之前做个几个大模型的应用,都是使用Python语言,后来有一个项目使用了Java,并使用了Spring AI框架。随着Spring AI不断地完善,最近它发布了1.0正式版,意味着它已经能很好的作为企业级生产环境的使用。对于Java开发者来说真是一个福音,其功能已经能满足基于大模型开发企业级应用。借着这次机会,给大家分享一下Spring AI框架。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Spring AI-1.0.0,JDK版本使用的是19。
代码参考: https://github.com/forever1986/springai-study
目录
- 1 RAG中的问题优化
- 2 Modules
- 2.1 Pre-Retrieval
- 2.1.1 QueryTransformer
- 2.1.2 QueryExpander
- 2.2 Retrieval
- 2.2.1 DocumentRetriever
- 2.2.2 DocumentJoiner
- 2.3 Post-Retrieval
- 2.3.1 DocumentPostProcessor
- 2.4 Generation
- 2.4.1 QueryAugmenter
上一章讲了通过QuestionAnswerAdvisor实现RAG,但是对于真正的RAG来说还远远不够。因此Spring AI提供了RetrievalAugmentationAdvisor,其在QuestionAnswerAdvisor增强了RAG的其它功能,这一章就来看看QuestionAnswerAdvisor的实现方式和底层原理。
1 RAG中的问题优化
建议不熟悉RAG的朋友,可以有先看看我之前写的关于《RAG系列》中的这篇文章《检索增强生成RAG系列4–RAG优化之问题优化》
在RAG提出来之后,对于初始的问题可能对查询结果不是很好,比如问题表达模糊、语义与文档不一致等等,因此问题优化就是提高RAG准确率的关键节点。而这里面提出了很多实践理论,包括Multi-Query、RAG-Fusion、HyDE、Decomposition和Step-back prompting等等。随着不同场景下,对初始问题的优化方法也会越来越多,但是实际上对于问题优化,在一篇论文《Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks》给总结成以下几个模块:

说明:以上的步骤分别是:
1)Pre-Retrieval :负责对用户查询进行处理,以获得最理想的检索结果
2)Retrieval :负责查询诸如向量存储这样的数据系统,并获取最相关的文档
3)Post-Retrieval :负责对检索到的文档进行处理,以获得最佳的生成结果
4)Generation :负责根据用户查询以及检索到的文档生成最终的响应
而由以上的四个步骤,就可以随意组合成Multi-Query、RAG-Fusion、HyDE、Decomposition和Step-back prompting等等
而RetrievalAugmentationAdvisor就是Spring AI对这个流程的具体实现。下面看看RetrievalAugmentationAdvisor的源码,下面摘取源码的before函数进行讲解:
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, @Nullable AdvisorChain advisorChain) {Map<String, Object> context = new HashMap<>(chatClientRequest.context());// 0. 根据用户输入的文本、参数以及对话历史生成查询语句,也就是初始问题。Query originalQuery = Query.builder().text(chatClientRequest.prompt().getUserMessage().getText()).history(chatClientRequest.prompt().getInstructions()).context(context).build();// 1. 根据一系列transformedQuery 对原始用户查询进行转换Query transformedQuery = originalQuery;for (var queryTransformer : this.queryTransformers) {transformedQuery = queryTransformer.apply(transformedQuery);}// 2. 将查询扩展为一个或多个查询。List<Query> expandedQueries = this.queryExpander != null ? this.queryExpander.expand(transformedQuery): List.of(transformedQuery);// 3. 为每个查询获取相关documents。Map<Query, List<List<Document>>> documentsForQuery = expandedQueries.stream().map(query -> CompletableFuture.supplyAsync(() -> getDocumentsForQuery(query), this.taskExecutor)).toList().stream().map(CompletableFuture::join).collect(Collectors.toMap(Map.Entry::getKey, entry -> List.of(entry.getValue())));// 4. 根据多个查询条件并从多个数据源中检索到的documents进行合并// sources.List<Document> documents = this.documentJoiner.join(documentsForQuery);// 5. 对documents进行后期处理。.for (var documentPostProcessor : this.documentPostProcessors) {documents = documentPostProcessor.process(originalQuery, documents);}context.put(DOCUMENT_CONTEXT, documents);// 6. 将document 的上下文信息添加到用户查询中Query augmentedQuery = this.queryAugmenter.augment(originalQuery, documents);// 7. 更新 ChatClientRequest 并添加增强promptreturn chatClientRequest.mutate().prompt(chatClientRequest.prompt().augmentUserMessage(augmentedQuery.text())).context(context).build();
