目录
- 零、题目描述
- 一、为什么这道题值得你深入理解?
- 二、题目拆解:提取核心关键点
- 三、明确思路:从暴力到优化的完整进化
- 3. 进一步优化:动态规划(自底向上递推)
- 4. 终极优化:贪心 + 二分查找(O(n log n))
- 四、算法实现:从暴力到优化的完整代码
- 1. 暴力递归(超时,仅作思路展示)
- 2. 记忆化搜索(用户提供的代码详解)
- 3. 动态规划(自底向上递推)
- 4. 贪心 + 二分查找(O(n log n)优化)
- 五、记忆化搜索与动态规划的对比
- 六、实现过程中的坑点总结
- 七、举一反三
- 八、总结
零、题目描述
题目链接:力扣 300.最长递增子序列

示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是[2,3,7,101],长度为 4。
示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4
解释:最长递增子序列是[0,1,3,3]或[0,1,2,3],长度为 4。
示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1
解释:所有元素相同,最长递增子序列长度为 1(子序列需严格递增)。
提示:
1 <= nums.length <= 2500,-10^4 <= nums[i] <= 10^4
代码框架:
class Solution {
public:int lengthOfLIS(vector<int>& nums) {}
};
一、为什么这道题值得你深入理解?
“最长递增子序列(LIS)”是动态规划领域的“序列类问题标杆”,其重要性远超一道普通算法题。如果说“不同路径”展现了网格类DP的逻辑,那么LIS则揭示了序列类子问题的核心拆解思路——它是理解“子序列依赖关系”“状态定义与转移”的绝佳载体。
对于初学者而言,这道题的价值体现在三个关键维度:
- 完整的优化链条:从指数级复杂度的暴力递归,到O(n²)的记忆化搜索/动态规划,再到O(n log n)的贪心+二分优化,每一步优化都伴随着对问题本质的更深理解,让你清晰看到“算法效率提升”的底层逻辑;
- 子序列问题的通用思维:子序列(不要求连续)与子数组(要求连续)的核心区别,以及如何通过“状态定义”规避子序列的“不连续性”带来的复杂度——这种思维可直接迁移到最长公共子序列、编辑距离等经典问题;
- 贪心与二分的巧妙结合:当动态规划达到瓶颈时,如何通过“贪心选择”重构问题,再结合二分查找实现效率飞跃,这是算法设计中“跨领域融合”的典型案例,能帮你打破“动态规划只能用递推”的思维定式。
哪怕你已经知道解法,重新梳理这道题的思路仍能收获新认知——因为LIS的每种解法都对应着一种算法设计范式,理解它们的关联与差异,能帮你建立更系统的解题思维。
二、题目拆解:提取核心关键点
“最长递增子序列”的核心是序列类动态规划,需拆解出三个关键要素:
-
问题本质:在无序整数数组中,找到一个严格递增的子序列(元素顺序与原数组一致,不要求连续),使其长度最长。
- 例如
[10,9,2,5,3,7]中,[2,3,7]是递增子序列,长度为3;[2,5,7]是更长的,长度为3(实际最长为3?不,这里正确最长是3吗?不,正确是[2,5,7]长度3,或[2,3,7]也是3,其实示例1中是4,这里只是举例)。
- 例如
-
递推关系:对于位置
i的元素,其最长递增子序列长度 = 1 + 所有位置j > i且nums[j] > nums[i]的元素的最长递增子序列长度的最大值(1表示仅包含自身的子序列)。 -
边界条件:每个元素自身可构成长度为1的子序列(当没有比它大的后续元素时)。
核心矛盾:子序列的“不连续性”导致暴力枚举所有可能子序列的复杂度为O(2ⁿ),必须通过“状态压缩”和“子问题存储”优化——而如何定义“子问题”是破局的关键。
