5,3],与全部使用大小为3的卷积核相比,在 A P v a l A P^{v a l} APval指标上提高了0.1。这种改进表明,在中间阶段使用较大的卷积核通过扩大相应的感受野对模型有益。此外,我们发现在所有阶段都使用大卷积核(大小为5)也提高了性能,但改进程度与我们首选的设置相同。
TABLE III ABLATION STUDY ON DIFFERENT KERNEL SIZE SETTINGS.
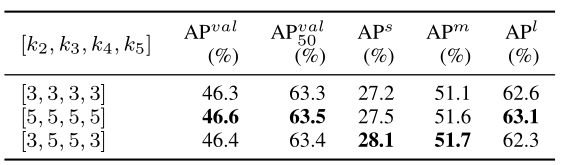
【翻译】表III 不同卷积核大小设置的消融研究。
D. Ablation Studies on Neck
- High-Order vs. Low-Order Learning in HGC-SCS Framework: The core of the HGC-SCS framework lies in the semantic space’s Hypergraph Computation, which allows for high-order information propagation among feature point sets. We conduct ablation studies to evaluate its effectiveness by simplifying the hypergraph into a graph for low-order learning, as shown in table IV. In this case, the graph is constructed by connecting the central node with its neighbors within an ϵ ⋅ \epsilon\cdot ϵ⋅ - ball. The graph convolution operation used [42] is the classic one: A ^ = D ˙ v − 1 / 2 A D v − 1 / 2 + . I \hat{A}=\dot{D}_{v}^{-1/2}A D_{v}^{-1/2}\stackrel{.}{+}I A^=D˙v−1/2ADv−1/2+.I , where D v D_{v} Dv is the diagonal degree matrix of the graph adjacency matrix A \pmb{A} A . Additionally, we include a configuration with no correlation learning at all: “None”. The experimental results, as presented in table IV, reveal that high-order learning demonstrates superior performance compared to the other two methods. Theoretically, loworder learning can be considered a subset [43] of high-order learning but lacks the capability to model complex correlation. High-order learning, on the other hand, possesses a more robust correlation modeling capability, which corresponds with a higher performance ceiling. As a result, it tends to achieve better performance more easily.
【翻译】1) HGC-SCS框架中的高阶与低阶学习:HGC-SCS框架的核心在于语义空间的超图计算,它允许在特征点集之间进行高阶信息传播。我们通过将超图简化为图进行低阶学习来进行消融研究以评估其有效性,如表IV所示。在这种情况下,图是通过将中心节点与其在 ϵ ⋅ \epsilon\cdot ϵ⋅球内的邻居连接来构建的。使用的图卷积操作[42]是经典的: A ^ = D ˙ v − 1 / 2 A D v − 1 / 2 + . I \hat{A}=\dot{D}_{v}^{-1/2}A D_{v}^{-1/2}\stackrel{.}{+}I A^=D˙v−1/2ADv−1/2+.I,其中 D v D_{v} Dv是图邻接矩阵 A \pmb{A} A的对角度矩阵。此外,我们还包括一个完全没有相关性学习的配置:“None”。如表IV所示的实验结果表明,高阶学习相比其他两种方法展现出优越的性能。理论上,低阶学习可以被视为高阶学习的一个子集[43],但缺乏建模复杂相关性的能力。另一方面,高阶学习具有更强的相关性建模能力,这对应着更高的性能上限。因此,它往往更容易实现更好的性能。
TABLE IV ABLATION STUDY ON DIFFERENT ENHANCEMENT STRATEGIES.
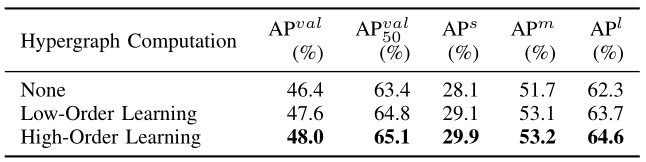
【翻译】表IV 不同增强策略的消融研究。
- On the Semantic Collecting Phase: The first phase of the HGC-SCS framework is Semantic Collecting, which determines the total amount of information fed into the semantic space for hypergraph computation. We performed ablation studies on this phase, as shown in table V, using three different configurations that select 3, 4, or 5 levels of feature maps for input. The experimental results reveal that a greater number of feature maps can bring more abundant semantic space information. This enhanced information richness allows the hypergraph to fully exploit its capability in modeling complex correlation. Consequently, the input configuration with 5 feature maps achieved the best performance. This outcome suggests that the model can benefit from a more comprehensive representation of the input data when more levels of feature maps are integrated. The inclusion of more feature maps likely introduces a broader range of semantic meaning and details from the visual input, enabling the hypergraph to establish higher-order connections that reflect a more complete understanding of the scene. Therefore, the configuration that incorporates 5 feature maps is preferred for maximizing the potential of hypergraph-based complex correlation modeling.