}
说明:其步骤包括以下内容:
1)QueryTransformer:通过QueryTransformer对查询进行转换,解决问题不清晰,问题语义与文档不一致问题
2)QueryExpander:通过QueryExpander转为为多个查询,解决问题不清晰,问题语义与文档不一致问题
3)DocumentRetriever:查询文档,实现与QuestionAnswerAdvisor一样的功能
4)DocumentJoiner:将多个查询结果文档合并到一起
5)DocumentPostProcessor:对查询结果文档进行后续处理,比如排序
6)QueryAugmenter:提供额外数据的组件,有助于为大型语言模型提供必要的背景信息,从而回答用户的问题。
7)组织最后的提示词prompt
从上面可以看到,Spring AI通过不同的插件,实现了最终优化问题查询文档的效果。接下来,通过一个个示例来看看如何使用RetrievalAugmentationAdvisor的各个模块:
2 Modules
代码参考lesson11子模块下面的advanced-advisor子模块
前期准备:
1)新建advanced-advisor子模块,其pom引入如下:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-zhipuai</artifactId></dependency><!-- 引入rag插件 这样可以使用Spring AI的RAG功能--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-rag</artifactId></dependency>
</dependencies>
2)新建BuildModelUtils类,获取模型Builder给下面示例共用
import com.demo.lesson11.advanced.utils.BuildModelUtils
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.zhipuai.ZhiPuAiChatModel;
import org.springframework.ai.zhipuai.ZhiPuAiChatOptions;
import org.springframework.ai.zhipuai.api.ZhiPuAiApi;public class BuildModelUtils {public static ChatClient.Builder getBuilder(){var zhiPuAiApi = new ZhiPuAiApi("你的智谱API KEY");var chatModel = new ZhiPuAiChatModel(zhiPuAiApi, ZhiPuAiChatOptions.builder().model("GLM-4-Flash-250414").temperature(0.4).build());return ChatClient.builder(chatModel);}
}
3)创建application.properties配置文件
# 聊天模型
spring.ai.zhipuai.api-key=720a5f832f4b4754ba4003cde0f92598.4BJ5wgObIG0CFdB5
spring.ai.zhipuai.chat.options.model=GLM-4-Flash-250414
spring.ai.zhipuai.chat.options.temperature=0.7
2.1 Pre-Retrieval
Pre-Retrieval负责对用户查询进行处理,以获得最理想的检索结果。在Spring AI中分别有 QueryTransformer 和 QueryExpander 两个组件来实现。
2.1.1 QueryTransformer
QueryTransformer:是一个用于将输入查询进行转换的组件,旨在使其更有利于检索任务的完成,能够解决诸如查询格式不规范、术语含糊、词汇复杂或语言不支持等问题。该组件可以实现《HyDE》的思想。其实现类如下:
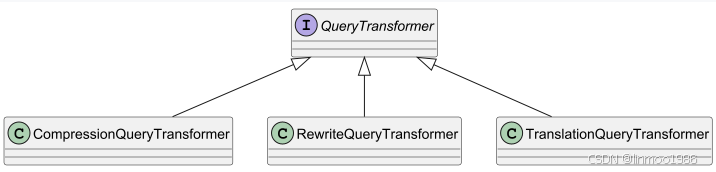
下面分别对其三个实现类进行讲解
CompressionQueryTransformer :利用大型语言模型将对话历史记录和后续查询内容压缩成一个独立的查询,该查询能够准确反映对话的核心要点。也就是为了将历史记录和问题一起总结。
示例说明:利用CompressionQueryTransformer将上下文总结为最终的问题
import com.demo.lesson11.advanced.utils.BuildModelUtils
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.transformation.CompressionQueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;public class CompressionQueryTransformerTest {public static void main(String[] args) {// 这是原始查询Query query = Query.builder().text("第二大城市是哪个?").history(new UserMessage("中国的首都是哪个城市?"),new AssistantMessage("北京是中国的首都")).build();// 提示模版PromptTemplate promptTemplate = new PromptTemplate("""根据以下对话历史和后续的查询,您的任务是综合提炼出一个简洁、独立的查询语句,该语句应包含历史对话中的相关信息。确保独立的查询语句清晰、具体,并能准确反映用户意图。对话历史:{history}后续询问:{query}独立查询:""");// 使用CompressionQueryTransformer转换QueryTransformer queryTransformer = CompressionQueryTransformer.builder().chatClientBuilder(BuildModelUtils.getBuilder()) // 需要引入大模型.promptTemplate(promptTemplate) // 自定义模版.build();System.out.println(queryTransformer.apply(query).text());}}

