前言
IO是指 Input/Output,即输入和输出。以内存为中心:
- Input指从外部读入数据到内存,例如把文件从磁盘读取到内存,从网络读取数据到内存等等。
- Output指把数据从内存输出到外部,例如把数据从内存写入到文件,把数据从内存输出到网络等等。
为什么要把数据读到内存才能处理这些数据?因为代码是在内存中运行的,数据也必须读到内存,最终的表示方式无非是 byte[ ]数组,字符串等,都必须存放在内存里。
从 Java 代码来看,输入实际上就是从外部,例如,硬盘上的某个文件,把内容读到内存,并且以 Java 提供的某种数据类型表示,例如,byte[],String,这样,后续代码才能处理这些数据。
因为内存有“易失性”的特点,所以必须把处理后的数据以某种方式输出,例如,写入到文件。Output 实际上就是把 Java 表示的数据格式,例如,byte[],String等输出到某个地方。
IO 流是一种顺序读写数据的模式,它的特点是单向流动。数据类似自来水一样在水管中流动,所以我们把它称为 IO 流。
在Java中,InputStream代表输入字节流,OuputStream代表输出字节流,这是最基本的两种IO流。
FIle对象的一些操作
创建文件常用的三种方式
主要是根据它的 public 构造方法,File的public构造方法共有4种
还有一种public File(URI uri)用的比较少就没说
根据路径创建一个File对象
方法:new File(String Pathname)
package IOStream;import java.io.File;
import java.io.IOException;public class newFile01 {public static void main(String[] args) {//文件路径:xpw/src/IOStream/newFile01.javaFile file = new File("src/IOStream/1.txt");//pathname:"/1.txt" --> 盘符根目录//pathname:"1.txt" --> 项目根目录try {file.createNewFile();} catch (IOException e) {throw new RuntimeException(e);}}
}
根据父目录路径,在子路径下生成文件
方法:new File(String parent, String child)
package IOStream;import java.io.File;
import java.io.IOException;public class newFile03 {public static void main(String[] args) {File file = new File("src/IOStream","3.txt");try {file.createNewFile();} catch (IOException e) {throw new RuntimeException(e);}}
}
根据父目录 File 对象,在子路径创建一个文件
方法:new File(File parent, String child)
package IOStream;import java.io.File;
import java.io.IOException;public class newFile02 {public static void main(String[] args) {File parent = new File("src/IOStream");File file = new File(parent,"2.txt");try {file.createNewFile();} catch (IOException e) {throw new RuntimeException(e);}}
}
获取文件信息
通过file对象的一些方法进行获取
package IOStream;import java.io.File;public class gerFileInfo {public static void main(String[] args) {File file = new File("src/IOStream/3.txt");System.out.println("文件名称为:" + file.getName());System.out.println("文件的绝对路径为:" + file.getAbsolutePath());System.out.println("文件的父级目录为:" + file.getParent());System.out.println("文件的大小(字节)为:" + file.length());System.out.println("这是不是一个文件:" + file.isFile());System.out.println("这是不是一个目录:" + file.isDirectory());}
}
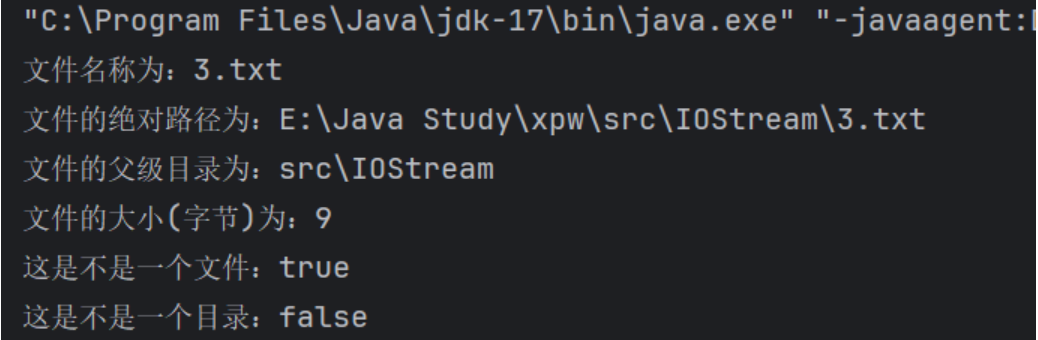
目录与文件操作
文件删除
使用 file.delete(文件)
package IOStream;import java.io.File;public class delFIle {public static void main(String[] args) {File file = new File("src/IOStream/3.txt");boolean delete = file.delete();System.out.println(delete?"Deleted Successfully":"Failed to Delete Successfully");}
}
目录删除
使用 file.delete(目录),前提是目录为空
