引子
前文写到RagFlow的环境搭建&推理测试,感兴趣的童鞋可以移步(RagFlow环境搭建&推理测试-CSDN博客)。前文也写过RagFLow参数配置&测试的文档,详见(RagFlow环境搭建&推理测试-CSDN博客)。很少写关于具体代码的blog,这个不涉密,OK,那我们开始吧。
一、RagFlow检索优化--ES替换为Infitity
在上一篇文章中,我尝试新建了两个知识库,一个知识库中有两个文档,其中一个比较大,另外一个知识库上传的时QA对的excel表格。我在聊天设置中选择了两个知识库,我提出文档,到得到答案差不多要3mins,这个。。。呃,需要排查下。那我们就采用控制变量法来找到问题原因吧,既然时两个知识库,那我们先删除一个QA对知识库。。。好家伙,提出一个问题,依然需要3mins才出答案。那我们继续,剩下的一个知识库中两个文档,那我们先禁用一个长的文档,来看看效果。呃。。时间略快一点,还是要2mins。
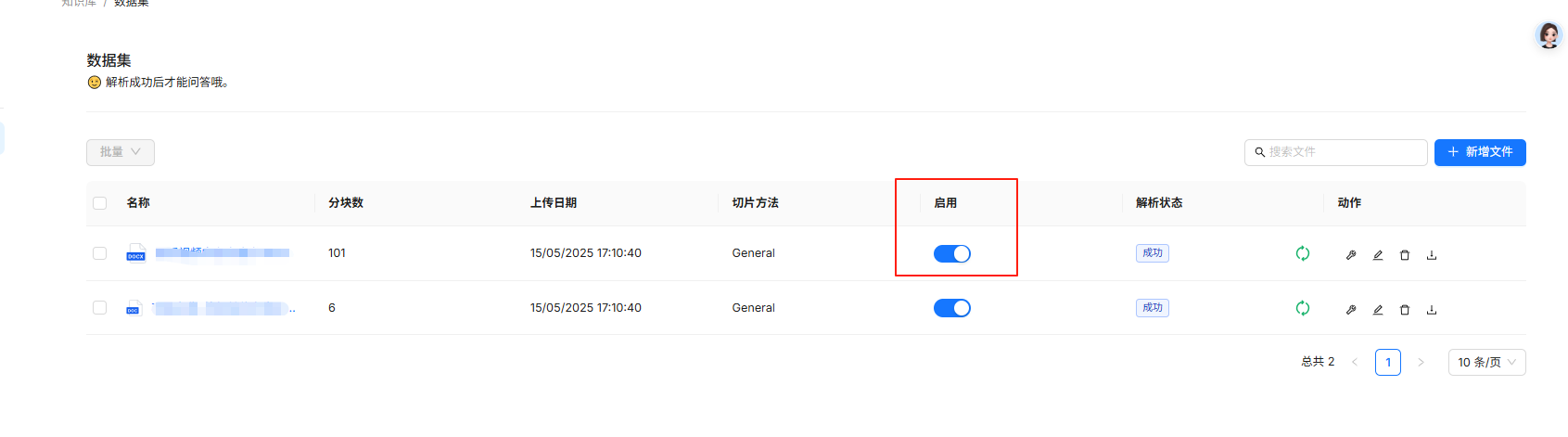
根据上一篇博客里所讲,我这里选择了reranker模型,那么在混合查询中的向量相似度部分将被rerank打分代替。那就去掉rerank,我们再测试下,emm 。。。时间略有缩短,可以看到显示搜索中这个过程十分耗时。当然有可能是我的机器配置比较差的缘故,但进一步分析,目前设置是使用关键词相似度与向量余弦相似度相结合的混合查询方式。采用的是ES数据库的查询结果计算的。
刚好看到RagFlow中配置文档中有替换Infinity的部分,那就先来了解下Infinity到底是什么。
开源 AI 原生数据库 Infinity,23年12月 正式开源发布,提供了 2 种新数据类型:稀疏向量 Sparse Vector 和 张量 Tensor,在此前的全文搜索和向量搜索之外, Infinity 提供了更多的召回手段,如下图所示,用户可以采用任意 N 路召回(N ≥ 2)进行混合搜索,这是目前功能最强大的 RAG 专用数据库。
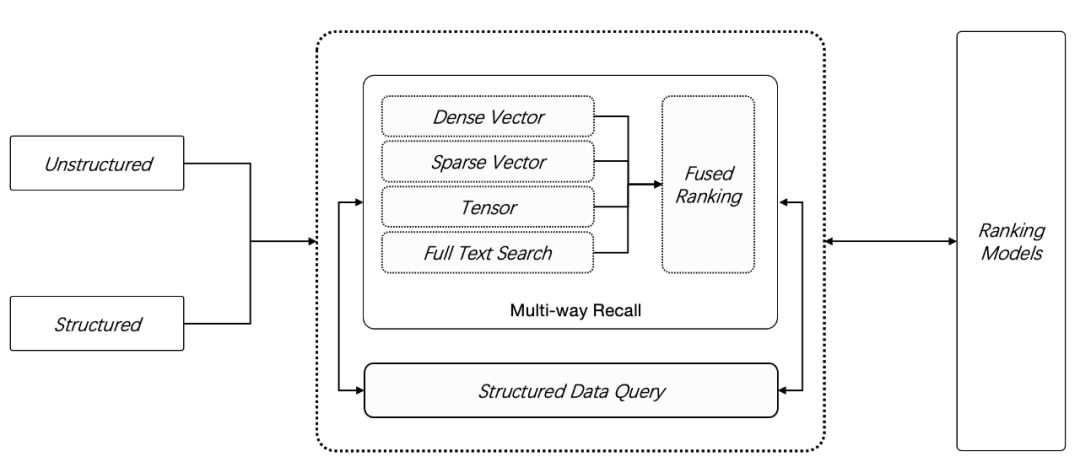
我们知道,仅仅依靠向量搜索(默认情况下,它用来特指稠密向量)并不总能提供令人满意的结果。当用户问题中的特定关键词与存储的数据不准确匹配时,这种问题尤为明显。这是因为向量本身不具备精确语义表征能力:一个词,一句话,乃至一篇文章,都可以只用一个向量来表示,这时向量本质上表达的是这段文字的“语义”,也就是这段文字跟其他文字在一个上下文窗口内共同出现概率的压缩表示 ,因此向量天然无法表示精确的查询。例如如果用户询问“2024 年 3 月我们公司财务计划包含哪些组合”,那么很可能得到的结果是其他时间段的数据,或者得到运营计划,营销管理等其他类型的数据。
因此,在一种好的解决方案是,利用基于关键词的全文搜索提供精确查询,它跟向量搜索共同工作,这就是全文搜索 + 向量搜索 的 2 路召回,又被称为混合搜索(hybrid search)。
多了 那么多我们来看下ES和Infinity执行效率上的对比吧。如下图:

我们可以看到infinity的执行效率是Especially的40倍左右,那我们就替换下试试。
关闭docker容器
