
标题:局部模式在新颖异常上的泛化能力更强
原文链接:https://openreview.net/forum?id=4ua4wyAQLm
源码链接:https://github.com/AllenYLJiang/Local-Patterns-Generalize-Better/
发表:ICLR-2025
摘要
视频异常检测(Video anomaly detection,简称VAD)旨在识别训练期间未见过的新颖动作或事件。现有主流的VAD技术通常关注于包含冗余细节的全局模式,难以泛化到未见过的样本。在本文中,我们提出了一个识别局部模式的框架,该框架可泛化到新颖样本,并建模局部模式的动态性。通过图像-文本对齐与跨模态注意力的两阶段过程,实现了提取空间局部模式的能力。通过关注语义相关的组成部分,我们构建了具有泛化能力的表示,这些组成部分可重新组合以捕捉新颖异常的本质,减少不必要的视觉数据变化。为增强局部模式的时间线索,我们提出了状态机模块(State Machine Module, SMM),该模块利用先前的高分辨率文本标记来引导后续低分辨率观测的精确字幕生成。此外,时间运动估计补充了空间局部模式,以检测具有新颖空间分布或独特动态特征的异常。我们在多个流行的基准数据集上进行了大量实验,展示了该方法达到的最新性能水平。代码地址:https://github.com/AllenYLJiang/Local-Patterns-Generalize-Better/
1 引言
视频异常检测(Video anomaly detection,VAD)是从视频中定位偏离常规模式的事件的任务,例如暴力、事故和其他突发事件。如今,众多平台如闭路电视(CCTV)和无人机(UAV)在监控中发挥着越来越重要的作用。然而,考虑到视频数据量庞大且异常发生的概率较低,依靠人工检测这些事件在实际中是不可行的。此外,正常事件与异常事件之间的视觉数据变化和领域差异阻碍了检测方法的有效性。因此,VAD 已成为弱监督或无监督学习中的一个重要研究课题(Gong et al., 2019; Shi et al., 2023b; Chalapathy et al., 2017; Lu et al., 2020; Pang et al., 2020; Lv et al., 2021; Georgescu et al., 2021a; Zaheer et al., 2020b; Ristea et al., 2021; Acsintoae et al., 2021)。
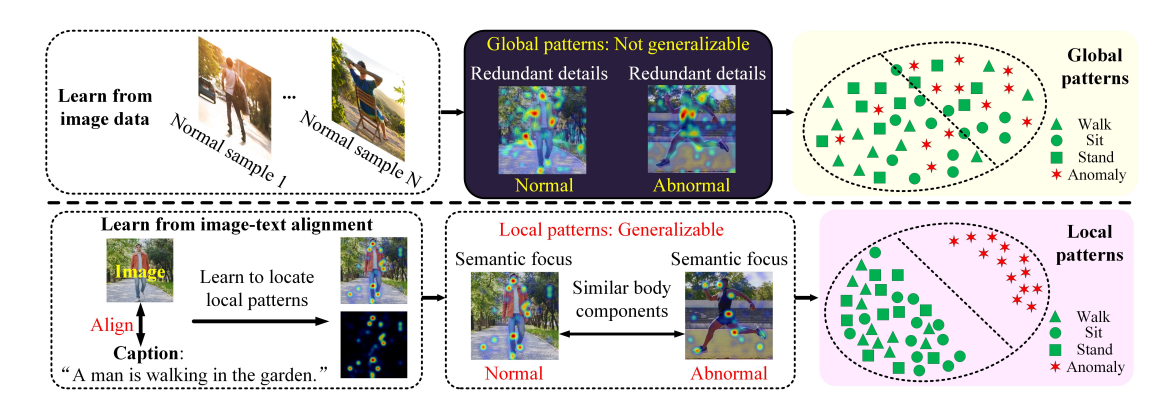
现有主流的 VAD 方法(Li et al., 2022c; Luo et al., 2021a; Georgescu et al., 2021a)可分为四类。第一类方法通过利用显著的空间和时间特征来检测异常。这类方法包括基于预测的方法(Luo et al., 2021a; Lv et al., 2021; Lu et al., 2020; Park et al., 2020)以及基于重建的方法(Yang et al., 2023b; Lv et al., 2023; Chang et al., 2020; Liu et al., 2021)。为了增强表示能力,一些方法结合了多粒度的时空表示(Zhang et al., 2024)以实现更好的区分能力,或集成多种特征(Georgescu et al., 2021a; Cho et al., 2023)以更好地适配未见样本(Liu et al., 2022b)。第二类方法采用多实例学习(Multiple Instance Learning,MIL)来迭代识别有用的数据片段,并微调模型以进行异常检测(Cho et al., 2023; Wang et al., 2022a; Li et al., 2022a; Zhu et al., 2022; Liu et al., 2023c)。例如,动态聚类技术可使模型表示适应实时观测(Wu et al., 2022; Yang et al., 2022)。基于提示(Prompt-enhanced)的 MIL 方法(Chen et al., 2024)将语义先验与视觉特征融合,以改进异常建模。然而,如图1所示,由于背景噪声导致的视觉数据变化,表示仍不一致,因而泛化能力仍然不足。第三类方法(Liu et al., 2023c)关注于生成真实的异常,以细化正常与异常样本之间的决策边界。基于提示的方法(Wu et al., 2024a)也被提出用于生成伪异常。但这些生成的异常依赖于先验假设,无法覆盖现实中多样且出乎意料的异常样本。第四类方法(Zanella et al., 2024)则利用大型模型(Yang et al., 2024a)中的视觉-语言知识与推理能力来生成文本描述或伪标签进行自训练(Yang et al., 2024b),从而提升对异常事件的判别能力(Micorek et al., 2024)。
为了将模型表示泛化到新颖的异常,我们提出了一个两阶段的框架用于识别局部模式。在阶段一中,通过图像-文本对齐来定位在视觉数据变化中保持一致的、具有文本信息的局部模式。阶段二进一步通过跨模态注意力精炼局部模式,得到更紧凑的局部特征。最后,将时间线索与空间局部模式结合,更好地判断异常。
总之,我们提出的框架由图像-文本对齐模块(Image-Text Alignment Module,ITAM)和跨模态注意力模块(Cross-Modality Attention Module,CMAM)组成,用于以两阶段方式识别局部模式。ITAM 选择具有文本信息的区域,将高维视觉数据转化为有效的图像标记(image tokens)。这些标记被时间句子生成模块(Temporal Sentence Generation Module,TSGM)转换为文本,CMAM 使用这些文本进一步精炼图像标记为局部模式。时间线索通过两种方式增强局部模式:TSGM 结合多时间片段上下文生成用于跨模态注意力的句子;同时,时间运动估计(temporal motion estimation)通过建模动态性,丰富空间局部模式。在多个基准上(如 ShanghaiTech、Ubnormal 等)验证了该方法的有效性,具体贡献如下:
-
本文提出了一种新颖的两阶段方法,用于识别在视觉数据变化中保持一致、能泛化到新颖异常样本的局部模式。第一阶段通过图像-文本对齐识别语义上有意义的组件,有助于构建具有泛化能力的表示。跨模态注意力进一步精炼这些组件,同时兼顾文本在泛化方面的优势与视觉特征在细节表示方面的优势。
-
提出了时间增强机制以补充空间局部模式。首先,时间句子生成模块融合多个时刻的上下文,生成连贯的事件描述。此外,时间运动估计通过建模动态性补充局部模式。
-
本文在多个基准数据集上实现了最新的性能水平。
2 相关工作
2.1 无监督视频异常检测
由于监控视频的不平衡特性,大多数训练数据集并未包含异常注释,因为标注代价高昂(Li et al., 2022b;Liu et al., 2023b;Deng et al., 2023)。