package IOStream;import java.io.File;public class delDictory {public static void main(String[] args) {File file = new File("src/IOStream/test");boolean delete = file.delete();System.out.println(delete?"success":"fail");}
}
创建单级目录
使用file.mkdir()
package IOStream;import java.io.File;public class createDictory {public static void main(String[] args) {File file = new File("src/IOStream/dictory");boolean mkdir = file.mkdir();System.out.println(mkdir?"success":"fail");}
}
创建多级目录
使用 file.mkdirs()
package IOStream;import java.io.File;public class createDictorys {public static void main(String[] args) {File file = new File("src/IOStream/Dictorys/test/123");boolean mkdirs = file.mkdirs();System.out.println(mkdirs?"success":"fail");}
}
IO流分类
按照操作数据单位不同分为:字节流和字符流
- 字节流(8bit,适用于二进制文件)
- 字符流(按字符,因编码不同而异,适用于文本文件)
数据流流向:输入流(读取数据)和输出流(写入数据)。
流的角色:节点流(直接操作数据源)和处理流/包装流(对节点流进行包装,提供额外功能)。
| 类型 | 特点 | 抽象基类 |
|---|---|---|
| 字节流 | 处理二进制数据,单位 8bit | InputStream OutputStream |
| 字符流 | 处理文本数据,单位依赖字符编码 | Reader Writer |
| 节点流 | 直接操作数据源 | 如 FileInputStream |
| 处理流/包装流 | 封装节点流,提供增强功能 | 如 BufferedInputStream |
InputStream
InputStream就是Java标准库提供的最基本的输入流。它位于java.io这个包里, java.io包提供了所有同步IO的功能
注意:InputStream不是一个接口,而是一个抽象类,是所有输入流的超类
它里面最重要的方法就是int read()
public abstract int read() throws IOException;
这个方法会读取输入流的下一个字节,并返回该字节表示的int值(0~255)。如果已读到末尾,返回-1表示不能继续读取了。
FileInputStream() 实现类
FileInputStream是InputStream的一个子类。顾名思义,FileInputStream就是从文件流中读取数据。
通过FileInputStream()来读取一个文件
package IOStream;import java.io.FileInputStream;
import java.io.IOException;public class inputStream {public static void main(String[] args) {FileInputStream fileinputstream = null;int read=0;try {fileinputstream = new FileInputStream("src/IOStream/1.txt");while((read=fileinputstream.read())!=-1){System.out.print((char)read);//不换行
// System.out.println((char)read);//换行}} catch (IOException e) {e.printStackTrace();}finally {try {fileinputstream.close();} catch (IOException e) {e.printStackTrace();}}}}
应用程序在运行的过程中,如果打开了一个文件进行读写,完成后要及时地关闭,以便让操作系统把资源释放掉,否则,应用程序占用的资源会越来越多,不但白白占用内存,还会影响其他应用程序的运行。InputStream和OutputStream都是通过close()方法来关闭流。关闭流就会释放对应的底层资源。
InputStream和OutputStream都实现了AutoCloseable的接口,会自动加上finally语句并调用close()方法
所以可以通过这种方式去写:try(resource){}
try(fileinputstream = new FileInputStream("src/IOStream/1.txt")){ }
缓冲
在读取流的时候,一次读取一个字节比较低效,利用缓冲一次读取多个字节到缓冲区会比较高效
InputStream提供了两个重载方法来支持读取多个字节
int read(byte[] b):读取若干字节并填充到byte[]数组,返回读取的字节数int read(byte[] b, int off, int len):指定byte[]数组的偏移量和最大填充数
需要先定义一个byte[]数组作为缓冲区,read()方法会尽可能多地读取字节到缓冲区, 但不会超过缓冲区的大小。read()方法的返回值不再是字节的int值,而是返回实际读取了多少个字节。如果返回-1,表示没有更多的数据了。