【翻译】2) 语义收集阶段:HGC-SCS框架的第一阶段是语义收集,它决定了输入到语义空间进行超图计算的信息总量。我们对这一阶段进行了消融研究,如表V所示,使用了三种不同的配置,分别选择3、4或5个层次的特征图作为输入。实验结果表明,更多数量的特征图可以带来更丰富的语义空间信息。这种增强的信息丰富性使超图能够充分发挥其在建模复杂相关性方面的能力。因此,具有5个特征图的输入配置取得了最佳性能。这一结果表明,当集成更多层次的特征图时,模型可以从输入数据的更全面表示中受益。包含更多特征图可能会从视觉输入中引入更广泛的语义意义和细节,使超图能够建立反映对场景更完整理解的高阶连接。因此,融合5个特征图的配置被首选用于最大化基于超图的复杂相关性建模的潜力。
TABLE V ABLATION STUDY ON THE NUMBER OF INPUT LEVELS.
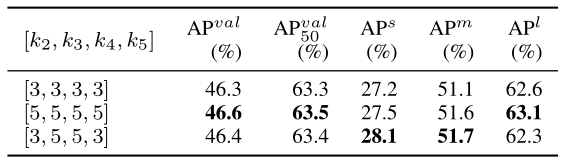
【翻译】表V 输入层次数量的消融研究。
- On Hypergraph Construction of Hypergraph Computation Phase: Further ablation experiments are conducted to examine the effect of the distance threshold used in the construction of the hypergraph, with the results shown in table VI. Compared to the configuration “None” where hypergraph computation is not introduced, the introduction of hypergraph computation leads to a significant overall performance improvement. It is also observed that the performance of the target detection network is relatively stable across a range of threshold values from 7 to 9, with only minor variations. However, there is a performance decline at the thresholds of 6 and 10. This decline can be attributed to the number of connected nodes directly affecting the smoothness of features in the semantic space. A higher threshold may lead to a more connected hypergraph, where nodes are more likely to share information, potentially leading to over-smoothing of the features. Conversely, a lower threshold may result in a less connected hypergraph that cannot fully exploit the highorder relationships among features. Therefore, our HyperYOLO uses the distance threshold 8 for construction. The precise value would be determined based on empirical results, balancing the need for a richly connected hypergraph against the risk of over-smoothing or under-connecting the feature representation.
【翻译】超图计算阶段的超图构建:进一步进行消融实验以检验超图构建中使用的距离阈值的影响,结果如表VI所示。与未引入超图计算的"None"配置相比,引入超图计算导致了显著的整体性能改进。同时观察到,目标检测网络的性能在7到9的阈值范围内相对稳定,仅有轻微变化。然而,在阈值为6和10时出现性能下降。这种下降可归因于连接节点的数量直接影响语义空间中特征的平滑性。较高的阈值可能导致更连通的超图,其中节点更可能共享信息,可能导致特征的过度平滑。相反,较低的阈值可能导致连通性较差的超图,无法充分利用特征之间的高阶关系。因此,我们的HyperYOLO使用距离阈值8进行构建。精确值将基于实验结果确定,平衡对丰富连接超图的需求与特征表示过度平滑或连接不足的风险。
TABLE VI ABLATION STUDY ON THE THRESHOLD OF HYPERGRAPH CONSTRUCTION.
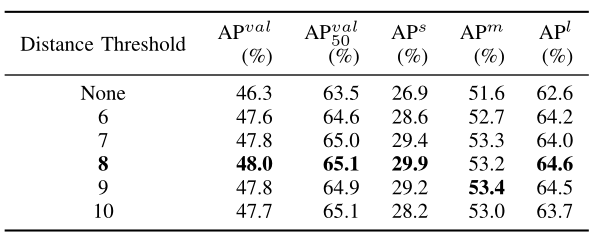
【翻译】表VI 超图构建阈值的消融研究。
E. More Ablation Studies
In this subsection, we conduct thorough ablation studies to assess the impact of backbone and neck enhancements in Hyper-YOLO across four different model scales, with detailed results presented in table VII. The baseline performance of YOLOv8 is placed at the top of the table. The middle part of the table introduces our HyperYOLO models that incorporate only the backbone enhancement. At the bottom, we feature the fully augmented HyperYOLO models, which benefit from both backbone and neck enhancements. Based on experimental results in table VII, we have three observations.
Firstly, the adoption of both individual and combined enhancements significantly boosts performance for the -N, -S, and -M models, validating the effectiveness of our proposed modifications. Secondly, the impact of each enhancement appears to be scale-dependent. As we progress from -N to -S, -M, and -L models, the incremental performance gains due to the backbone improvement gradually decrease from 2.6 to 1.5, 0.8, and finally 0.1. In contrast, the neck enhancement consistently contributes more substantial improvements across these scales, with respective gains of 1.9, 1.6, 1.0, and 0.8.
This suggests that while the benefits of an expanded receptive field and width scaling in the backbone are more pronounced in smaller models, the advanced HyperC2Net neck provides a more uniform enhancement by enriching the semantic content and boosting object detection performance across the board. Thirdly, when focusing on small object detection ( A P s ) (\mathrm{AP}^{s}) (APs) , the HyperYOLO-L model with both backbone and neck enhancements achieves a notable increase of 1.6, whereas just the backbone enhancement leads to a 0.6 improvement. This underscores the potential of hypergraph modeling, particularly within the neck enhancement, to capture the complex relationships among small objects and significantly improve detection in these challenging scenarios.