基于重建的方法(Astrid et al., 2024;Yang et al., 2023b;Fang et al., 2020;Li et al., 2020a;Gong et al., 2019;Asad et al., 2021;Abati et al., 2019;Sabokrou et al., 2018)在遇到训练数据中不存在的不规则特征(Ramachandra et al., 2020;Madan et al., 2023;Yu et al., 2023)时会产生更大的重建误差。例如,Zaheer et al. (2022a) 的方法学习不重建异常样本。Gong et al. (2019); Gao et al. (2022) 强化编码器以提升重建误差对异常的敏感性。Madan et al. (2021); Chang et al. (2020); Singh et al. (2023); Yu et al. (2022b); Shi et al. (2023a) 融合多模态特征(Ding et al., 2021),而 Huang et al. (2022) 引入概率决策模型。Zaheer et al. (2022b) 评估重建质量以提升稳定性。基于预测的方法(Luo et al., 2021b;Morais et al., 2019;Luo et al., 2021a;Liu et al., 2018;Nguyen & Meunier, 2019;Zeng et al., 2021)则利用正常与异常之间的时序依赖性差异进行建模,并借助潜在空间(Zhang et al., 2020)或混合注意力机制(Zhang et al., 2022b)进行评估。
为了更好地区分异常,Lv et al. (2021); Lu et al. (2020); Liu et al. (2021); Park et al. (2020); Li et al. (2021a) 将预测与重建相结合。Sato et al. (2023); Wu et al. (2023); Luo et al. (2019) 对正常样本的分布进行建模,并提出新颖特征(Arad & Werman, 2023)。类似地,Yan et al. (2023) 提出去噪扩散模块。Flaborea et al. (2023) 利用扩散概率模型的模式覆盖能力。为提升表示能力,Chang et al. (2021); Fan et al. (2024) 提出片段级注意力机制。Liu et al. (2023a); Yu et al. (2022a); Purwanto et al. (2021) 引入金字塔形变与条件随机场以学习时空依赖(Bertasius et al., 2021;Cho et al., 2022)。Wang et al. (2021) 融合多尺度特征以增强预测能力。Stergiou et al. (2024) 结合内插与外推进行预测。Wang et al. (2022b) 提出基于判别式深度神经网络的自监督方案。我们提出可泛化的局部模式,以更好地表示未见样本。
2.2 弱监督异常检测
多实例学习(Multi-instance learning, MIL)将视频视为“包”,将片段视为“实例”,从而将视频级标签转化为实例级标签(Feng et al., 2021)。这些方法迭代定位异常片段,并使用与正常样本差异较大的异常片段微调模型(Zhang et al., 2023a)。为收集异常片段,可根据时空相似性计算样本间距离(Lu et al., 2022;Ionescu et al., 2019;Dhiman & Vishwakarma, 2020;Lv et al., 2023;Chang et al., 2020;Markovitz et al., 2020)。Li et al. (2021b) 提出概率框架。Sun et al. (2020); Li et al. (2020b) 构建图表示,并在相似性度量中集成群体特征。Sapkota & Yu (2022) 采用动态非参数聚类方法。为提升鲁棒性,Zhang et al. (2023b) 研究 MIL 的脆弱性。Wu & Liu (2021) 引入因果关系增强 MIL(Tian et al., 2021)。Yang et al. (2023a) 提出二值网络增强策略。与上述方法不同,我们提出具有泛化能力的表示,有助于衡量已见与未见事件之间的相似性。
2.3 使用数据增强的方法
为在微调中生成伪异常样本,Liu et al. (2023c); Lin et al. (2022); Kim et al. (2022); Liu et al. (2022a); Astrid et al. (2021) 提出伪异常片段合成器,这些合成器是在正常样本上训练的(Yu et al., 2021)。Zaheer et al. (2020a) 使用未完全训练的生成器生成异常样本。Chen et al. (2022) 利用条件 GAN 生成类别均衡的训练数据。Lim et al. (2018) 关注生成过程中低频正常样本,采用新颖的采样策略。除帧级分析(Zaheer et al., 2020b)外,对象级方法(Sun & Gong, 2023;Ionescu et al., 2019;Luo et al., 2021a)可提供更细粒度分析。Acsintoae et al. (2022) 引入包含多样异常的新数据集。然而,生成数据缺乏真实世界的模式,这突显了对可泛化模式的必要性。
2.4 探索未见类别表示的方法
为使模型表示能够适应不断变化的异常,元学习(meta learning)方法(Lu et al., 2020;Park et al., 2020)、迁移学习(Doshi & Yilmaz, 2020)、持续学习(Doshi & Yilmaz, 2020)和自监督方法(Pang et al., 2020;Degardin & Proença, 2021)引入了可适应的特征表示。基于注意力的方法(Sultani et al., 2018;Guo et al., 2023;Li et al., 2021c;Luo et al., 2017)关注于在处理未见样本时的领域不变特征。为更好地适配异常检测任务,Georgescu et al. (2021a) 将多个子任务集成。Zhou et al. (2023a) 引入用于视频表示的层次图,并最大化类别间边界。与这些方法不同,我们的方法定位可泛化到未见事件的、具有文本信息的局部模式。
2.5 提示学习方法(Prompting Methods)
基于提示的方法已被广泛应用于异常检测任务中(Du et al., 2022;Liu et al., 2023c;Sato et al., 2023)。例如,Zhou et al. (2023b) 学习与对象无关的文本提示,以实现泛化异常识别。Yang et al. (2024a) 提出基于规则的推理方法,以实现少量正常样本下的提示学习。与直接使用提示的方法不同,我们探索了视觉-语言模型(VLMs)中连接图像与文本的局部模式。
3 方法(METHODOLOGY)
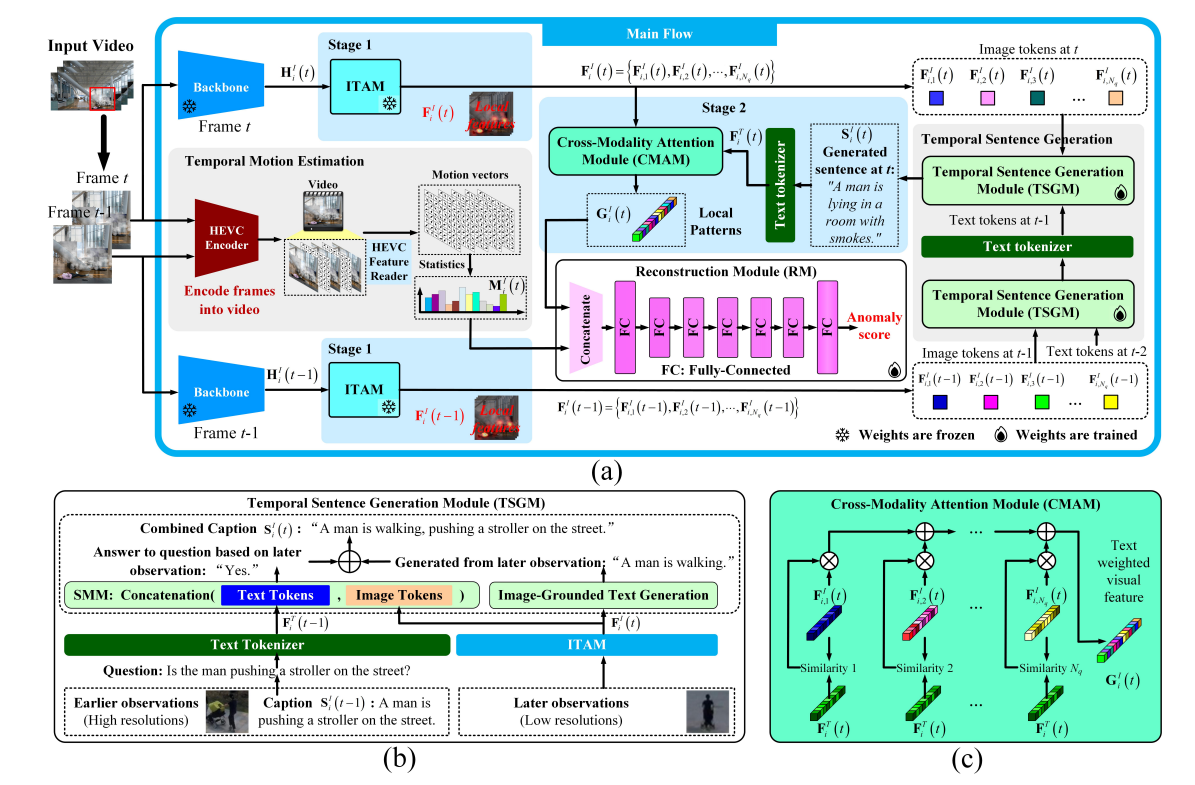
为了使用具有泛化能力的表示来刻画出乎意料的异常,我们建立了一个框架,用于识别具有字幕信息的局部模式。该框架使用 ITAM 和 CMAM 在两个阶段中定位空间局部模式,如图 2(a) 所示。为了通过时间线索增强局部模式,我们研究了时间句子生成和时间运动估计。首先,如图 2(b) 所示,TSGM 建模了早期文本标记和后续图像标记之间的依赖关系,从而增强了 CMAM 的输入句子。然后,从视频压缩中获取帧间运动向量。最后,空间和时间线索被组合于重建模块(RM)中用于检测异常。接下来的部分将讨论各个模块。
3.1 图像区域裁剪(CROPPING OF IMAGE REGIONS)
由于某些帧具有宽广的视野,包含大量对象,即使是 GPT-4(Achiam et al., 2023)也难以同时关注所有对象。因此,局部区域裁剪是我们流程中的第一步。我们尝试使用 YOLOv7(Wang et al., 2023)和 Qwen-7B(Bai et al., 2023)根据提示进行边界框裁剪。具体而言,“图中有多少人?”和“第 i i i 个对象的边界框”被依次提供给 Qwen-7B,模型返回对应的框。比较将在附录 D 中给出。
3.2 阶段一:识别空间局部模式(STAGE 1 FOR IDENTIFYING SPATIAL LOCAL PATTERNS)