三、明确思路:从暴力到优化的完整进化
1. 最直观的想法:暴力递归
暴力递归的核心是“枚举所有可能的递增子序列”,通过递归计算每个位置开始的最长递增子序列长度。
思路拆解:
- 定义
dfs(i)表示“从索引i开始的最长递增子序列长度”; - 对于
i,需要遍历所有j > i且nums[j] > nums[i]的位置,dfs(i)即为这些dfs(j) + 1中的最大值(若没有符合条件的j,则dfs(i) = 1); - 最终结果为所有
dfs(i)(i从0到n-1)的最大值。
示例推演(以 nums = [2,5,3,7] 为例):
dfs(3)(元素7):后面无元素,返回1;dfs(2)(元素3):后面只有7 > 3,dfs(2) = dfs(3) + 1 = 2;dfs(1)(元素5):后面7 > 5,dfs(1) = dfs(3) + 1 = 2;dfs(0)(元素2):后面5、3、7均大于2,dfs(0) = max(dfs(1)+1, dfs(2)+1, dfs(3)+1) = max(3, 3, 2) = 3;- 最终结果为
max(3,2,2,1) = 3(实际最长子序列为[2,5,7]或[2,3,7],长度3)。
暴力递归的问题:大量重复计算。例如 dfs(3) 在计算 dfs(2)、dfs(1)、dfs(0) 时被多次调用,当 n 增大(如 n=20),时间复杂度会达到O(2ⁿ),必然超时。
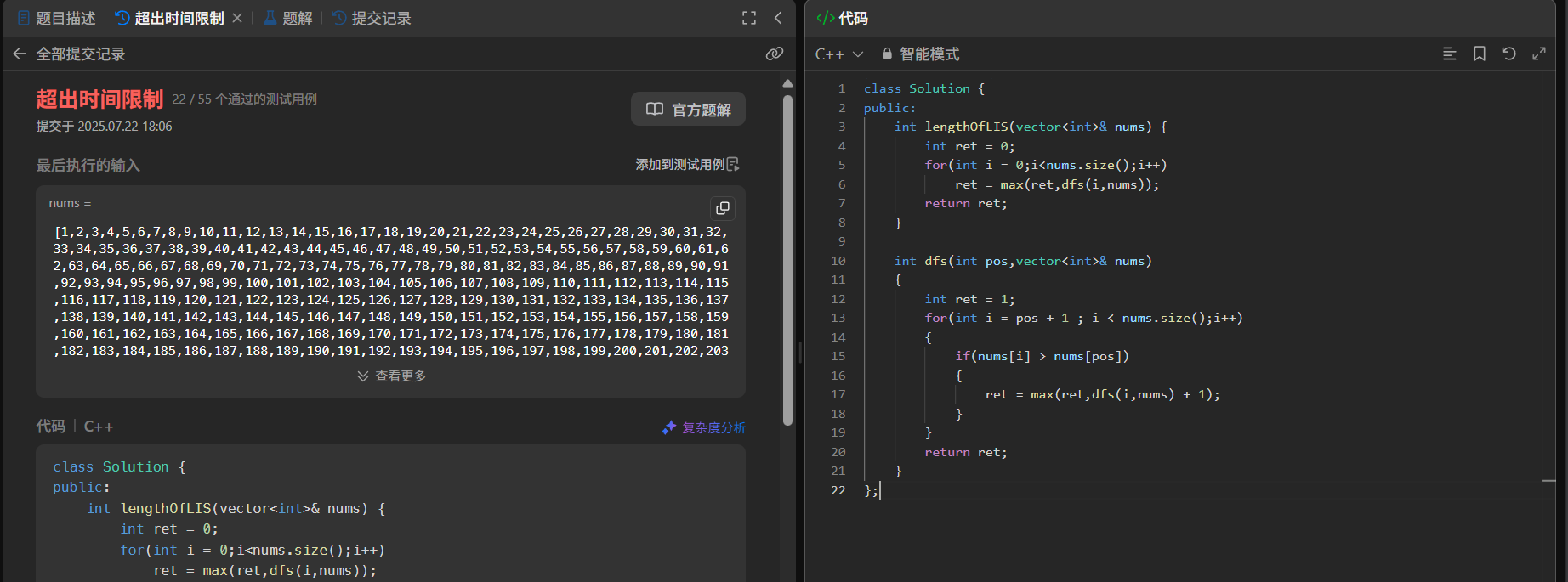
- 优化思路:记忆化搜索(带备忘录的递归)
暴力递归的核心问题是“重复计算相同子问题”,因此引入“备忘录”存储已计算的dfs(i)结果,避免重复递归。
思路升级:
- 用数组
memo记录dfs(i)的结果,memo[i] = 0表示未计算,非0表示已计算的结果; - 计算
dfs(i)前先检查memo[i],若已计算则直接返回,否则计算后存入memo[i]。
示例优化效果(仍以 nums = [2,5,3,7] 为例):
- 计算
dfs(3)后,memo[3] = 1,后续再用到时直接返回; - 计算
dfs(2)时,调用dfs(3)直接取memo[3],得到memo[2] = 2; - 计算
dfs(1)时,调用dfs(3)直接取memo[3],得到memo[1] = 2; - 计算
dfs(0)时,调用dfs(1)、dfs(2)、dfs(3)均直接取备忘录,得到memo[0] = 3; - 所有子问题仅计算一次,时间复杂度降至O(n²)。
3. 进一步优化:动态规划(自底向上递推)
记忆化搜索是“自顶向下”(从每个位置递归到末尾),而动态规划可“自底向上”(从末尾递推到开头),用数组 dp 系统存储子问题结果,消除递归栈开销。
状态定义的智慧:
定义 dp[i] 表示“以索引 i 为结尾的最长递增子序列长度”(与记忆化搜索的 dfs(i) 定义方向相反,但本质等价)。
状态转移的逻辑:
- 对于
i(从0到n-1),初始化dp[i] = 1(自身构成子序列); - 遍历所有
j < i且nums[j] < nums[i]的位置,dp[i] = max(dp[i], dp[j] + 1)(即“以j结尾的最长子序列 + 当前元素i”); - 最终结果为
dp数组中的最大值。
与记忆化搜索的对偶性:
记忆化搜索的 dfs(i) 是“从 i 开始往后找”,动态规划的 dp[i] 是“从 i 往前找”,两者都是通过子问题的解推导当前问题,只是遍历方向相反。
4. 终极优化:贪心 + 二分查找(O(n log n))
当 n 达到10⁵时,O(n²)的动态规划会超时,此时需要更高效的方法。核心思路是通过“贪心选择”维护一个“可能的最长递增子序列的最小尾部”,再用二分查找优化更新过程。