【翻译】在本小节中,我们进行了全面的消融研究,以评估Hyper-YOLO中骨干网络和颈部增强在四种不同模型规模上的影响,详细结果见表VII。YOLOv8的基线性能位于表格顶部。表格中间部分介绍了仅融合骨干网络增强的HyperYOLO模型。在底部,我们展示了完全增强的HyperYOLO模型,它们受益于骨干网络和颈部的双重增强。基于表VII的实验结果,我们有三个观察结果。
首先,对于-N、-S和-M模型,采用单独和组合增强都显著提升了性能,验证了我们提出的修改的有效性。其次,每种增强的影响似乎依赖于规模。随着我们从-N到-S、-M和-L模型的进展,由于骨干网络改进带来的增量性能收益逐渐从2.6减少到1.5、0.8,最终到0.1。相比之下,颈部增强在这些规模上持续贡献更实质性的改进,相应的收益分别为1.9、1.6、1.0和0.8。
这表明,虽然骨干网络中扩展感受野和宽度缩放的好处在较小模型中更为突出,但先进的HyperC2Net颈部通过丰富语义内容和全面提升目标检测性能提供了更均匀的增强。第三,当专注于小目标检测 ( A P s ) (\mathrm{AP}^{s}) (APs)时,同时具有骨干网络和颈部增强的HyperYOLO-L模型实现了1.6的显著增长,而仅骨干网络增强导致0.6的改进。这凸显了超图建模的潜力,特别是在颈部增强中,能够捕获小目标之间的复杂关系,并在这些具有挑战性的场景中显著改善检测。
F. More Evaluation on Instance Segmentation Task
We extend the application of Hyper-YOLO to the instance segmentation task on the COCO dataset, ensuring a direct comparison with its predecessor, YOLOv8, by adopting a consistent approach in network modification: replacing the detection head with a segmentation head. Experimental results are shown in table VIII.
【翻译】我们将Hyper-YOLO的应用扩展到COCO数据集上的实例分割任务,通过采用一致的网络修改方法:将检测头替换为分割头,确保与其前身YOLOv8进行直接比较。实验结果见表VIII。
The empirical results clearly illustrate that Hyper-YOLO attains remarkable performance enhancements. For APbox, Hyper-YOLO shows an impressive increase of 4.7 A P 4.7\mathrm{AP} 4.7AP for the -N variant, 3.3 AP for the -S variant, 2.2 A P 2.2\mathrm{AP} 2.2AP for the -M variant, and 1.4 A P 1.4~\mathrm{AP} 1.4 AP for the -L variant. Similarly, for A P m a s k \mathrm{AP}^{m a s k} APmask , HyperYOLO exhibits significant improvements, with gains of 3.3 AP for -N, 2.3 AP for -S, 1.3 AP for -M, and 0.7 AP for -L. These results underscore the effectiveness of the advancements integrated into Hyper-YOLO.
【翻译】实验结果清楚地表明,Hyper-YOLO取得了显著的性能提升。对于APbox,Hyper-YOLO在-N变体上显示出令人印象深刻的 4.7 A P 4.7\mathrm{AP} 4.7AP增长,-S变体增长3.3 AP,-M变体增长 2.2 A P 2.2\mathrm{AP} 2.2AP,-L变体增长 1.4 A P 1.4~\mathrm{AP} 1.4 AP。同样,对于 A P m a s k \mathrm{AP}^{m a s k} APmask,HyperYOLO表现出显著改进,-N增长3.3 AP,-S增长2.3 AP,-M增长1.3 AP,-L增长0.7 AP。这些结果强调了集成到Hyper-YOLO中的改进的有效性。
G. Visualization of High-Order Learning in Object Detection
In our paper, we have provided a mathematical rationale explaining how the hypergraph-based neck can transcend the limitations of traditional neck designs, which typically rely on grid-like neighborhood structures for message propagation within feature maps. This design enables advanced highorder message propagation across the semantic spaces of the features. To further substantiate the effectiveness of our hypergraph-based neck, we have included visualizations in the revised manuscript, as shown in fig. 5. These visualizations compare feature maps before and after applying our HyperConv layer. It is evident from these images that there is a consistent reduction in attention to semantically similar backgrounds, such as skies and grounds, while maintaining focus on foreground objects across various scenes. This demonstrates that HyperConv, through hypergraph computations, aids the neck in better recognizing semantically similar objects within an image, thus supporting the detection head in making more consistent decisions.
【翻译】在我们的论文中,我们提供了数学原理,解释了基于超图的颈部如何能够超越传统颈部设计的局限性,传统设计通常依赖于网格状邻域结构在特征图内进行消息传播。这种设计实现了跨特征语义空间的高级高阶消息传播。为了进一步证实我们基于超图的颈部的有效性,我们在修订稿中包含了可视化结果,如图5所示。这些可视化比较了应用我们的HyperConv层前后的特征图。从这些图像中可以明显看出,对语义相似背景(如天空和地面)的关注持续减少,同时在各种场景中保持对前景对象的关注。这表明HyperConv通过超图计算,帮助颈部更好地识别图像内语义相似的对象,从而支持检测头做出更一致的决策。
VI. CONCLUSION
In this paper, we presented Hyper-YOLO, a groundbreaking object detection model that integrates hypergraph computations with the YOLO architecture to harness the potential of high-order correlations in visual data. By addressing the inherent limitations of traditional YOLO models, particularly in the neck design’s inability to effectively integrate features across different levels and exploit high-order relationships, we have significantly advanced the SOTA in object detection. Our contributions set a new benchmark for future research and development in object detection frameworks and pave the way for further exploration into the integration of hypergraph computations within visual architectures based on our HGCCSC framework.