该阶段识别与文本对齐的裁剪图像区域中的特征。这些文本描述了通用的运动属性(例如,“一个男人正挥动手臂和腿走路”)。在遇到一个未见过的动作(例如跑步)时,模型可以重组已知的组件如手臂和腿来生成描述性语言,捕捉动作的本质而无需明确命名。如图 1 所示,热力图表明了对局部组件的注意力,突出显示了共享属性的语义区域。更多可视化结果见图 4。
为了识别与文本对齐的局部模式,我们使用冻结的图像编码器(Li et al., 2023)和 BLIP-2 中的 Q-Former(Li et al., 2023)的图像 transformer 作为主干和 ITAM。主干输出 H i I ( t ) ∈ R S d × V d H^I_i(t) \in \mathbb{R}^{S_d \times V_d} HiI(t)∈RSd×Vd,Q-Former 有一个图像 transformer 和一个文本 transformer,用于对齐两个模态的特征,图像 transformer 的输出为 F i I ( t ) ∈ R N q × H d F^I_i(t) \in \mathbb{R}^{N_q \times H_d} FiI(t)∈RNq×Hd,包含 N q N_q Nq 个图像标记 F i , 1 I ( t ) , . . . , F i , N q I ( t ) F^I_{i,1}(t), ..., F^I_{i,N_q}(t) Fi,1I(t),...,Fi,NqI(t),它们提供图像区域 i i i 的字幕信息,并在视觉数据变化中保持一致,如图 4 的热力图所示。详细结构见附录 C。算法 1 展示了阶段一和阶段二的工作流程。
算法 1 两阶段识别空间局部模式的过程
1: 输入:输入图像、Backbone、ITAM、CMAM、TSGM 和文本分词器
2: 输出:表示空间局部模式的跨模态嵌入 G i I ( t ) G^I_i(t) GiI(t)
3: 阶段一:图像标记提取:
4: (1)使用主干提取特征图 H i I ( t ) H^I_i(t) HiI(t)
5: (2)将 H i I ( t ) H^I_i(t) HiI(t) 输入 ITAM,获得与文本对齐的图像标记 { F i , j I ( t ) } j = 1 N q \{F^I_{i,j}(t)\}_{j=1}^{N_q} {Fi,jI(t)}j=1Nq
6:阶段二:跨模态注意力:
7: (1)将图像标记 { F i , j I ( t ) } j = 1 N q \{F^I_{i,j}(t)\}_{j=1}^{N_q} {Fi,jI(t)}j=1Nq 输入 TSGM,获得文本标记 F i T ( t ) F^T_i(t) FiT(t)
8: (2)CMAM 根据 F i T ( t ) F^T_i(t) FiT(t) 与 { F i , j I ( t ) } j = 1 N q \{F^I_{i,j}(t)\}_{j=1}^{N_q} {Fi,jI(t)}j=1Nq的相似性加权求和
9: 返回:加权求和 G i I ( t ) G^I_i(t) GiI(t),表示跨模态特征
3.3 阶段二:识别局部模式(STAGE 2 FOR IDENTIFYING LOCAL PATTERNS)
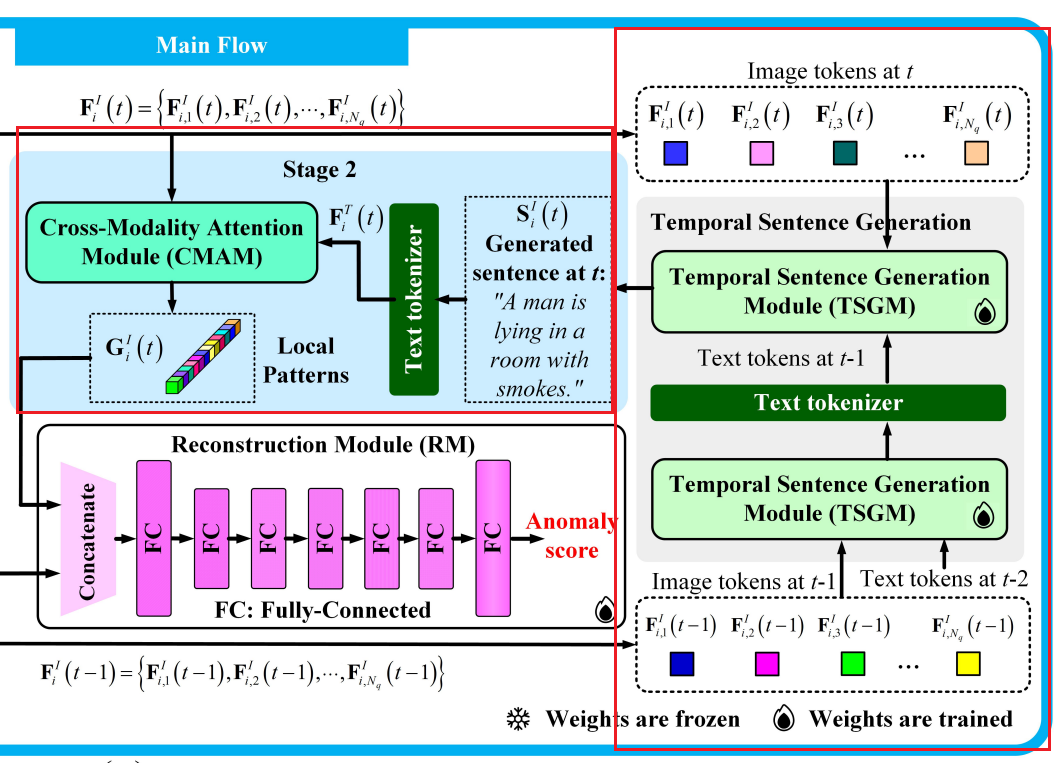
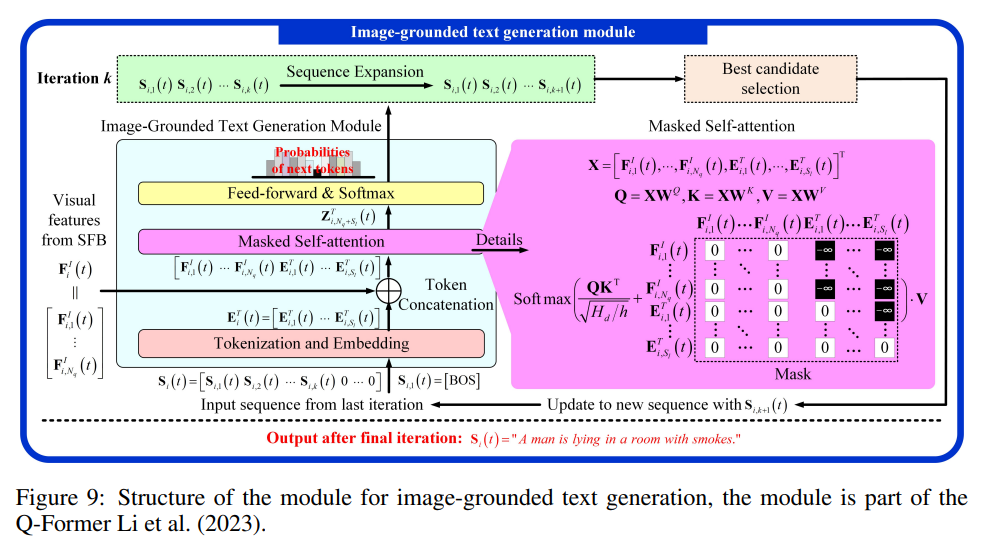
该阶段通过基于图像标记生成句子,并根据其与生成句子的相似性对图像标记进行加权求和,进一步突出局部模式。使用阶段一的图像标记 F i , 1 I ( t ) , . . . , F i , N q I ( t ) F^I_{i,1}(t), ..., F^I_{i,N_q}(t) Fi,1I(t),...,Fi,NqI(t),TSGM 为图像区域 i i i 生成一个句子,如图 2(a) 所示。TSGM 使用 SMM 进行跨帧字幕增强,并使用冻结的 Q-Former(Li et al., 2023)进行图像引导的文本生成。SMM 判断先前的事件是否仍存在于当前帧,而 Q-Former 为当前帧生成字幕。SMM 和 Q-Former 的输出被组合形成增强句子 S i I ( t ) S^I_i(t) SiI(t)。即使在时刻 t t t 的观测不完整,只要事件仍存在于当前帧中, S i I ( t ) S^I_i(t) SiI(t) 就能识别先前发生的事件。
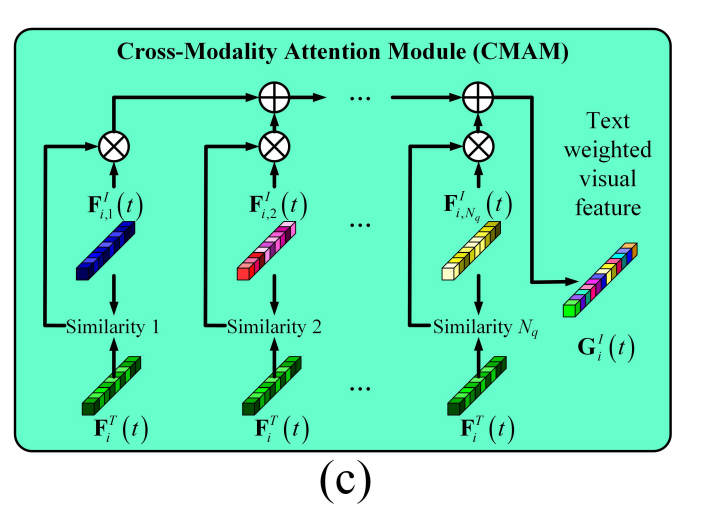
句子 S i I ( t ) S^I_i(t) SiI(t) 的嵌入 F i T ( t ) ∈ R S l × H d F^T_i(t) \in \mathbb{R}^{S_l \times H_d} FiT(t)∈RSl×Hd,其中 S l = 32 S_l = 32 Sl=32 表示一个句子中的最大 token 数,被提供给 CMAM。CMAM 使用 F i T ( t ) F^T_i(t) FiT(t) 的第一个元素作为查询,将图像标记作为键和值进行注意力操作,如图 2© 和公式 (1) 所示:
G i I ( t ) = ( F i T ( t ) [ 0 ] F i I ( t ) ⊤ ) F i I ( t ) , G i I ( t ) ∈ R H d G^I_i(t) = \left(F^T_i(t)[0] {F^I_i(t)}^\top\right) F^I_i(t), \quad G^I_i(t) \in \mathbb{R}^{H_d} GiI(t)=(FiT(t)[0]FiI(t)⊤)FiI(t),GiI(t)∈RHd
F i T ( t ) F^T_i(t) FiT(t) 是由 Q-Former(Li et al., 2023)中的文本 transformer 生成的,其第一个元素 F i T ( t ) [ 0 ] F^T_i(t)[0] FiT(t)[0] 表示整个句子。公式 (1) 根据 F i T ( t ) F^T_i(t) FiT(t) 与图像标记的余弦相似度对图像标记进行加权求和。
通过这种方式,既保留了图像标记在表征视觉细节方面的优势,又获得了文本特征在泛化视觉数据变化方面的好处。消融实验将比较 G i I ( t ) G^I_i(t) GiI(t) 与单模态特征的性能。
3.4 阶段二中的时间句子生成
(TEMPORAL SENTENCE GENERATION IN STAGE 2)
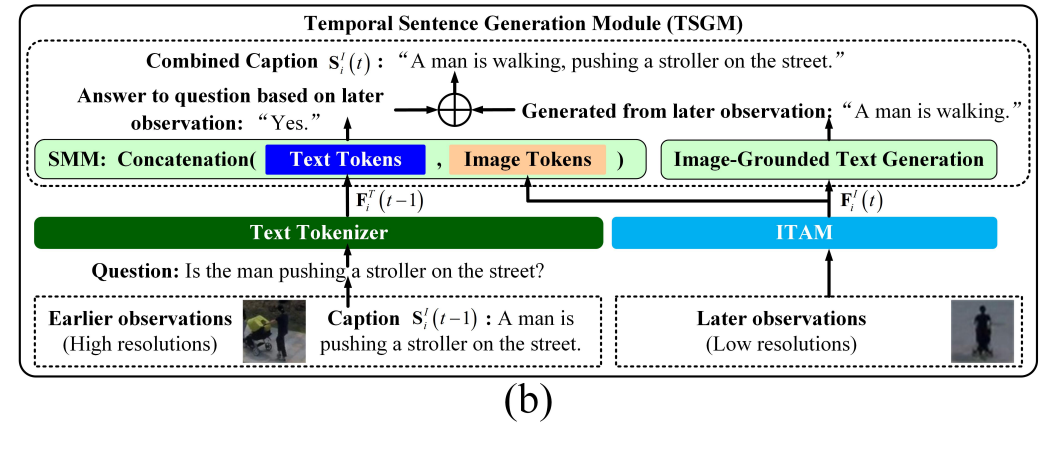
在阶段二中,字幕的生成受到如低分辨率等视觉数据变化的影响。如图 2(b) 所示,Li 等人(2023)提出的图像引导文本生成模块在后期的低分辨率观测下仅提供了粗略字幕 “A man is walking”,而不是更早期、但其实描述相同事件的更精确字幕 “A man is pushing a stroller on the street”。因此,TSGM 中的 SMM 判断早期的高分辨率事件是否已由后期的图像 token 所表达(也就是判断相邻帧是否存在相同的事件)。它捕捉跨帧依赖关系并优化句子的连贯性。SMM 使用早期的文本 token 为低分辨率观测生成更精确的字幕。连续帧中的目标通过边界框的交并比相似性进行关联。
具体而言,SMM 使用早期字幕 S i I ( t − 1 ) S^I_i(t-1) SiI(t−1) 来增强图像 token F i I ( t ) = F i , 1 I ( t ) , . . . , F i , N q I ( t ) F^I_i(t) = {F^I_{i,1}(t), ..., F^I_{i,N_q}(t)} FiI(t)=Fi,1I(t),...,Fi,NqI(t)。早期字幕首先从陈述句转换为疑问句。例如,句子 “The man is pushing a stroller.” 被转换为 “Is the man pushing a stroller?”,其文本 token 表示为 F i T ( t − 1 ) = F i , 1 T ( t − 1 ) , . . . , F i , S l T ( t − 1 ) F^T_i(t - 1) = {F^T_{i,1}(t - 1), ..., F^T_{i,S_l}(t - 1)} FiT(t−1)=Fi,1T(t−1),...,Fi,SlT(t−1)。该转换的详细过程将在附录 G(Hardeniya 等人,2016)中展示。