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml down -v
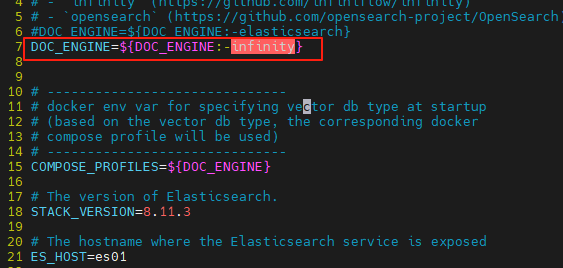
修改参数
vi .env
重启容器
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml up -d

会去拉取infinity的docker镜像,更新之后,速度果然大幅度提升,几秒内响应。
二、代码解析
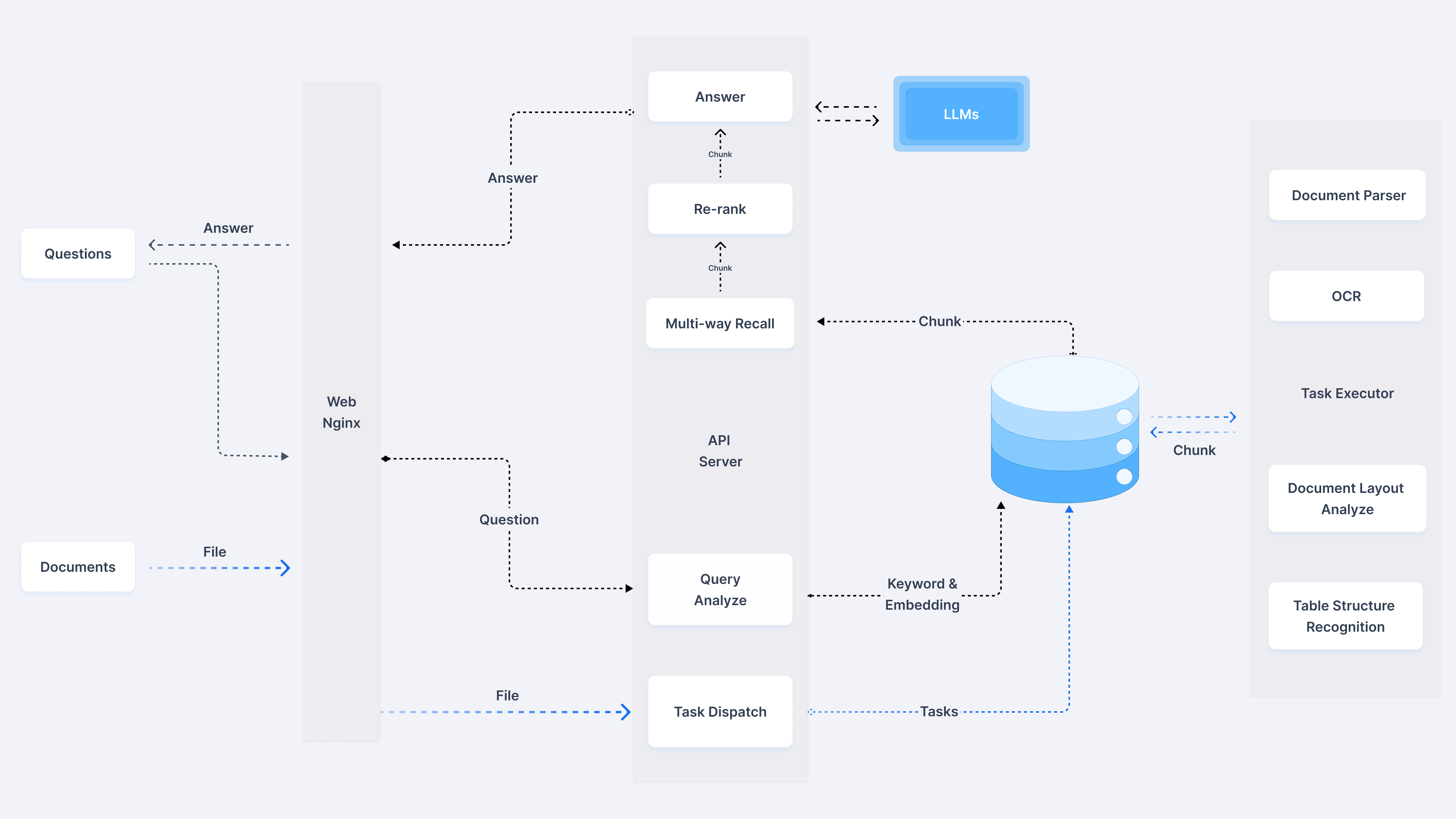
1、整体架构
我们从官方的架构图入手,我们可以看到从左往右,是我们在实际在线应用的时候的流程架构,从右到左,是知识库离线生成的流程架构。很明显,这张图中把知识库部分画的很大,彰显它在整个RagFlow项目中的核心地位。于此同时,最右侧详细介绍了文件解析的各种手段,比如 OCR, Document Layout Analyze 等,这些在常规的 RAG 中可能会作为一个不起眼的 Unstructured Loader 包含进去,可以猜到 RagFlow 的一个核心能力在于文件的解析环节。在官方文档中也反复强调 Quality in, quality out, 反映出 RAGFlow 的独到之处在于细粒度文档解析。另外文档中提到其没有使用任何 RAG 中间件,而是完全重新研发了一套智能文档理解系统,并以此为依托构建 RAG 任务编排体系,也可以理解文档的解析是其 RagFlow 的核心亮点。
2、代码结构
我们来看看代码结构(版本:v0.18.0)
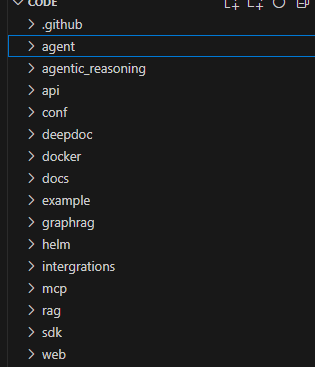
agent:RagFlow新增的一个模块,即工作流(注:实际上工作流和agent不是一个概念,agent可以作为workflow的一部分),通过“Graph"是一个由节点和边组成的数学概念。它被用来构建复杂的工作流或代理。
agentic_reasoning:代理推理
api:后端的 API
conf :配置信息
deepdoc: 文件解析模块
docker:docker配置安装启动部署文件
docs:文档
example:案例
graphrag:图rag
helm:打包管理工具
intergreations:集成插件工具
mcp:模型上下文协议
web:对应的是前端页面,TypeScript 开发
其他的一些技术中间件
Web 服务:Flask
业务数据库:Mysql
向量数据库: ElasticSearch (常规关键词搜索用的也是它),前文已经替换 infinity
文件存储: MinIO,支持分布式存储
缓存中间件:valkey/valkey:8 是从 Redis 7.2.4 fork 而来,旨在作为 Redis 的开源替代品,特别是在 Redis Labs 更改了 Redis 的源码使用协议之后。它保持了与 Redis 的兼容性,同时引入了许多性能和功能上的改进。在网络应用中,Valkey 可以用作缓存、消息队列、会话存储等多种用途,适用于需要快速数据访问和低延迟的场景。
3、源码解析
(1)加载文件