【翻译】在本文中,我们提出了Hyper-YOLO,这是一个突破性的目标检测模型,它将超图计算与YOLO架构相结合,以利用视觉数据中高阶相关性的潜力。通过解决传统YOLO模型的固有局限性,特别是颈部设计无法有效整合不同层次特征和利用高阶关系的问题,我们显著推进了目标检测领域的最新技术水平。我们的贡献为目标检测框架的未来研究和开发设定了新的基准,并为基于我们的HGC-SCS框架在视觉架构中进一步探索超图计算的集成铺平了道路。
TABLE VII ABLATION STUDIES ON DIFFERENT SCALE MODELS.
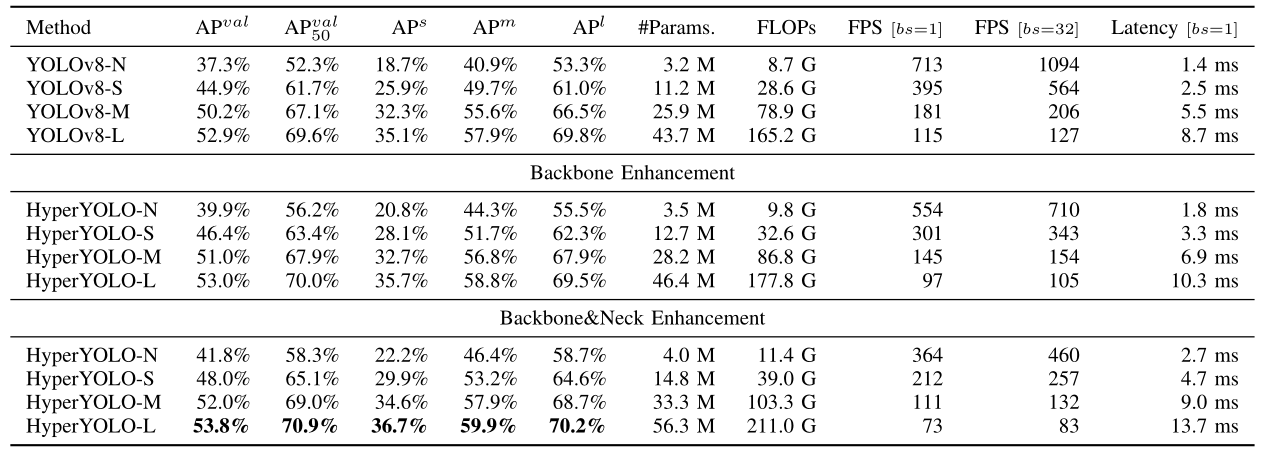
TABLE VIII EXPERIMENTAL RESULTS ON INSTANCE SEGMENTATION TASK.
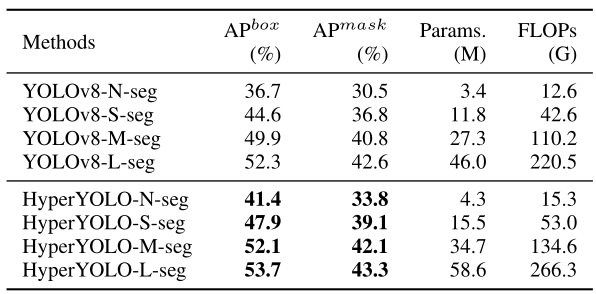
Fig. 5. Visualization of feature maps before and after high-order learning.

【翻译】图5. 高阶学习前后特征图的可视化。
APPENDIX A IMPLEMENTAL DETAILS OF HYPER-YOLO
In this section, we detail the implementation of our proposed models: Hyper-YOLO-N, Hyper-YOLO-S, HyperYOLO-M, and Hyper-YOLO-L. These models are developed upon the PyTorch1. In line with the configuration established by YOLOv8 [8], our models share analogous architectures and loss functions, with the notable exception of incorporating MANet and HyperC2Net. An efficient decoupled head has been integrated for precise object detection. The specific configurations of the Hyper-YOLO-S are depicted in fig. S1.