如图 2(b) 所示,SMM 将 F i T ( t − 1 ) F^T_i(t - 1) FiT(t−1) 与 F i I ( t ) F^I_i(t) FiI(t) 结合作为输入。SMM 中的状态机在输入序列维度上演化:
V i ( t ) = [ F i , 1 T ( t − 1 ) ; . . . ; F i , S l T ( t − 1 ) ; F i , 1 I ( t ) ; . . . ; F i , N q I ( t ) ] ⊤ ∈ R H d × ( S l + N q ) V_i(t) = [F^T_{i,1}(t-1); ...; F^T_{i,S_l}(t-1); F^I_{i,1}(t); ...; F^I_{i,N_q}(t)]^\top \in \mathbb{R}^{H_d \times (S_l + N_q)} Vi(t)=[Fi,1T(t−1);...;Fi,SlT(t−1);Fi,1I(t);...;Fi,NqI(t)]⊤∈RHd×(Sl+Nq)
其中 L = S l + N q L = S_l + N_q L=Sl+Nq 是序列长度,每个 token 的维度为 H d H_d Hd。SMM 根据序列判断 S i I ( t − 1 ) S^I_i(t-1) SiI(t−1) 中的事件是否仍存在于 F i I ( t ) F^I_i(t) FiI(t) 中。
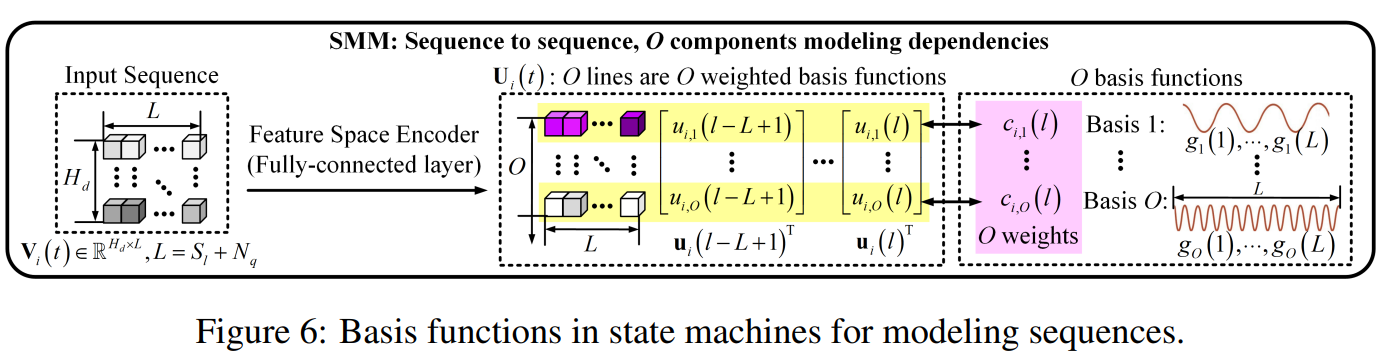
V i ( t ) V_i(t) Vi(t) 被视为 H d H_d Hd 个一维信号的组合,每个长度为 L L L。序列间的依赖关系使用 O O O 个长度为 L L L 的 Legendre 多项式表示(Arfken et al., 2011),即 g o ( 1 ) , . . . , g o ( L ) , o ∈ [ 1 , O ] {g_o(1), ..., g_o(L)}, o \in [1, O] go(1),...,go(L),o∈[1,O],如附录 A 的图 6 所示。输入张量 V i ( t ) V_i(t) Vi(t) 被表示为这 O O O 个固定多项式的加权和。为简化,接下来在对张量列维度分析时省略时间索引 t t t。特征空间编码器生成:
U i ( t ) = [ u i ( l − L + 1 ) ; . . . ; u i ( l ) ] ⊤ ∈ R O × L U_i(t) = [u_i(l - L + 1); ...; u_i(l)]^\top \in \mathbb{R}^{O \times L} Ui(t)=[ui(l−L+1);...;ui(l)]⊤∈RO×L
其中
u i ( l ′ ) = [ u i , 1 ( l ′ ) , . . . , u i , O ( l ′ ) ] , l ′ ∈ ( l − L , l ] u_i(l') = [u_{i,1}(l'), ..., u_{i,O}(l')], \quad l' \in (l - L, l] ui(l′)=[ui,1(l′),...,ui,O(l′)],l′∈(l−L,l]
此处 l l l 沿张量 V i ( t ) V_i(t) Vi(t) 与 U i ( t ) U_i(t) Ui(t) 的列方向变化, ( l − L , l ] (l - L, l] (l−L,l] 是用于编码的列窗口。
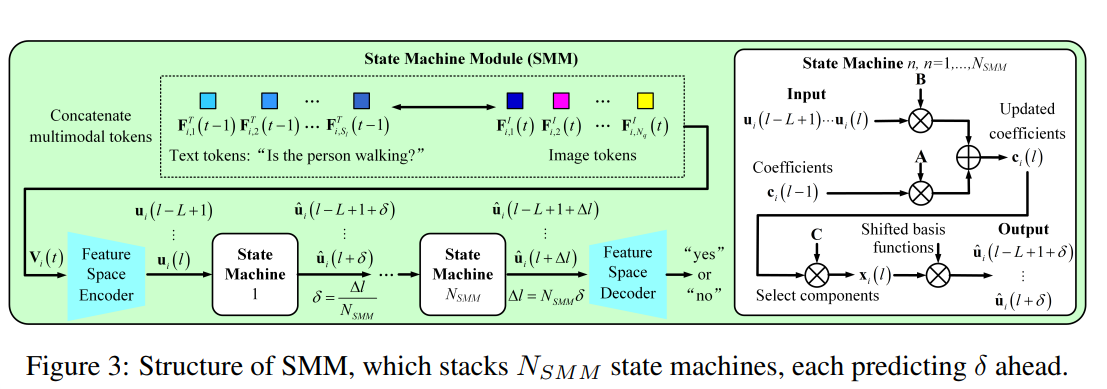
为了更好地建模 H d H_d Hd 维多模态序列,SMM 中堆叠了 N SMM N_\text{SMM} NSMM 个状态机,每个预测 Δ l / N SMM \Delta l / N_\text{SMM} Δl/NSMM 步,如图 3 所示。其优点将在消融实验中展示。 U i ( t ) U_i(t) Ui(t) 通过如下公式用基函数表示:
u i , o ( l ′ ) = c i , o ( l ) g o ( l ′ − l + L ) , o ∈ [ 1 , O ] , l ′ ∈ ( l − L , l ] (2) u_{i,o}(l') = c_{i,o}(l) g_o(l' - l + L), \quad o \in [1, O], l' \in (l - L, l] \tag{2} ui,o(l′)=ci,o(l)go(l′−l+L),o∈[1,O],l′∈(l−L,l](2)
在 SMM 中,状态向量 c i ( l ) = [ c i , 1 ( l ) ; . . . , c i , O ( l ) ] ⊤ c_i(l) = [c_{i,1}(l); ..., c_{i,O}(l)]^\top ci(l)=[ci,1(l);...,ci,O(l)]⊤ 包含 O O O 个权重,编码了 V i ( t ) V_i(t) Vi(t) 中文本与视觉 token 之间的依赖关系,这些依赖被分解为加权的 Legendre 基函数。状态向量的演化用于预测(“yes” 或 “no”):
c i ( l + 1 ) = A c i ( l ) + B ∑ o = 1 O u i , o ( l + 1 ) (3) c_i(l+1) = A c_i(l) + B \sum_{o=1}^{O} u_{i,o}(l+1) \tag{3} ci(l+1)=Aci(l)+Bo=1∑Oui,o(l+1)(3)
其中 A = A ( O , L ) ∈ R O × O A = A(O, L) \in \mathbb{R}^{O \times O} A=A(O,L)∈RO×O 和 B = B ( O , L ) ∈ R O × 1 B = B(O, L) \in \mathbb{R}^{O \times 1} B=B(O,L)∈RO×1 来自 Legendre 多项式(Gu et al., 2020)。当 O O O 增大时,基函数的表达能力增强。假设 c i ( l ) c_i(l) ci(l) 编码了 u i ( l − L + 1 ) , . . . , u i ( l ) u_i(l - L + 1), ..., u_i(l) ui(l−L+1),...,ui(l),基于此预测 u i ( l + 1 ) u_i(l + 1) ui(l+1),即对应 “yes” 或 “no”。 c i ( l + 1 ) c_i(l+1) ci(l+1) 编码的是 u i ( l − L + 2 ) , . . . , u i ( l + 1 ) u_i(l - L + 2), ..., u_i(l + 1) ui(l−L+2),...,ui(l+1)。公式 (3) 的推导见附录 A。
如图 3 所示,SMM 中的转换为:
x i ( l ) = C c i ( l ) , C ∈ R O × O x_i(l) = C c_i(l), \quad C \in \mathbb{R}^{O \times O} xi(l)=Cci(l),C∈RO×O
其中 C C C 为可学习参数,突出重要成分。公式 (3) 被进一步转换为:
x i ( l ) = C A L − 1 B ∑ o = 1 O u i , o ( l − L + 1 ) + . . . + C B ∑ o = 1 O u i , o ( l ) (4) x_i(l) = C A L^{-1} B \sum_{o=1}^{O} u_{i,o}(l - L + 1) + ... + C B \sum_{o=1}^{O} u_{i,o}(l) \tag{4} xi(l)=CAL−1Bo=1∑Oui,o(l−L+1)+...+CBo=1∑Oui,o(l)(4)