package IOStream;import java.io.FileInputStream;
import java.io.IOException;public class inputStream02 {public static void main(String[] args) {FileInputStream inputStream = null;//设置缓冲区,大小为 8 字节byte[] cache = new byte[8];int datalen = 0;try (FileInputStream fileInputStream = new FileInputStream("src/IOStream/1.txt")) {while((datalen = fileInputStream.read(cache))!=-1){System.out.println("read "+datalen+" bytes");// 会将整个cache数组转化为字符串,会存在上一次循环留下来的数据System.out.println(new String(cache));// 只将实际读取到的 datalen 长度的字节从 cache 数组中转换为字符串System.out.println(new String(cache,0,datalen));}} catch (IOException e) {throw new RuntimeException(e);}}
}
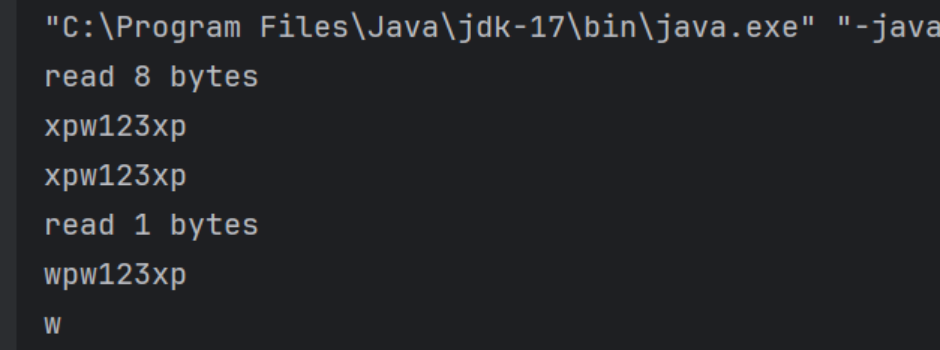
ByteArrayInputStream实现类
ByteArrayInputStream() 允许你将一个字节数组(**byte[]**)当作一个输入流来读取
相当于把内存中的字节数组当成了一个文件或其他数据源,可以使用InputStream 的各种方法来处理它
许多库和方法都接受 InputStream 作为参数,如果你有字节数组,通过 ByteArrayInputStream() 就可以方便地与这些API集成。
ByteArrayInputStream()通常有两种构造方法:
**ByteArrayInputStream(byte[] b)**
-
- 接收一个完整的字节数组作为数据源。
- 流的读取将从数组的第一个字节开始,到数组的最后一个字节结束。
**ByteArrayInputStream(byte[] b, int offset, int length)**
-
- 接收一个字节数组 。
offset:指定从数组的哪个索引位置开始读取。length:指定从offset位置开始,总共读取多少个字节。- 这允许你只读取字节数组的一部分。
package IOStream;import java.io.ByteArrayInputStream;
import java.io.IOException;public class inputStream03 {public static void main(String[] args) {byte[] data = "xpw123xpw".getBytes();//读取整个byte数组int datalen = 0;try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)) {System.out.println("读取所有数据:");while((datalen = byteArrayInputStream.read()) != -1){System.out.print((char)datalen);}} catch (IOException e) {throw new RuntimeException(e);}//读取byte数组的一部分try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data,3,3)) {System.out.println("\n读取部分数据:");while((datalen = byteArrayInputStream.read()) != -1){System.out.print((char)datalen);}} catch (IOException e) {throw new RuntimeException(e);}//结合缓冲区读取byte[] cache = new byte[8];try(ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)){System.out.println("\n通过缓冲区读取: ");while((datalen = byteArrayInputStream.read(cache)) != -1){System.out.println(new String(cache,0,datalen));}} catch (IOException e) {throw new RuntimeException(e);}}
}
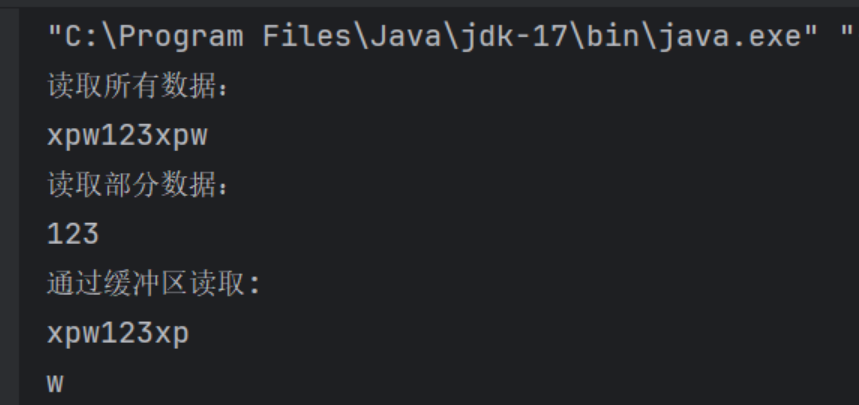
OutputStream
OutputStream是Java标准库提供的最基本的输出流
和InputStream类似,OutputStream也是抽象类,它是所有输出流的超类。这个抽象类定义的一个重要的方法就是void write(int b)
public abstract void write(int b) throws IOException;
当然这个实现也比较简单,就是一个字节一个字节的写进去
OutputStream还提供了一个重要的方法就是flush(),它的目的是将缓冲区的内容真正输出到目的地
为什么要有flush()?