【翻译】在本节中,我们详细说明了我们提出的模型的实现:Hyper-YOLO-N、Hyper-YOLO-S、HyperYOLO-M和Hyper-YOLO-L。这些模型基于PyTorch1开发。与YOLOv8 [8]建立的配置一致,我们的模型共享类似的架构和损失函数,但值得注意的是融合了MANet和HyperC2Net。已集成了一个高效的解耦头部以实现精确的目标检测。Hyper-YOLO-S的具体配置在图S1中描述。
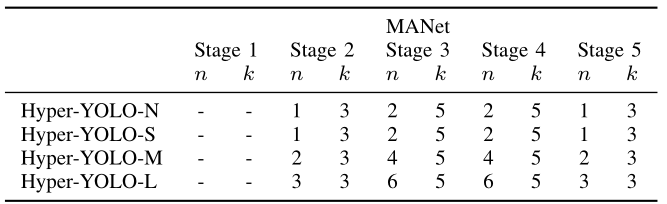
TABLE S1 CONFIGURATION OF HYPER-YOLO’S BACKBONE. THE STAGE 1 5 REFER TO FIG. S1.
【翻译】表S1 HYPER-YOLO骨干网络的配置。阶段1-5参考图S1。
A. Backbone
The backbone of HyperYOLO, detailed in table S1, has been updated from its predecessor, with the C2f module being replaced by the MANet module, maintaining the same number of layers as in YOLOv8 [8], structured as [3, 6, 6, 3]. The channel counts for each stage are kept consistent with those in YOLOv8, with the only change being the module swap.
【翻译】HyperYOLO的骨干网络详见表S1,已从其前身更新,C2f模块被MANet模块替换,保持与YOLOv8 [8]相同的层数,结构为[3, 6, 6, 3]。每个阶段的通道数与YOLOv8保持一致,唯一的变化是模块替换。
The MANet employs depthwise separable convolutions with an increased channel count, where a 2 c 2c 2c input is expanded to a 4 c 4c 4c output (with 2 c 2c 2c equivalent to $\overline{{c_{o u t}}}$ ).
【翻译】MANet采用深度可分离卷积,通道数增加,其中 2 c 2c 2c输入扩展为 4 c 4c 4c输出( 2 c 2c 2c等价于$\overline{{c_{o u t}}}$)。
In addition to these adjustments, the hyperparameters k k k and n n n for the four stages are set to [3, 5, 5, 3] and [3, 6, 6, 6] × \times × depth, respectively. The depth multiplier varies across the different scales of the model, being set to 1 / 3 , 1 / 3 , 2 / 3 1/3,1/3,2/3 1/3,1/3,2/3 , and 1 for the Hyper-YOLO-N, Hyper-YOLO-S, Hyper-YOLOM, and Hyper-YOLO-L, respectively. This means that the actual count of n n n at each stage of the models is [ 3 , 6 , 6 , 6 ] [3,6,6,6] [3,6,6,6] multiplied by the corresponding depth factor for that scale. These specifications ensure that each scale of the HyperYOLO model is equipped with a backbone that is finely tuned for its size and complexity, enabling efficient feature extraction at multiple scales.
【翻译】除了这些调整之外,四个阶段的超参数 k k k和 n n n分别设置为[3, 5, 5, 3]和[3, 6, 6, 6] × \times × depth。深度乘数在模型的不同尺度之间变化,对于Hyper-YOLO-N、Hyper-YOLO-S、Hyper-YOLO-M和Hyper-YOLO-L分别设置为 1 / 3 , 1 / 3 , 2 / 3 1/3,1/3,2/3 1/3,1/3,2/3和1。这意味着模型每个阶段的 n n n的实际计数是 [ 3 , 6 , 6 , 6 ] [3,6,6,6] [3,6,6,6]乘以该尺度对应的深度因子。这些规格确保HyperYOLO模型的每个尺度都配备了针对其大小和复杂性精细调优的骨干网络,实现多尺度的高效特征提取。
TABLE S2 DETAILED CONFIGURATION OF HYPER-YOLO’S NECK. C i n C_{i n} Cin AND C o u t C_{o u t} Cout DENOTE THE NUMBER OF INPUT AND OUTPUT CHANNELS OF HYPERCONV, RESPECTIVELY. ϵ DENOTES THE PREDETERMINED DISTANCE THRESHOLD FOR HYPERGRAPH CONSTRUCTION.
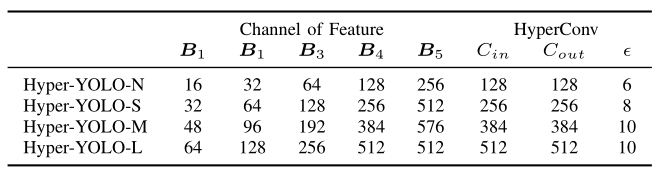
【翻译】表S2 HYPER-YOLO颈部的详细配置。 C i n C_{i n} Cin和 C o u t C_{o u t} Cout分别表示HYPERCONV的输入和输出通道数。ϵ表示超图构建的预定距离阈值。
B. Neck
Compared to the neck design in YOLOv8, the HyperYOLO model introduces the HyperC2Net (Hypergraph-Based Cross-level and Cross-position Representation Network) as its neck component, detailed in fig. 4. This innovative structure is an embodiment of the proposed HGC-SCS framework, specifically engineered to encapsulate potential high-order correlations existing within the semantic space.