最终, x i ( l ) x_i(l) xi(l) 的各元素与平移后的基函数相乘,得到平移加权的基函数:
u ^ i , o ( l ′ + δ ) = x i , o ( l ) g o ( l ′ − l + L + δ ) , o ∈ [ 1 , O ] , l ′ ∈ ( l − L , l ] (5) \hat{u}_{i,o}(l' + \delta) = x_{i,o}(l) g_o(l' - l + L + \delta), \quad o \in [1, O], l' \in (l - L, l] \tag{5} u^i,o(l′+δ)=xi,o(l)go(l′−l+L+δ),o∈[1,O],l′∈(l−L,l](5)
特征空间解码器将 u ^ ∗ i ( l + δ ) = [ u ^ ∗ i , 1 ( l + δ ) , . . . , u ^ i , O ( l + δ ) ] \hat{u}*i(l + \delta) = [\hat{u}*{i,1}(l + \delta), ..., \hat{u}_{i,O}(l + \delta)] u^∗i(l+δ)=[u^∗i,1(l+δ),...,u^i,O(l+δ)] 投影为 “yes” 或 “no”,如图 3 所示。损失函数使用交叉熵。在每个批次中, B s B_s Bs 张图像对应 B s B_s Bs 个陈述句,这些句子会被转换为 B s B_s Bs 个疑问句。每张图像的 token 与对应问题的 token 拼接后送入 SMM:
L SMM = − ∑ i = 0 B s − 1 ∑ j = 0 B s − 1 y i , j log ( Sim ( P ( i , j ) , Emb ( " y e s " ) ) Sim ( P ( i , j ) , Emb ( " y e s " ) ) + Sim ( P ( i , j ) , Emb ( " n o " ) ) ) (6) L_{\text{SMM}} = - \sum_{i=0}^{B_s-1} \sum_{j=0}^{B_s-1} y_{i,j} \log\left( \frac{\text{Sim}(P(i,j), \text{Emb}("yes"))}{\text{Sim}(P(i,j), \text{Emb}("yes")) + \text{Sim}(P(i,j), \text{Emb}("no"))} \right) \tag{6} LSMM=−i=0∑Bs−1j=0∑Bs−1yi,jlog(Sim(P(i,j),Emb("yes"))+Sim(P(i,j),Emb("no"))Sim(P(i,j),Emb("yes")))(6)
其中,当 Qwen-Chat 模型(Bai et al., 2023)在接收图像 i i i 和问题 j j j 后返回 “yes” 时, y i , j = 1 y_{i,j} = 1 yi,j=1,否则为 0 0 0。 Sim ( P ( i , j ) , Emb ( " y e s " ) ) \text{Sim}(P(i,j), \text{Emb}("yes")) Sim(P(i,j),Emb("yes")) 表示 SMM 输出嵌入 P ( i , j ) P(i,j) P(i,j) 与 “yes” 的嵌入之间的余弦相似度。
3.5 时间运动估计与时空异常检测
(TEMPORAL MOTION ESTIMATION AND SPATIO-TEMPORAL ANOMALY DETECTION)
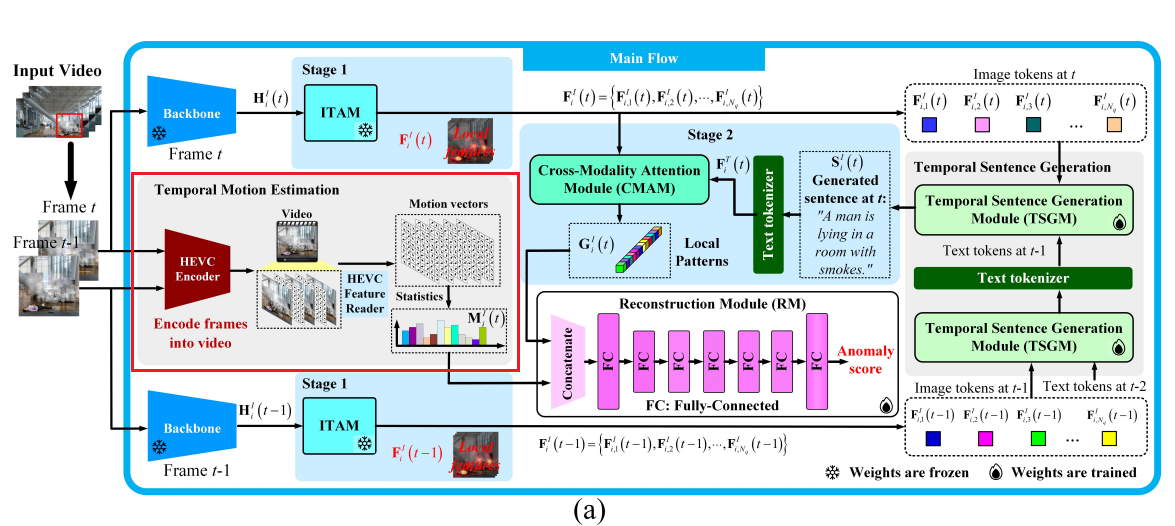
为了增强第二阶段获得的空间局部模式,本文提出使用 FFmpeg(Zeng et al., 2016)将帧编码为 H.265(HEVC)视频。如图 2(a) 所示,从编码后的视频中提取运动向量,每个运动向量对应一个 8 × 8 8 \times 8 8×8 的宏块。每个运动向量的方向被计算为 atan2 ( y , x ) \text{atan2}(y, x) atan2(y,x) 并被量化为 D m = 8 D_m = 8 Dm=8 个等间距的方向区间,其中 x x x 和 y y y 分别是水平方向和垂直方向的分量。每个方向区间内运动向量的平均幅值构成一个 D m D_m Dm 维的直方图 M i I ( t ) M^I_i(t) MiI(t),用于表示第 i i i 个区域在时刻 t t t 的运动状态。
为了检测具有异常局部模式或不规则动态特征的异常,本文训练了一个包含 7 层全连接层的重建模块(Reconstruction Module,RM),其训练数据仅包括正常的空间与时间信息。如图 2(a) 所示,第一层接受局部模式 G i I ( t ) G^I_i(t) GiI(t) 与动态特征 M i I ( t ) M^I_i(t) MiI(t) 的拼接作为输入,其输入通道数为 H d + D m H_d + D_m Hd+Dm,输出通道数为 D h D_h Dh,最后一层则将 D h D_h Dh 通道映射回 H d + D m H_d + D_m Hd+Dm 输出。中间的 5 层隐藏层均具有 D h D_h Dh 个输入与输出通道。
空间与时间特征的重建是联合进行的,从而使得每一个分支的重建都依赖于另一个分支。这种协同重建机制使得异常得分由重建误差来确定。
4 实验与结果
(EXPERIMENTS AND RESULTS)
本节将我们提出的方法与最先进的方案进行比较,并呈现消融研究。
4.1 实验设置
(EXPERIMENTAL SETUP)
数据集 实验在七个数据集上进行。ShanghaiTech、Avenue 和 UCSD Ped2 的训练集只包含正常事件,异常事件出现在测试集中。
(1) ShanghaiTech 数据集(Liu et al., 2018)包含 330 个训练视频和 107 个测试视频。在 ShanghaiTech 数据集的两个版本中(Liu et al., 2018;Zhong et al., 2019;Li et al., 2022a;Zanella et al., 2023),后者在训练集和测试集中都包含异常行为。由于我们的方法是无监督的,我们使用第一个版本。
(2) CUHK Avenue 数据集(Lu et al., 2013)包含 16 个训练视频和 21 个测试视频。
(3) Ubnormal 数据集(Acsintoae et al., 2022)被划分为包含 268 个视频的训练集、64 个视频的验证集和 211 个视频的测试集。
(4) NWPU Campus 数据集(Cao et al., 2023)包含 43 个场景、28 类异常以及 16 小时的视频素材。
(5) UCSD Ped2 数据集(Li et al., 2014)包含 16 个正常训练视频和 12 个测试视频。
(6) UCF-Crime 数据集(Sultani et al., 2018)包含 1610 个训练视频,其中 800 个仅包含正常行为。测试集包含 290 个视频,其中 140 个包含异常。
(7) XD-Violence 数据集(Wu et al., 2020)包含 4754 个视频,其中 2349 个是非暴力的,2405 个是暴力的。训练集中有 3954 个视频,测试集中有 800 个视频,其中 500 个为暴力视频。
评估指标 参照现有文献(Markovitz et al., 2020),我们采用 AUC(曲线下面积,%)作为评估指标。不同的是,在 XD-Violence 数据集上,我们使用精确率-召回率曲线,并采用相应的平均精度(AP,%)作为评估指标(Panariello et al., 2022)。