常规的 RAG 服务都是在上传时进行文件的加载和解析,但是 RAGFlow 的上传仅仅包含上传至 MinIO,需要手工点击触发文件的解析。根据实际体验,RAGFlow 的解析相当慢,资源开销也比较大,所以这就是采取二次手工确认的产品方案的原因吧。

实际的文件解析通过接口 /v1/document/run 进行触发的,实际的处理是在 api/db/services/task_service.py 中的 queue_tasks() 中完成的,此方法会根据文件创建一个或多个异步任务,方便异步执行。实现如下所示:
def queue_tasks(doc: dict, bucket: str, name: str, priority: int):def new_task():return {"id": get_uuid(), "doc_id": doc["id"], "progress": 0.0, "from_page": 0, "to_page": 100000000}parse_task_array = []# pdf 文件的解析,根据不同的类型设置单个任务最多处理的页数# 默认单个任务处理 12 页 pdf,paper 类型的 pdf 一个任务处理 22 页,其他 pdf 不分页if doc["type"] == FileType.PDF.value:file_bin = STORAGE_IMPL.get(bucket, name)do_layout = doc["parser_config"].get("layout_recognize", "DeepDOC")pages = PdfParser.total_page_number(doc["name"], file_bin)page_size = doc["parser_config"].get("task_page_size", 12)if doc["parser_id"] == "paper":page_size = doc["parser_config"].get("task_page_size", 22)if doc["parser_id"] in ["one", "knowledge_graph"] or do_layout != "DeepDOC":page_size = 10 ** 9page_ranges = doc["parser_config"].get("pages") or [(1, 10 ** 5)]for s, e in page_ranges:s -= 1s = max(0, s)e = min(e - 1, pages)for p in range(s, e, page_size):task = new_task()task["from_page"] = ptask["to_page"] = min(p + page_size, e)parse_task_array.append(task)# 表格数据单个任务处理 3000 行elif doc["parser_id"] == "table":file_bin = STORAGE_IMPL.get(bucket, name)rn = RAGFlowExcelParser.row_number(doc["name"], file_bin)for i in range(0, rn, 3000):task = new_task()task["from_page"] = itask["to_page"] = min(i + 3000, rn)parse_task_array.append(task)else:parse_task_array.append(new_task())chunking_config = DocumentService.get_chunking_config(doc["id"])# 任务插入 Redis 消息队列,方便异步处理for task in parse_task_array:hasher = xxhash.xxh64()for field in sorted(chunking_config.keys()):if field == "parser_config":for k in ["raptor", "graphrag"]:if k in chunking_config[field]:del chunking_config[field][k]hasher.update(str(chunking_config[field]).encode("utf-8"))for field in ["doc_id", "from_page", "to_page"]:hasher.update(str(task.get(field, "")).encode("utf-8"))task_digest = hasher.hexdigest()task["digest"] = task_digesttask["progress"] = 0.0task["priority"] = priorityprev_tasks = TaskService.get_tasks(doc["id"])ck_num = 0if prev_tasks:for task in parse_task_array:ck_num += reuse_prev_task_chunks(task, prev_tasks, chunking_config)TaskService.filter_delete([Task.doc_id == doc["id"]])chunk_ids = []for task in prev_tasks:if task["chunk_ids"]:chunk_ids.extend(task["chunk_ids"].split())if chunk_ids:settings.docStoreConn.delete({"id": chunk_ids}, search.index_name(chunking_config["tenant_id"]),chunking_config["kb_id"])DocumentService.update_by_id(doc["id"], {"chunk_num": ck_num})bulk_insert_into_db(Task, parse_task_array, True)DocumentService.begin2parse(doc["id"])unfinished_task_array = [task for task in parse_task_array if task["progress"] < 1.0]for unfinished_task in unfinished_task_array:assert REDIS_CONN.queue_product(get_svr_queue_name(priority), message=unfinished_task), "Can't access Redis. Please check the Redis' status."