【翻译】与YOLOv8的颈部设计相比,HyperYOLO模型引入了HyperC2Net(基于超图的跨层和跨位置表示网络)作为其颈部组件,详见图4。这种创新结构是所提出的HGC-SCS框架的体现,专门设计用于封装语义空间中存在的潜在高阶相关性。
The HyperC2Net is designed to comprehensively fuse crosslevel and cross-position information emanating from the backbone network. By leveraging the hypergraph architecture, it effectively captures the complex interdependencies among feature points across different layers and positions. This allows the model to construct a more intricate and enriched representation of the input data, which is particularly useful for identifying and delineating subtle nuances within the images being processed. In the context of the Hyper-YOLO model’s varying scales, the neck plays a critical role in maintaining the consistency of high-order correlation representation. Since the spatial distribution of feature points can significantly differ between models like Hyper-YOLO-N and Hyper-YOLO-L, with the latter typically having a more dispersed distribution, the HyperC2Net adjusts its approach accordingly by employing different distance thresholds for each model scale, as outlined in table S2, to ensure that the network captures the appropriate level of high-order correlations without succumbing to oversmoothing. The HyperC2Net’s ability to dynamically adapt its threshold values based on the model scale and feature point distribution is a testament to its sophisticated design. It strikes a fine balance between the depth of contextual understanding and the need to preserve the sharpness and granularity of the feature space, thereby enhancing the model’s overall performance in detecting and classifying objects within varied and complex visual environments.
【翻译】HyperC2Net旨在全面融合来自骨干网络的跨层和跨位置信息。通过利用超图架构,它有效地捕获了不同层和位置之间特征点的复杂相互依赖关系。这使得模型能够构建更复杂和丰富的输入数据表示,这对于识别和描绘正在处理的图像中的细微差别特别有用。在Hyper-YOLO模型不同尺度的背景下,颈部在维持高阶相关性表示的一致性方面发挥着关键作用。由于特征点的空间分布在Hyper-YOLO-N和Hyper-YOLO-L等模型之间可能存在显著差异,后者通常具有更分散的分布,HyperC2Net通过为每个模型尺度采用不同的距离阈值(如表S2所述)来相应地调整其方法,以确保网络捕获适当级别的高阶相关性而不会出现过度平滑。HyperC2Net基于模型尺度和特征点分布动态调整其阈值的能力证明了其复杂的设计。它在上下文理解深度和保持特征空间锐度和粒度需求之间取得了精妙的平衡,从而增强了模型在各种复杂视觉环境中检测和分类对象的整体性能。
APPENDIX B VISUALIZATIONS OF RESULTS
In this section, we further provide visualizations of the Hyper-YOLO on two tasks: object detection and instance segmentation, as shown in fig. S2 and fig. S3, respectively.
在本节中,我们进一步提供了Hyper-YOLO在两个任务上的可视化结果:目标检测和实例分割,分别如图S2和图S3所示。
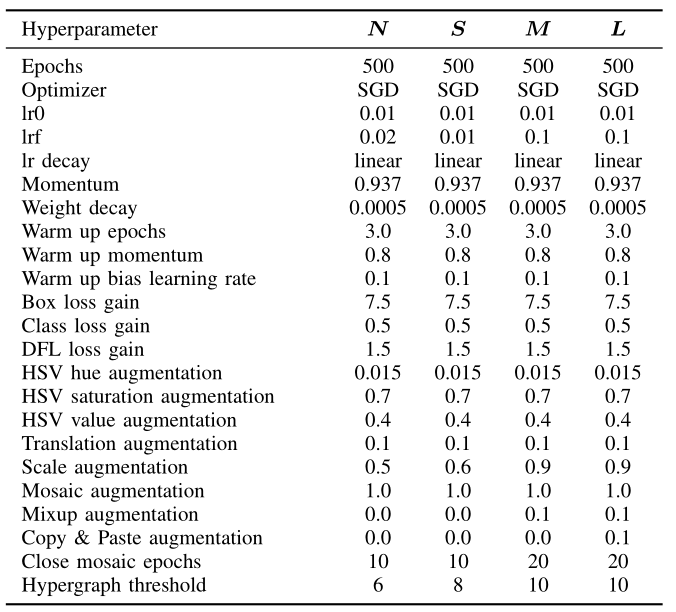
TABLE S3 DETAILED CONFIGURATION OF DIFFERENT HYPER-YOLO VARIATIONS FOR TRAINING.
表S3 不同Hyper-YOLO变体训练的详细配置。
A. Object Detection
The results depicted in fig. S2 illustrate that our HyperYOLO model exhibits superior object recognition capabilities, as demonstrated in figures (b) and ©. Moreover, owing to the usage of a hypergraph-based neck in its architecture, HyperYOLO possesses a certain degree of class inference ability. This is most evident in figure (a), where Hyper-YOLO is capable of inferring with high confidence that if one bird is detected, the other two entities are also birds. Additionally, as observed in figure (e), it is common for humans to play with dogs using a frisbee. Even though only a glove is visible in the image, our Hyper-YOLO is still able to recognize it as part of a human.