实现细节 为了捕捉更多上下文,我们在水平方向和垂直方向上将边界框扩展了 50%。边界框扩展的效果将在附录 D 的表 4 中展示。
对于时间 t t t 上的图像区域 i i i,主干网络和 ITAM 的输出分别为 H i I ( t ) ∈ R S d × V d H^I_i(t) \in \mathbb{R}^{S_d \times V_d} HiI(t)∈RSd×Vd 和 F i I ( t ) ∈ R N q × H d F^I_i(t) \in \mathbb{R}^{N_q \times H_d} FiI(t)∈RNq×Hd,其中 S d = 257 S_d = 257 Sd=257, V d = 1408 V_d = 1408 Vd=1408, N q = 32 N_q = 32 Nq=32, H d = 768 H_d = 768 Hd=768。每个图像 token 的维度为 H d H_d Hd。根据 BLIP-2(Li et al., 2023),主干网络采用 Radford 等人(2021)提出的 ViT-L/14 结构。图 2(a) 中的文本 tokenizer 详见附录 C。对于少于 S l S_l Sl 个 token 的句子, F i T ( t ) F^T_i(t) FiT(t) 用零进行填充。RM 的中间层设为 D h = 512 D_h = 512 Dh=512。
SMM 由 N SMM = 3 N_\text{SMM} = 3 NSMM=3 个状态机堆叠而成,在 COCO-Caption 数据集(Lin et al., 2014)上训练。表 3 展示了 N SMM N_\text{SMM} NSMM 的影响。特征空间编码器为全连接层,将 H d H_d Hd 个输入通道映射到 O = 64 O = 64 O=64 个输出通道;特征空间解码器则为全连接层,将 O O O 个输入通道映射回 H d H_d Hd 个输出通道;矩阵 C ∈ R O × O C \in \mathbb{R}^{O \times O} C∈RO×O 的权重也是可学习的。所有权重初始化为服从正态分布 N ( 0 , 0.02 ) N(0, 0.02) N(0,0.02)。训练共进行 20 个 epoch,初始学习率为 5 × 10 − 5 5 \times 10^{-5} 5×10−5,每个 epoch 衰减 0.99。
RM 的输入为拼接后的 G i I ( t ) G^I_i(t) GiI(t) 和 M i I ( t ) M^I_i(t) MiI(t),使用 ReLU 激活函数。采用 Adam 优化器,学习率为 10 − 3 10^{-3} 10−3,训练 10 个 epoch,损失函数为均方误差(MSE)。整个实现基于 PyTorch(2018)并在 NVIDIA A100 GPU 上完成。RM 在不含异常的基准视频上训练。RM 层数对性能的影响将在附录 F 中展示。系统效率的评估详见附录 H。
4.2 与基线方法比较
(COMPARISONS WITH BASELINES)
我们在 ShanghaiTech、Avenue、UCSD Ped2、Ubnormal、NWPU、UCF-Crime 和 XD-Violence 数据集上将我们的方法与现有无监督和弱监督方法进行比较,如表 1 所示。对于无监督方法,模型仅使用正常样本训练,而弱监督方法使用视频级标签。我们的方法在这些设置下表现均优,体现出强泛化能力。我们还在 ShanghaiTech、UCF-Crime 和 XD-Violence 数据集上报告了我们模型的标准差。
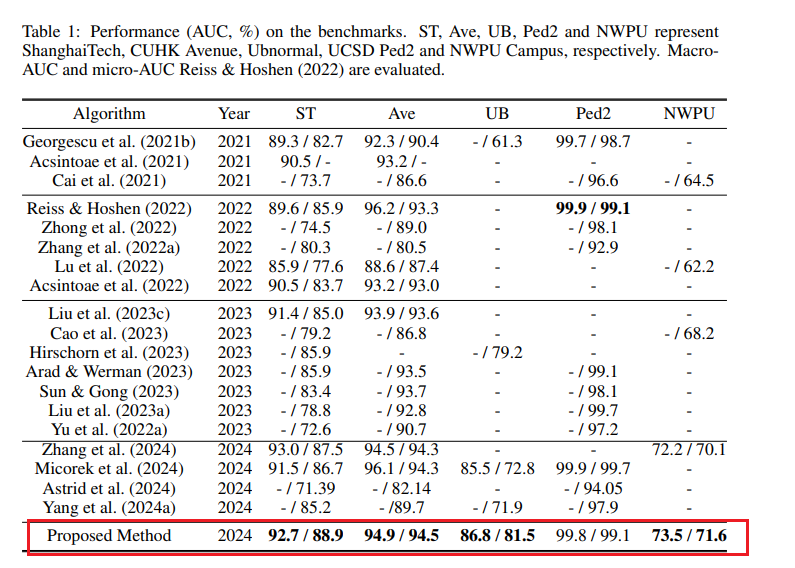
表 1:我们的方法与最新无监督和弱监督方法在 ShanghaiTech、Avenue、UCSDPed2、Ubnormal、NWPU、UCF-Crime 和 XD-Violence数据集上的比较。我们的方法使用视频级标签训练,在所有数据集上均优于现有方法。对于 XDViolence 使用AP(平均精度)作为指标,其他使用 AUC(曲线下面积,%)。
4.3 与全局模式比较
(COMPARISON WITH GLOBAL PATTERNS)
在本节中,我们比较了我们提出的局部模式与由图像主干直接提取的全局模式的性能。具体而言,图像主干(ViT-L/14)直接从整张图像中提取全局表示,然后将其输入重建模块 RM 中训练。我们在多个数据集上进行了比较,结果如表 2 所示。我们提出的局部模式在所有数据集上均优于全局模式。这是因为局部模式能关注具有语义意义的区域,而不是背景,从而更好地泛化到未见异常上。
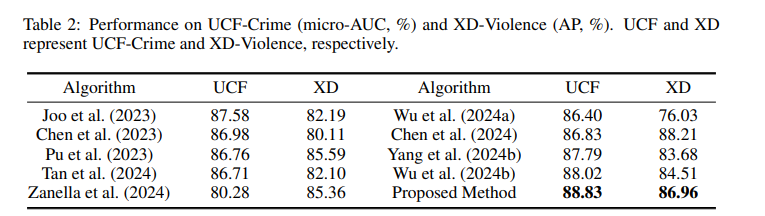
**表 2:我们提出的局部模式与图像主干提取的全局模式在各个数据集上的比较。**局部模式在所有数据集上均优于全局特征。
4.4 消融研究(ABLATION STUDIES)
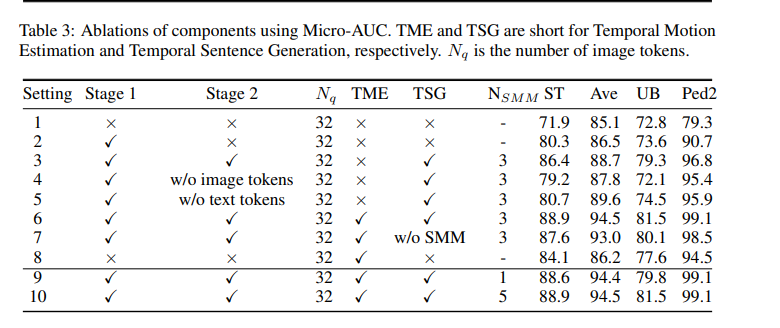
关于阶段 1 和阶段 2 的消融
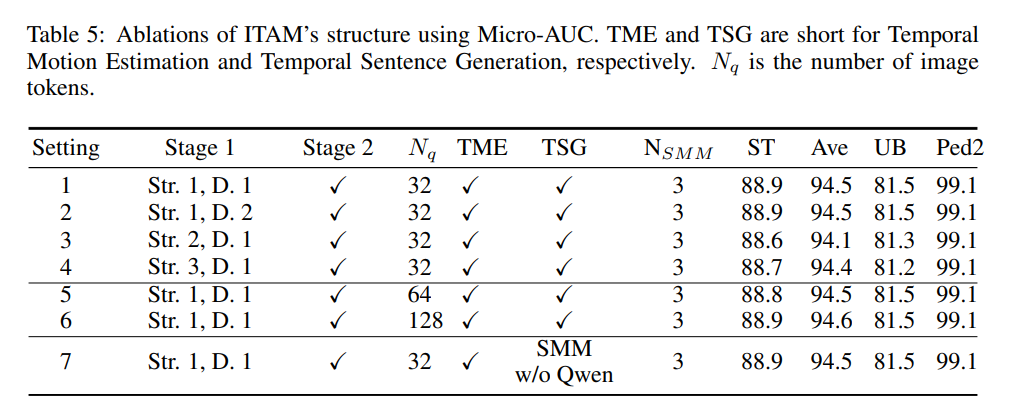
在表 3 的设置 1 中,使用主干特征 $H^I_i(t)$ 的重建误差来检测异常。设置 2 和设置 3 分别显示了阶段 1 和两个阶段在重建过程中的使用情况。对比结果表明,两个阶段在选择文本信息丰富的局部模式方面都发挥了关键作用,如图 4 所示。
关于 ITAM 结构的消融
为了表明图文对齐是泛化性能的主要贡献来源,而不是预训练模型本身,我们通过改变 ITAM 的结构和训练数据进行了消融研究。详细的结果和分析见附录 E。
关于跨模态注意力的消融
表 3 的设置 4 用来自 TSGM 的句子的文本特征 $F^T_i(t)$ 替换了设置 3 中的跨模态特征 $G^I_i(t)$,并使用 $F^T_i(t)$ 的重建误差来检测异常。设置 5 则舍弃了文本 token,仅使用 $F^I_i(t)$ 的重建误差。图 5 同样表明,结合视觉和文本特征比使用单一模态更具优势。
关于时间运动估计的消融
设置 6 相较于设置 3 的改进显示,时间动态性对异常检测中的局部模式具有互补作用。设置 8 展示了仅使用运动特征 $M^I_i(t)$ 的重建误差进行异常检测的效果。
关于阶段 2 中的 SMM 的消融
设置 6 与设置 7 的对比显示,如果 TSGM 仅使用 Q-Former(Li et al., 2023)进行基于图像的文本生成,而不通过 SMM 融合前一时刻的字幕信息,性能会下降。因此,不同时刻的图像 token 和文本 token 的混合输入,有助于生成更具信息量的句子。更多关于 SMM 的消融将在附录 B 中展示。
关于 SMM 结构的消融
SMM 堆叠了 $N_{\text{SMM}}$ 个状态机,每个状态机预测未来一个周期 $\Delta l/N_{\text{SMM}}$。该堆叠机制实现了对整体 $\Delta l$ 的预测。表 3 中的设置 6、9 和 10 显示 $N_{\text{SMM}} = 3$ 优于 $N_{\text{SMM}} = 1$。原因在于,状态机数量增多后,每个状态机只需关注短期依赖,从而任务更简单。而单个状态机难以同时建模短期和长期依赖,尤其是在我们所面临的非线性多模态依赖问题中表现尤为困难。
4.5 局部模式的主观可视化结果
(SUBJECTIVE RESULTS ON LOCAL PATTERNS)

图 4 展示了我们提出的局部模式在空间上的注意力图和字幕。为了可视化注意力图,我们根据 CMAM 输出的注意力分布,为每个图像 patch 指派热度值。我们进一步使用 CLIP 模型(Radford et al., 2021)将每个 patch 映射为图像嵌入,并与句子的嵌入进行余弦相似度计算以进行可视化。