因为向磁盘、网络写入数据的时候,出于效率的考虑,操作系统并不是输出一个字节就立刻写入到文件或者发送到网络,而是把输出的字节先放到内存的一个缓冲区里(本质上就是一个byte[]数组),等到缓冲区写满了,再一次性写入文件或者网络。对于很多IO设备来说,一次写一个字节和一次写1000个字节,花费的时间几乎是完全一样的,所以OutputStream有个flush()方法,能强制把缓冲区内容输出。
不过大多时候我们不需要调用这个flush()方法,因为如果缓冲区写满了,OutputStream会自动调用它,并且在调用close()方法关闭OutputStream之前,也会自动调用flush()
FileOutputStream实现类
FileOutputStream从文件获取输出流,是OutputStream常用的一个实现类
write(int b)
一个字节一个字节的写入
package IOStream;import java.io.FileOutputStream;
import java.io.IOException;public class writeStream {public static void main(String[] args) {try (FileOutputStream outputStream = new FileOutputStream("src/IOStream/1.txt")) {outputStream.write(72);outputStream.write(73);outputStream.write(74);outputStream.write(75);} catch (IOException e) {throw new RuntimeException(e);}}
}
write(byte b[])
整个字节数组写入
package IOStream;import java.io.FileOutputStream;
import java.io.IOException;public class writeStream02 {public static void main(String[] args) {byte[] data= "112233".getBytes();try (FileOutputStream outputStream = new FileOutputStream("src/IOStream/2.txt")) {outputStream.write(data);} catch (IOException e) {throw new RuntimeException(e);}}
}
追加写入
public FileOutputStream(String name, boolean append) throws FileNotFoundException
public FileOutputStream(File file, boolean append) throws FileNotFoundException
主要在于构造函数多添加一个参数
package IOStream;import java.io.FileOutputStream;
import java.io.IOException;public class writeStream03 {public static void main(String[] args) {byte[] data= "xpw".getBytes();try (FileOutputStream outputStream = new FileOutputStream("src/IOStream/2.txt", true)) {outputStream.write(data);} catch (IOException e) {throw new RuntimeException(e);}}
}
同样,OutputStream也有一个子类ByteArrayOutputStream,在内存中模拟一个OutputStream流, 实际上是把一个byte[]数组在内存中变成一个OutputStream
byte[] data;
try (ByteArrayOutputStream output = new ByteArrayOutputStream()) {output.write("Hello ".getBytes("UTF-8"));output.write("world!".getBytes("UTF-8"));data = output.toByteArray();
}
System.out.println(new String(data, "UTF-8"));
Reader
Reader是Java的IO库提供的另一个输入流接口。和InputStream的区别是,InputStream是一个字节流,即以byte为单位读取,而Reader是一个字符流,即以char为单位读取, 是所有字符输入流的超类
| InputStream | Reader |
|---|---|
字节流,以byte为单位 | 字符流,以char为单位 |
读取字节(-1,0~255):int read() | 读取字符(-1,0~65535)int read() |
读到字节数组:int read(byte[] b) | 读到字符数组:int read(char[] c) |
FileReader
FileReader是Reader的一个子类
read()
这个方法读取字符流的下一个字符,并返回字符表示的**int**,范围是0~65535。如果已读到末尾,返回-1
package IOStream;import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;public class fileReader {public static void main(String[] args) {try {Reader reader = new FileReader("src/IOStream/1.txt");for (;;){int n = reader.read();if(n==-1)break;System.out.print((char)n);}} catch (IOException e) {throw new RuntimeException(e);}}