【翻译】图S2中描述的结果表明,我们的HyperYOLO模型表现出卓越的目标识别能力,如图(b)和©所示。此外,由于在其架构中使用了基于超图的颈部,HyperYOLO具有一定程度的类别推理能力。这在图(a)中最为明显,其中Hyper-YOLO能够高置信度地推断,如果检测到一只鸟,那么其他两个实体也是鸟。另外,如图(e)所观察到的,人类用飞盘和狗玩耍是很常见的。即使图像中只能看到一只手套,我们的Hyper-YOLO仍然能够识别它是人的一部分。
B. Instance Segmentation
Results from fig. S3 indicate that, compared to YOLOv8, Hyper-YOLO achieves significant improvements in both categorization and boundary delineation for segmentation tasks. Despite the ground truth annotation in figure (a) not being entirely accurate, our Hyper-YOLO still manages to provide precise boundary segmentation. Figures ©, (d) and (e) depict more complex scenes, yet our Hyper-YOLO continues to deliver accurate instance segmentation results, ensuring that not a single cookie is missed.
【翻译】图S3的结果表明,与YOLOv8相比,Hyper-YOLO在分割任务的分类和边界描绘方面都取得了显著改进。尽管图(a)中的真实标注并不完全准确,我们的Hyper-YOLO仍然能够提供精确的边界分割。图©、(d)和(e)描绘了更复杂的场景,但我们的Hyper-YOLO继续提供准确的实例分割结果,确保没有遗漏任何一块饼干。
APPENDIX C TRAINING DETAILS OF HYPER-YOLO
The training protocol for Hyper-YOLO was carefully designed to foster consistency and robustness across varying experiments. Each GPU was allocated a uniform batch size of 20 to maintain a consistent computational environment, utilizing a total of 8 NVIDIA GeForce RTX 4090 GPUs. To assess the learning efficacy and generalization capacity, all variants of Hyper-YOLO, including -N, -S, -M, and -L, were trained from the ground up. The models underwent 500 epochs of training without relying on pre-training from large-scale datasets like ImageNet, thereby avoiding potential biases. The training hyperparameters were fine-tuned to suit the specific needs of the different sizes of the model. table S3 summarizes the key hyperparameters for each model scale.
【翻译】Hyper-YOLO的训练协议经过精心设计,以在不同实验中培养一致性和鲁棒性。每个GPU被分配统一的批次大小为20,以维持一致的计算环境,总共使用8块NVIDIA GeForce RTX 4090 GPU。为了评估学习效率和泛化能力,包括-N、-S、-M和-L在内的所有Hyper-YOLO变体都从头开始训练。模型经历了500个epoch的训练,而不依赖于像ImageNet这样的大规模数据集的预训练,从而避免了潜在的偏差。训练超参数经过微调以适应模型不同尺寸的特定需求。表S3总结了每个模型规模的关键超参数。
Fig. S2. Results comparison of YOLOv8-S and Hyper-YOLO-S in the Object Detection task. Red boxes highlight objects detected with incorrect labels.

【翻译】图S2. YOLOv8-S和Hyper-YOLO-S在目标检测任务中的结果比较。红色框突出显示标签检测错误的对象。
Those core parameters, such as the initial learning rate and weight decay, were uniformly set across all scales to standardize the learning process. The hypergraph threshold, however, was varied according to the model scale and batch size. This threshold was configured with a batch size of 20 per GPU in mind, implying that if the batch size were to change, the threshold would need to be adjusted accordingly. Generally, a larger batch size on a single GPU would necessitate a lower threshold, whereas a larger model scale correlates to a higher threshold.
【翻译】这些核心参数,如初始学习率和权重衰减,在所有尺度上统一设置以标准化学习过程。然而,超图阈值根据模型尺度和批次大小而变化。这个阈值是在每个GPU批次大小为20的前提下配置的,这意味着如果批次大小发生变化,阈值需要相应调整。一般来说,单个GPU上更大的批次大小需要更低的阈值,而更大的模型尺度对应更高的阈值。
Most hyperparameters remained consistent across the different model scales; nonetheless, parameters such as the learning rate, scale augmentation, mixup augmentation, copy & paste augmentation, and the hypergraph threshold were tailored for each model scale. Data augmentation hyperparameters were set in accordance with YOLOv5’s configuration, with certain modifications for Hyper-YOLO. For instance, the N \mathbf{N} N and S models employed lower levels of data augmentation, with specific adjustments made for the N model’s final learning rate ( l r f = 0.02 ) (\mathrm{lrf}{=}0.02) (lrf=0.02) and the S model’s scale augmentation s c a l e ˇ = 0.6 ) \mathrm{\check{scale}}{=}0.6) scaleˇ=0.6) .
【翻译】大多数超参数在不同模型尺度之间保持一致;尽管如此,学习率、尺度增强、混合增强、复制粘贴增强和超图阈值等参数针对每个模型尺度进行了定制。数据增强超参数根据YOLOv5的配置设置,并针对Hyper-YOLO进行了某些修改。例如, N \mathbf{N} N和S模型采用较低级别的数据增强,对N模型的最终学习率 ( l r f = 0.02 ) (\mathrm{lrf}{=}0.02) (lrf=0.02)和S模型的尺度增强 s c a l e ˇ = 0.6 ) \mathrm{\check{scale}}{=}0.6) scaleˇ=0.6)进行了特定调整。
Fig. S3. Results comparison of YOLOv8-S and Hyper-YOLO-S in the Instance Segmentation task. Red boxes denote mis-detected or partially segmented.