图 4(上)表明,在我们提出的阶段一图文对齐过程中,图像 token 能够集中于语义上更重要的区域,例如异常行为的关键对象,而非背景。图 4(中)展示了我们方法在不同时间步生成的字幕 S i I ( t ) S^I_i(t) SiI(t),能够体现事件的演化,例如“一个男人正在走路”→“一个男人推着婴儿车在街上走”。图 4(下)展示了我们提出的 CMAM 如何关注语义区域,并成功去除冗余背景区域。
更多主观可视化示例将提供于附录 B 的图 10 和图 11 中。
4.6 失败案例分析
(FAILURE CASES)
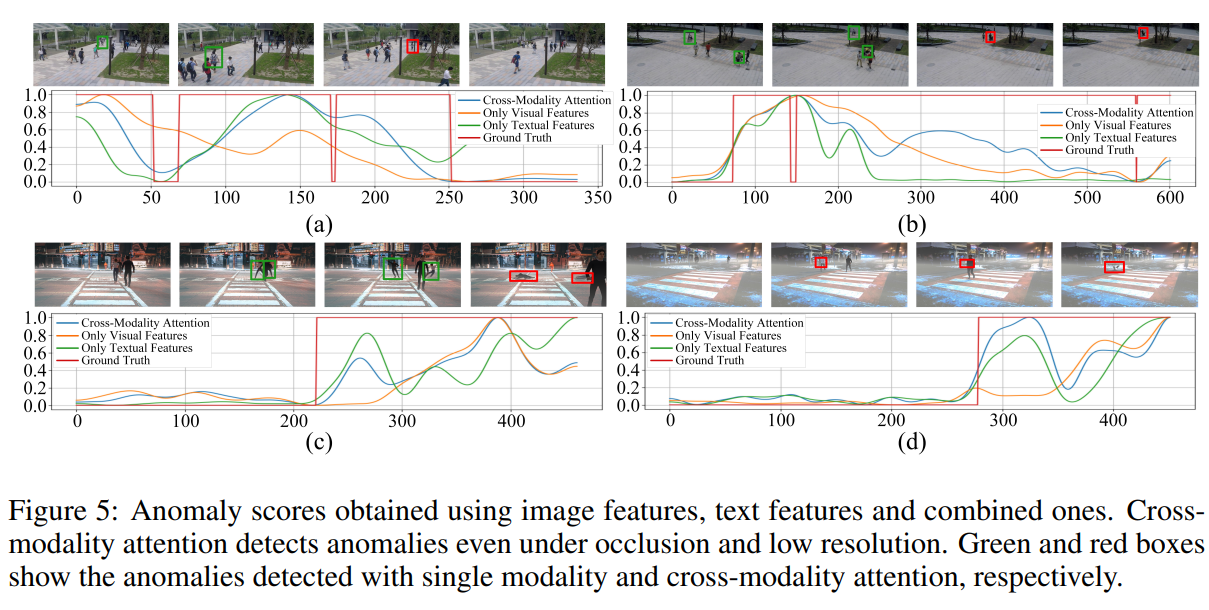
如图 5 所示,我们展示了来自 Ubnormal 数据集的失败案例。在场景一中,一名男子在街道上奔跑,模型错误地检测为正常。这是因为训练集中有多个 “奔跑” 的例子,例如奔跑进行运动锻炼或奔向公交车。然而,在该视频中,奔跑其实是由于 “逃跑” 的异常原因导致的,语义上具有攻击性或危险性。该样本的失败揭示了 “奔跑” 这一动作在正常与异常之间存在语义模糊地带,从而加大了检测难度。该问题可通过进一步注入上下文信息或事件动机进行缓解。
在场景二中,一名女子与汽车发生碰撞,但由于两个物体之间缺少显式交互建模,模型未能检测到异常。该问题暴露了我们方法的局限性:虽然局部模式可提取空间语义区域,但当多个对象间的交互行为构成异常时,建模就变得更加复杂。这可以通过引入关系建模模块或多对象交互表示进一步改进。
更多失败案例及分析详见附录 B 的图 12 和图 13。
5 结论
(CONCLUSION)
本文提出了一种识别局部模式的两阶段方法,旨在泛化至新颖异常。该方法首先使用图像-文本对齐定位图像中具有语义信息的局部模式,随后通过跨模态注意力机制进一步聚焦关键区域并精炼其表示。为了增强时序一致性,我们设计了状态机模块(SMM),该模块结合前后时间步的图像与文本 token,生成更准确且连贯的字幕。此外,我们还引入时间运动估计(TME)来补充空间信息,捕捉动态性变化。
实验结果表明,我们的方法在多个基准数据集上实现了当前最优性能。消融实验验证了我们方法各组成部分的有效性,而可视化和失败案例分析进一步展示了局部模式在异常检测任务中的解释性与优势。未来的工作将聚焦于建模多对象间的交互关系以及将事件动机纳入表示学习框架。
思考:挺有想法的一篇论文,聚合相邻帧的图像特征及字幕特征,和当前帧的图像特征和字幕特征,判断这两帧是否发生了同一个事件,对于从patch的维度分析图像特征,从token的维度分析字幕特征,并进行跨模态的注意力机制来实现交互融合。这样做可以实现更加完整的字幕特征以及对于字幕也有了时间信息。
附录(Appendix)
A SMM 中状态向量演化的推导
A DERIVATION OF STATE VECTOR EVOLUTION IN SMM
本节推导了状态向量 c i ( l ) c_i(l) ci(l) 的演化过程。在 SMM 中,输入序列 V i ( t ) V_i(t) Vi(t) 被视为 H d H_d Hd 个一维信号的集合,每个信号长度为 L L L。我们使用 O O O 个长度为 L L L 的勒让德(Legendre)多项式基函数 g o ( l ) ∗ o = 1 O {g_o(l)}*{o=1}^O go(l)∗o=1O 来近似每个信号。对于第 o o o 个基函数,第 i i i 个图像区域在时间 t t t 的状态向量 c i ( l ) c_i(l) ci(l) 的每个分量 c ∗ i , o ( l ) c*{i,o}(l) c∗i,o(l) 被用作加权系数:
u i , o ( l ′ ) = c i , o ( l ) g o ( l ′ − l + L ) , o ∈ [ 1 , O ] , l ′ ∈ ( l − L , l ] u_{i,o}(l') = c_{i,o}(l) g_o(l' - l + L), \quad o \in [1, O], \ l' \in (l - L, l] ui,o(l′)=ci,o(l)go(l′−l+L),o∈[1,O], l′∈(l−L,l]
状态向量 c i ( l ) c_i(l) ci(l) 用于表示输入序列 V i ( t ) V_i(t) Vi(t) 在最近 L L L 个时间步内的子序列依赖。其演化方式如下:
c i ( l + 1 ) = A c i ( l ) + B ∑ o = 1 O u i , o ( l + 1 ) c_i(l+1) = A c_i(l) + B \sum_{o=1}^O u_{i,o}(l+1) ci(l+1)=Aci(l)+Bo=1∑Oui,o(l+1)
其中, A ∈ R O × O A \in \mathbb{R}^{O \times O} A∈RO×O 和 B ∈ R O × 1 B \in \mathbb{R}^{O \times 1} B∈RO×1 是由勒让德多项式导出的参数。我们定义了如下的离散逼近:
c i ( l + Δ ) − c i ( l ) Δ ≈ 1 2 ( A c i ( l ) + B ∑ o u i , o ( l ) + A c i ( l + Δ ) + B ∑ o u i , o ( l + Δ ) ) \frac{c_i(l+\Delta) - c_i(l)}{\Delta} \approx \frac{1}{2} \left( A c_i(l) + B \sum_o u_{i,o}(l) + A c_i(l+\Delta) + B \sum_o u_{i,o}(l+\Delta) \right) Δci(l+Δ)−ci(l)≈21(Aci(l)+Bo∑ui,o(l)+Aci(l+Δ)+Bo∑ui,o(l+Δ))
令 Δ = 1 \Delta = 1 Δ=1 并整理可得:
c i ( l ) = ( I + 1 2 A ) ( I − 1 2 A ) − 1 c i ( l − 1 ) + B ( I − 1 2 A ) − 1 ∑ o u i , o ( l ) c_i(l) = \left(I + \frac{1}{2} A \right)\left(I - \frac{1}{2} A \right)^{-1} c_i(l - 1) + B \left(I - \frac{1}{2} A \right)^{-1} \sum_o u_{i,o}(l) ci(l)=(I+21A)(I−21A)−1ci(l−1)+B(I−21A)−1o∑ui,o(l)
即我们最终形式为:
c i ( l ) = A c i ( l − 1 ) + B ∑ o u i , o ( l ) c_i(l) = A c_i(l - 1) + B \sum_o u_{i,o}(l) ci(l)=Aci(l−1)+Bo∑ui,o(l)
其中 A = A Legendre ( O , L ) A = A_{\text{Legendre}}(O, L) A=ALegendre(O,L), B = B Legendre ( O , L ) B = B_{\text{Legendre}}(O, L) B=BLegendre(O,L),由勒让德多项式决定。
B 使用 SMM 的时间句子生成主观可视化结果
B SUBJECTIVE RESULTS OF TEMPORAL SENTENCE GENERATION WITH SMM
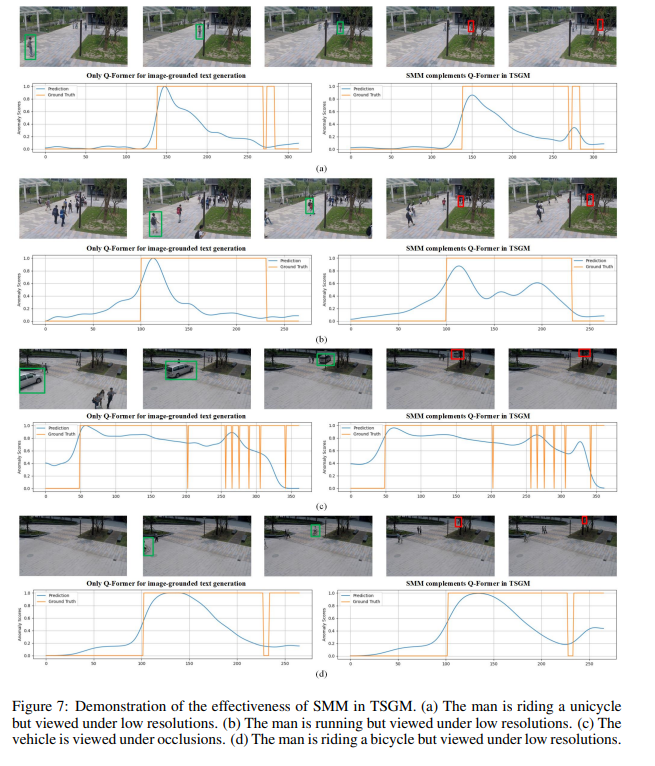
图 7 显示了时间句子生成模块(TSGM)在有无 SMM 的情况下对异常检测能力的影响。绿色框表示使用 Q-Former(Li et al., 2023)直接进行图像描述生成时能检测到的异常;红色框表示只有在加入 SMM 后才能检测出的异常。曲线表示异常分数。在遮挡、低分辨率等观测条件较差的情境下,SMM 能有效增强 Q-Former 的描述能力,从而提升检测性能。
C 图文对齐与图像引导文本生成模块结构
C STRUCTURES OF MODULES FOR IMAGE-TEXT ALIGNMENT AND IMAGE-GROUNDED TEXT GENERATION