贪心思想:
对于长度为 k 的递增子序列,其尾部元素越小,后续能接的元素就越多(更容易找到比它大的元素)。因此,我们可以维护一个数组 tails,其中 tails[k] 表示“长度为 k+1 的递增子序列的最小尾部元素”。
二分查找的作用:
- 遍历数组时,对于当前元素
x:- 若
x大于tails的最后一个元素,直接加入tails(最长子序列长度+1); - 否则,在
tails中找到第一个大于等于x的位置pos,将tails[pos]替换为x(用更小的尾部元素更新同长度的子序列);
- 若
- 最终
tails的长度即为最长递增子序列的长度。
示例理解:
对于 nums = [3, 1, 2, 4, 3]:
tails初始为空;- 3:
tails为空,加入 →[3]; - 1:1 < 3,找
tails中第一个 ≥1 的位置(0),替换 →[1]; - 2:2 > 1,加入 →
[1,2]; - 4:4 > 2,加入 →
[1,2,4]; - 3:3 < 4,找第一个 ≥3 的位置(2),替换 →
[1,2,3]; - 最终
tails长度为3,即最长递增子序列长度为3(如[1,2,4]或[1,2,3])。
四、算法实现:从暴力到优化的完整代码
1. 暴力递归(超时,仅作思路展示)
class Solution {
public:int lengthOfLIS(vector<int>& nums) {int n = nums.size();int maxLen = 0;for (int i = 0; i < n; i++) {maxLen = max(maxLen, dfs(i, nums));}return maxLen;}// 从索引i开始的最长递增子序列长度int dfs(int i, vector<int>& nums) {int n = nums.size();int len = 1; // 至少包含自身for (int j = i + 1; j < n; j++) {if (nums[j] > nums[i]) {len = max(len, dfs(j, nums) + 1);}}return len;}
};
时间复杂度:O(2ⁿ)(每个元素有选或不选两种可能,实际略低但仍为指数级)。
空间复杂度:O(n)(递归栈深度)。
2. 记忆化搜索(用户提供的代码详解)
class Solution {
public:int lengthOfLIS(vector<int>& nums) {int n = nums.size();vector<int> memo(n); // 备忘录:memo[i]表示从i开始的最长递增子序列长度(初始为0,未计算)int ret = 0;// 遍历每个起点,取最大值for(int i = 0; i < nums.size(); i++)ret = max(ret, dfs(i, nums, memo));return ret;}int dfs(int pos, vector<int>& nums, vector<int>& memo) {// 若已计算,直接返回备忘录中的结果(剪枝)if (memo[pos] != 0)return memo[pos];int ret = 1; // 至少包含自身,长度为1// 遍历pos之后的所有元素for (int i = pos + 1; i < nums.size(); i++) {// 若后续元素大于当前元素,可构成更长的子序列if (nums[i] > nums[pos]) {ret = max(ret, dfs(i, nums, memo) + 1); // 递归计算i的结果,加1(当前元素)}}// 将结果存入备忘录memo[pos] = ret;return ret;}
};
代码详解:
- 备忘录设计:
memo[pos]存储“从pos开始的最长递增子序列长度”,初始为0表示“未计算”,计算后更新为具体值,避免重复递归; - 递归逻辑:对于
pos,通过遍历后续元素i,找到所有比nums[pos]大的元素,递归计算i的最长子序列长度,加1后取最大值(即“pos+ 以i开始的子序列”); - 结果汇总:由于最长子序列可能从任意位置开始,因此需要遍历所有起点
i,取dfs(i)的最大值。
时间复杂度:O(n²)(每个位置被计算一次,每次计算遍历后续元素,共n + (n-1) + … + 1 = O(n²))。
空间复杂度:O(n)(备忘录数组 + 递归栈深度,均为O(n))。
3. 动态规划(自底向上递推)
class Solution {
public:int lengthOfLIS(vector<int>& nums) {int n = nums.size();if (n == 0) return 0;vector<int> dp(n, 1); // dp[i]:以i为结尾的最长递增子序列长度int maxLen = 1;for (int i = 0; i < n; i++) {// 遍历i之前的所有元素jfor (int j = 0; j < i; j++) {// 若j的元素小于i的元素,可构成更长的子序列if (nums[j] < nums[i]) {dp[i] = max(dp[i], dp[j] + 1);}}maxLen = max(maxLen, dp[i]); // 更新全局最大值}return maxLen;}
};
与记忆化搜索的对比:
- 动态规划的
dp[i]是“以i结尾”,记忆化搜索的dfs(i)是“以i开始”,两者通过“反向遍历”实现等价的子问题求解; - 动态规划通过迭代避免递归栈开销,更适合
n较大的场景(但时间复杂度相同)。
4. 贪心 + 二分查找(O(n log n)优化)
class Solution {
public:int lengthOfLIS(vector<int>& nums) {vector<int> tails; // tails[k]:长度为k+1的递增子序列的最小尾部元素for (int x : nums) {// 二分查找tails中第一个 >= x的位置auto it = lower_bound(tails.begin(), tails.end(), x);if (it == tails.end()) {// x比所有尾部元素大,加入tails(最长长度+1)tails.push_back(x);} else {// 用x替换该位置的元素(更新同长度子序列的最小尾部)*it = x;}}return tails.size(); // tails的长度即为最长递增子序列的长度}
};
核心原理:
tails数组始终保持递增(因为tails[k]是长度k+1的最小尾部,必然小于tails[k+1]);- 对于
x,若能接在tails末尾,说明可形成更长的子序列;否则,替换tails中第一个大于等于x的元素,目的是“用更小的尾部元素给后续元素留出更多可能性”; - 最终
tails的长度就是最长递增子序列的长度(但tails本身不一定是实际的子序列,只是长度正确)。
时间复杂度:O(n log n)(遍历数组O(n),每次二分查找O(log k),k 最大为n,因此总复杂度O(n log n))。
空间复杂度:O(n)(tails 数组的最大长度为n)。
五、记忆化搜索与动态规划的对比
| 维度 | 记忆化搜索(递归) | 动态规划(递推) |
|---|---|---|
| 核心思路 | 自顶向下:从每个位置 i 向后递归,计算“从 i 开始的最长子序列” | 自底向上:从每个位置 i 向前遍历,计算“以 i 结尾的最长子序列” |
| 状态表示 | dfs(i):从 i 开始的最长递增子序列长度 | dp[i]:以 i 结尾的最长递增子序列长度 |