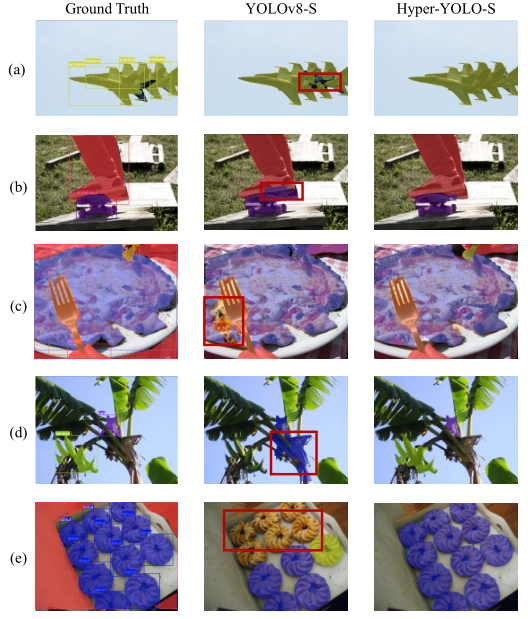
【翻译】图S3. YOLOv8-S和Hyper-YOLO-S在实例分割任务中的结果比较。红色框表示误检测或部分分割。
The M and L models, on the other hand, utilized moderate and high levels of data augmentation, respectively, with both scales having the same setting for close mosaic epochs (20).
【翻译】另一方面,M和L模型分别使用中等和高级别的数据增强,两个尺度都具有相同的关闭马赛克epoch设置(20)。
It should be emphasized that the hypergraph threshold is set under the premise of a batch size of 20 per GPU. Alterations to the batch size should be accompanied by corresponding adjustments to the threshold, following the trend that a larger single-GPU batch size should lead to a smaller relative threshold. Similarly, larger model scales require higher thresholds. Most hyperparameters are consistent across different model scales, with the exception of a few like lrf, scale augmentation, mixup augmentation, copy & paste augmentation, and hypergraph threshold, which are tailored to the specific scale of the model. Data augmentation parameters are largely based on the YOLOv5 settings, with some values being distinct to accommodate the different requirements of the Hyper-YOLO model.
【翻译】应该强调的是,超图阈值是在每个GPU批次大小为20的前提下设置的。批次大小的改变应伴随阈值的相应调整,遵循更大的单GPU批次大小应导致更小的相对阈值的趋势。同样,更大的模型尺度需要更高的阈值。大多数超参数在不同模型尺度之间是一致的,除了少数几个如lrf、尺度增强、混合增强、复制粘贴增强和超图阈值,这些都是针对模型的特定尺度量身定制的。数据增强参数主要基于YOLOv5设置,其中一些值是独特的,以适应Hyper-YOLO模型的不同要求。
APPENDIX D DETAILS OF SPEED TEST
The speed benchmarking for our Hyper-YOLO model adopts a two-group approach. The first group comprises models requiring reparameterization, such as YOLOv6-3.0 and Gold-YOLO. The second group includes YOLOv5, YOLOv8, and HyperYOLO. Notably, during the conversion process to ONNX format, the HyperYOLO model encounters issues with the ‘torch.cdist’ function, leading to large tensor sizes that cause errors at batch sizes of 32. To address this and ensure accurate speed measurements, we replace the ‘torch.cdist’ function with a custom feature distance function during testing. In addition, we also test the speed of a variant with only an enhanced backbone.
The benchmarking process involves converting the models to ONNX format, followed by conversion to TensorRT engines. The tests are performed twice, under batch sizes of 1 and 32, to assess performance across different operational contexts. Our test environment is controlled, consisting of Python 3.8.16, Pytorch 2.0.1, CUDA 11.7, cuDNN 8.0.5, TensorRT 8.6.1, and ONNX 1.15.0. All tests are carried out with a fixed input size of 640 × 640 640\times640 640×640 pixels.
【翻译】我们Hyper-YOLO模型的速度基准测试采用了双组方法。第一组包括需要重参数化的模型,如YOLOv6-3.0和Gold-YOLO。第二组包括YOLOv5、YOLOv8和HyperYOLO。值得注意的是,在转换为ONNX格式的过程中,HyperYOLO模型在使用’torch.cdist’函数时遇到问题,导致张量尺寸过大,在批次大小为32时会引发错误。为了解决这个问题并确保准确的速度测量,我们在测试期间用自定义特征距离函数替换了’torch.cdist’函数。此外,我们还测试了仅使用增强骨干网络的变体的速度。
【翻译】基准测试过程包括将模型转换为ONNX格式,然后转换为TensorRT引擎。测试进行两次,分别在批次大小为1和32的情况下进行,以评估不同操作环境下的性能。我们的测试环境是受控的,包括Python 3.8.16、Pytorch 2.0.1、CUDA 11.7、cuDNN 8.0.5、TensorRT 8.6.1和ONNX 1.15.0。所有测试都在 640 × 640 640\times640 640×640像素的固定输入尺寸下进行。

)
)






)





)
:理解 NumPy 中的 `np.round`:银行家舍入策略)