从上面的实现来看,文件的解析是根据内容拆分为多个任务,通过 Redis 消息队列进行暂存(生产者),之后就可以离线异步处理。直接查看对应的消息队列的消费模块(消费者),对应在 rag/svr/task_executor.py 中的 main() 方法中。实现如下所示:
async def main():logging.info(r"""______ __ ______ __/_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____/ / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___// / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
/_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/""")logging.info(f'TaskExecutor: RAGFlow version: {get_ragflow_version()}')settings.init_settings()print_rag_settings()if sys.platform != "win32":signal.signal(signal.SIGUSR1, start_tracemalloc_and_snapshot)signal.signal(signal.SIGUSR2, stop_tracemalloc)TRACE_MALLOC_ENABLED = int(os.environ.get('TRACE_MALLOC_ENABLED', "0"))if TRACE_MALLOC_ENABLED:start_tracemalloc_and_snapshot(None, None)signal.signal(signal.SIGINT, signal_handler)signal.signal(signal.SIGTERM, signal_handler)threading.Thread(name="RecoverPendingTask", target=recover_pending_tasks).start()async with trio.open_nursery() as nursery:nursery.start_soon(report_status)while not stop_event.is_set():async with task_limiter:nursery.start_soon(handle_task)logging.error("BUG!!! You should not reach here!!!")
)











)