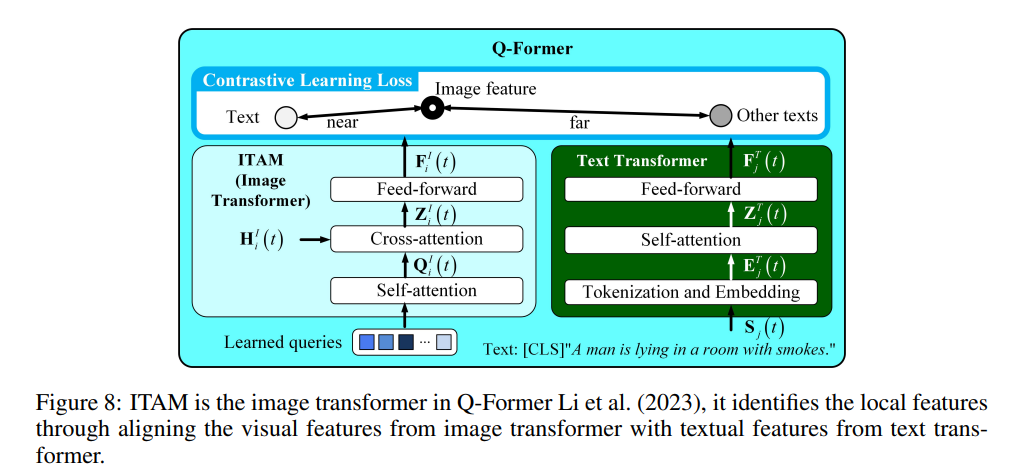
ITAM 即为 Q-Former 的图像 Transformer(Li et al., 2023),如图 8 所示,其输出为 F i I ( t ) ∈ R N q × H d F^I_i(t) \in \mathbb{R}^{N_q \times H_d} FiI(t)∈RNq×Hd,在训练期间对齐于 Q-Former 的文本 Transformer 输出,从而学习图文对齐的特征。图 2 中的文本 tokenizer 也是 Q-Former 文本 Transformer 的一部分。在本工作中,ITAM 和文本 tokenizer 均被冻结。
图像 Transformer 结构:
用于从 H i I ( t ) H^I_i(t) HiI(t) 中提取具有字幕信息的局部模式。其结构由 6 层 Transformer 组成,每层包括自注意力层、交叉注意力层和前馈层。在自注意力中, N q N_q Nq 个可学习的 query 先进行自注意力,再与 H i I ( t ) H^I_i(t) HiI(t) 进行交叉注意力。每个 query 的维度为 H d H_d Hd。
D 对目标检测方法的消融研究
表 4 展示了使用 VLM(Bai et al., 2023)、YOLO(Wang et al., 2023)以及滑动窗口进行目标检测的比较。具体而言,滑动窗口的大小固定如下:ShanghaiTech 为 224,CUHK Avenue 为 320,Ubnormal 为 320,UCSD Ped2 为 60,NWPU Campus 为 224,旨在覆盖最大的目标。结果表明,有效的目标检测对于准确性至关重要。此外,带有和不带有边界框扩展设置之间的对比表明,边界框扩展有助于捕捉更多上下文信息,从而提升性能。
附录 E:ITAM 结构的消融研究
(E ABLATION STUDY ON ITAM’S STRUCTURE)
表 5 展示了 ITAM 结构与训练数据对性能的影响。设置 1 是默认设置,使用“Str. 1”和“D. 1”。“Str. 1”表示第 3.2 节中 Li et al. (2023) 所描述的结构,“D. 1”表示使用 BLIP-2(Li et al., 2023)的训练数据。在“Str. 1”结构中,图像特征提取器包含 6 层 Transformer,每层包含一个自注意力层、一个交叉注意力层以及一个前馈层。自注意力层与交叉注意力层均使用 12 个头。在“Str. 2”中,将注意力头数更改为 6,其余设置保持不变。在“Str. 3”中,将连续 Transformer 层数更改为 3,其余超参数保持不变。
“D. 2”是指 ITAM 在每项实验的异常检测基准数据集的训练集上进行训练的配置。这些训练集仅包含正常事件。基准训练数据上的字幕标签是通过在正常视频上运行预训练的 BLIP-2 模型(Li et al., 2023)生成的。可以看到,只要进行了图文对齐,结构和数据的变化对性能影响不大。更重要的是,ITAM 可以使用正常数据进行训练,并检测从未见过的异常。
设置 5 和 6 显示图像 token 数量 N q N_q Nq 对性能影响不显著。设置 7 表明如果 SMM 使用 Lin et al. (2014) 的数据集生成的字幕标签进行训练,而不需要使用 Qwen-Chat,性能不会受到影响。例如,如果某张图像的字幕标签是“The man is running”,这会促使 SMM 输出“yes”,然后我们随机采样另一条具有不同含义的句子,例如“The man is fighting”,这将导致 SMM 输出“no”。实现基于 NLTK 库(Hardeniya et al., 2016)完成。
G:TSGM 中陈述句到疑问句的生成过程
(G PROCEDURES FOR GENERATING QUESTIONS IN TSGM)
如图 2(b) 所示,TSGM 首先将陈述句 “The man is pushing a stroller on the street.” 转换为疑问句 “Is the man pushing a stroller on the street?”。该转换基于 NLTK 库(Hardeniya et al., 2016),其过程如下的算法 2 所示:
算法 2:将陈述句转换为疑问句的算法
1: 输入句子:
D ← S i I ( t − 1 ) = ‘The man is pushing a stroller on the street.’ D \leftarrow S^I_i(t - 1) = \text{‘The man is pushing a stroller on the street.’} D←SiI(t−1)=‘The man is pushing a stroller on the street.’
2: 分词:
D → [ ‘The’ , ‘man’ , ‘is’ , ‘pushing’ , ‘a’ , ‘stroller’ , ‘on’ , ‘the’ , ‘street’ , ‘.’ ] D \rightarrow [\text{‘The’}, \text{‘man’}, \text{‘is’}, \text{‘pushing’}, \text{‘a’}, \text{‘stroller’}, \text{‘on’}, \text{‘the’}, \text{‘street’}, \text{‘.’}] D→[‘The’,‘man’,‘is’,‘pushing’,‘a’,‘stroller’,‘on’,‘the’,‘street’,‘.’]
3: 定位第一个动词:
D firstverb = ‘is’ D_{\text{firstverb}} = \text{‘is’} Dfirstverb=‘is’
4: 使用第一个动词划分句子:
D → D 1 + D firstverb + D 2 D \rightarrow D_1 + D_{\text{firstverb}} + D_2 D→D1+Dfirstverb+D2,其中 D 1 = ‘The man’ , D 2 = ‘pushing a stroller on the street’ D_1 = \text{‘The man’}, D_2 = \text{‘pushing a stroller on the street’} D1=‘The man’,D2=‘pushing a stroller on the street’
5: 交换各部分顺序:
Q ← D firstverb + D 1 + D 2 Q \leftarrow D_{\text{firstverb}} + D_1 + D_2 Q←Dfirstverb+D1+D2
6: 返回 Q Q Q
该过程将一个描述事件的陈述句(用于表示已观察到的事件)转换为疑问句,用于让模型判断当前帧中该事件是否仍在发生。
J:未来工作
(J FUTURE WORK)
当前框架的一项局限性是对目标检测器的依赖。目前,视觉-语言模型(Vision-Language Models,VLMs)的性能受其视野范围限制。例如,在处理包含广阔场景的图像时,视觉-语言模型往往忽略许多细节,这突显了目标检测器的必要性——它们有助于独立处理局部区域。
表 4 显示,目标检测器的性能显著优于滑动窗口,后者较差的表现可能源于其策略不当。因此,我们将探索在复杂场景和包含多个目标的大视野图像中,解析事件的更高效、效果更好的方法。
具体来说,我们将探索在端到端的大模型中整合目标检测器的方式。在较简单、目标较少的场景中,输入图像将被嵌入较少数量的视觉 token;而在场景变得更复杂、包含更多目标的情况下,输入图像将被编码为更多个视觉 token,其中每个 token 描述一个或多个对象。
此外,我们还将探索提升效率的方法。



