}
有时候可能会出现一些乱码问题,要避免乱码问题,我们需要在创建FileReader时指定编码:
Reader reader = new FileReader("src/IOStream/1.txt", StandardCharsets.UTF_8);
read(char[] c)
一次性读取若干字符并填充到char[]数组
它返回实际读入的字符个数,最大不超过char[]数组的长度。返回-1表示流结束
需要先设置一个缓冲区
package IOStream;import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
import java.nio.charset.StandardCharsets;public class fileReader02 {public static void main(String[] args) {try (Reader reader = new FileReader("src/IOStream/2.txt", StandardCharsets.UTF_8)) {char[] cache = new char[8];int n;while ((n = reader.read(cache)) != -1) {System.out.println("read " + n + " chars.");System.out.println(new String(cache, 0, n));}} catch (IOException e) {throw new RuntimeException(e);}}
}
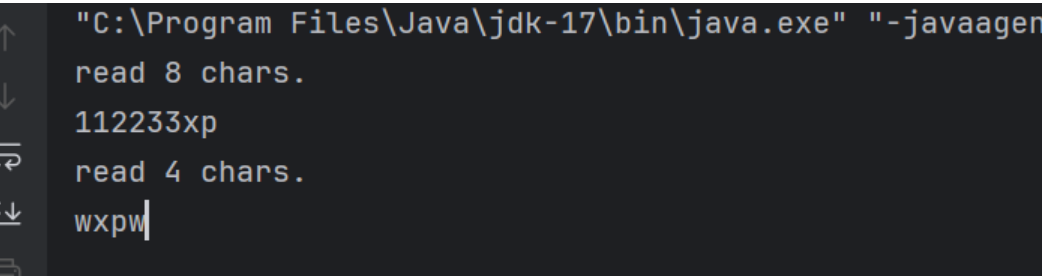
CharArrayReader
CharArrayReader可以在内存中模拟一个Reader,它的作用实际上是把一个char[]数组变成一个Reader,这和ByteArrayInputStream非常类似:
try (Reader reader = new CharArrayReader("Hello".toCharArray())) { }
StringReader
StringReader可以直接把String作为数据源,它和CharArrayReader几乎一样
try (Reader reader = new StringReader("Hello")) { }
Writer
Reader是带编码转换器的InputStream,它把byte转换为char,而Writer就是带编码转换器的OutputStream,它把char转换为byte并输出。
Writer和OutputStream的区别如下:
| OutputStream | Writer |
|---|---|
字节流,以byte为单位 | 字符流,以char为单位 |
写入字节(0~255):void write(int b) | 写入字符(0~65535):void write(int c) |
写入字节数组:void write(byte[] b) | 写入字符数组:void write(char[] c) |
| 无对应方法 | 写入字符串:void write(String s) |
FileWriter
FileWriter就是向文件中写入字符流的Writer。它的使用方法和FileReader类似
package IOStream;import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.nio.charset.StandardCharsets;public class fileWriter {public static void main(String[] args) {try (Writer writer = new FileWriter("src/IOStream/2.txt", StandardCharsets.UTF_8)) {//写入单个字符writer.write("h");writer.write(65);//写入字符数组writer.write("hello".toCharArray());//写入字符串writer.write("hello");} catch (IOException e) {throw new RuntimeException(e);}}
}
CharArrayWriter
CharArrayWriter可以在内存中创建一个Writer,它的作用实际上是构造一个缓冲区,可以写入char,最后得到写入的char[]数组,这和ByteArrayOutputStream非常类似
try (CharArrayWriter writer = new CharArrayWriter()) {writer.write(65);writer.write(66);writer.write(67);char[] data = writer.toCharArray(); // { 'A', 'B', 'C' }
}
StringWriter
StringWriter也是一个基于内存的Writer,它和CharArrayWriter类似。实际上,StringWriter在内部维护了一个StringBuffer,并对外提供了Writer接口。
参考文章
https://drun1baby.top/2022/05/30/Java-IO%E6%B5%81
https://liaoxuefeng.com/books/java/io/index.html





中的应用探索)





)