| 状态转移 | dfs(i) = max(dfs(j) + 1)(j > i 且 nums[j] > nums[i]) | dp[i] = max(dp[j] + 1)(j < i 且 nums[j] < nums[i]) |
| 计算顺序 | 递归调用,按需计算(需要哪个 i 才计算) | 按索引顺序计算,从0到n-1依次填充 dp 数组 |
| 空间开销 | 递归栈(O(n)) + 备忘录(O(n)) | 仅 dp 数组(O(n)) |
| 适用场景 | 子问题依赖后续元素(如从当前位置向后找) | 子问题依赖前置元素(如从当前位置向前找) |
本质联系:两种方法都通过“存储子问题结果”避免重复计算,时间复杂度相同(O(n²)),只是遍历子问题的方向不同。记忆化搜索更直观(符合递归思维),动态规划更高效(无递归栈开销)。
六、实现过程中的坑点总结
-
子序列与子数组的混淆
容易错误地认为“子序列必须连续”,导致在遍历子问题时限制了j的范围(如只看相邻元素)。
解决:明确子序列的定义(元素顺序不变但可不连续),遍历所有符合条件的前置/后置元素。 -
备忘录初始化错误
若将备忘录初始化为0,但实际子序列长度可能为1(如单个元素),可能导致逻辑错误(如误认为“未计算”)。
解决:确保初始化值与“有效结果”不冲突(如用-1表示未计算,避免与1混淆)。 -
动态规划的边界处理
忘记初始化dp[i] = 1,直接进入循环计算,导致当没有符合条件的j时,dp[i]保持0,结果错误。
解决:必须先初始化dp[i] = 1(自身构成子序列),再进行后续更新。 -
贪心+二分的理解偏差
误认为tails数组是“实际的最长递增子序列”,导致对替换逻辑的困惑(如为什么可以替换中间元素)。
解决:明确tails的作用是“维护最小尾部以最大化后续可能性”,其值本身不代表最终子序列,仅长度有效。
七、举一反三
掌握LIS的核心思路后,可解决以下变种问题:
-
LeetCode 354. 俄罗斯套娃信封问题
问题:信封有宽和高,只有宽和高都大于另一个信封时才能嵌套,求最大嵌套层数。
思路:将信封按宽排序(宽相等时高降序),转化为“高的最长递增子序列”问题(避免宽相等时嵌套)。 -
LeetCode 673. 最长递增子序列的个数
问题:求最长递增子序列的数量。
思路:在动态规划中增加一个count数组,count[i]记录以i结尾的最长子序列的个数,根据dp数组的更新同步更新count。 -
最长递增子序列的具体方案
问题:不仅求长度,还要输出一个最长递增子序列。
思路:在贪心+二分的基础上,通过记录每个元素的前驱索引,回溯构建具体子序列。
八、总结
“最长递增子序列”是一道贯穿“暴力递归→记忆化搜索→动态规划→贪心+二分”的经典题,每种解法都对应着不同的算法设计思路:
- 记忆化搜索展现了“自顶向下”的递归优化思想,通过备忘录消除重复计算;
- 动态规划体现了“自底向上”的递推逻辑,用迭代方式系统解决子问题;
- 贪心+二分则突破了动态规划的思维定式,通过重构问题实现效率飞跃。
理解这道题的关键不仅在于记住解法,更在于掌握“状态定义的艺术”——如何将复杂的序列问题拆解为可复用的子问题,以及在不同场景下选择最优的解法(如小规模用DP,大规模用贪心+二分)。
下一篇,我们将讲解力扣 375.猜数字大小 二,一起深入理解记忆化搜素。感兴趣的朋友可以提前关注,让我们一起在算法的世界里进阶~
最后,欢迎在评论区分享你的解题思路或优化技巧,无论是对代码的改进还是对思路的补充,都能帮助更多人理解这道题的本质~ 🌟

如果觉得这篇讲解对你有帮助,别忘了点赞+关注哦~ 后续会持续更新更多经典算法题的深度解析,带你从“会做”到“看透本质”! 😉

)






 完结篇!!!)
)
RT-THREAD版)







)