RewriteQueryTransformer :利用一个大型语言模型来对用户查询进行修改,以便在查询目标系统(如向量存储或网络搜索引擎)时能获得更优的结果。这个就是为了解决原始问题比较模糊、无关的叙述的情况。
示例说明:利用RewriteQueryTransformer对原先问题进行提炼
import com.demo.lesson11.advanced.utils.BuildModelUtils
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;public class RewriteQueryTransformerTest {public static void main(String[] args) {Query query = new Query("我正在学习机器学习相关课程,LLM是什么?");QueryTransformer queryTransformer = RewriteQueryTransformer.builder().chatClientBuilder(BuildModelUtils.getBuilder()) // 需要引入大模型.build();Query transformedQuery = queryTransformer.transform(query);System.out.println(transformedQuery.text());}}
TranslationQueryTransformer:利用一个大型语言模型将查询翻译成所使用的嵌入模型生成文档嵌入所支持的目标语言。如果查询已经是目标语言,则直接返回原样。如果查询的语言未知,则也直接返回原样。其实就是翻译功能。
示例说明:利用TranslationQueryTransformer将一句话英文将其翻译为中文
import com.demo.lesson11.advanced.utils.BuildModelUtils
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.TranslationQueryTransformer;public class TranslationQueryTransformerTest {public static void main(String[] args) {Query query = new Query("Which city is the capital of the United States?");QueryTransformer queryTransformer = TranslationQueryTransformer.builder().chatClientBuilder(BuildModelUtils.getBuilder()).targetLanguage("Chinese").build();Query transformedQuery = queryTransformer.transform(query);System.out.println(transformedQuery.text());}
}

2.1.2 QueryExpander
QueryExpander :一种能够将输入查询扩展为一系列查询的组件,它能够解决诸如查询格式不规范等问题,通过提供不同的查询形式或将复杂问题分解为更简单的子查询来实现这一功能。目前QueryExpander只有一种实现类MultiQueryExpander。
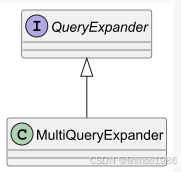
MultiQueryExpander :利用大型语言模型将查询转化为多个语义各异的变体,以涵盖不同的视角,这对于获取更多背景信息以及提高找到相关结果的可能性非常有用。该类可以实现《Multi-Query》的思想。
示例说明:利用MultiQueryExpander生成4个新的问题,其中包括原始问题
import com.demo.lesson11.advanced.utils.BuildModelUtils
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.expansion.MultiQueryExpander;import java.util.List;public class MultiQueryExpanderTest {public static void main(String[] args) {MultiQueryExpander queryExpander = MultiQueryExpander.builder().chatClientBuilder(BuildModelUtils.getBuilder()) // 需要引入大模型.numberOfQueries(4) // 生成新的问题条数.includeOriginal(true) // 是否包括原先问题,默认是true.build();List<Query> queries = queryExpander.expand(new Query("如何运行一个 Spring Boot 应用程序?"));for(Query query : queries){System.out.println(query.text());}}
}

2.2 Retrieval
Retrieval 是负责查询诸如向量存储这样的数据系统,并获取最相关的文档。
2.2.1 DocumentRetriever
DocumentRetriever:负责从底层数据源(如搜索引擎、向量存储、数据库或知识图谱)中检索文档的组件。这个插件与QuestionAnswerAdvisor实现功能基本一致。目前只有一个实现向量数据库查询的实现类:VectorStoreDocumentRetriever
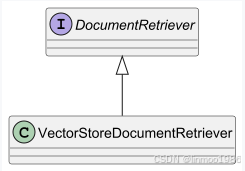
VectorStoreDocumentRetriever :能够从向量存储中检索出与输入查询在语义上相似的文档。它支持根据元数据、相似度阈值以及前 k 个结果来进行筛选。
示例说明:这里参考之前QuestionAnswerAdvisor的示例,查询top2的文档,增加元数据过滤条件
import org.springframework.ai.document.Document;
import org.springframework.ai.document.MetadataMode;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
import org.springframework.ai.zhipuai.ZhiPuAiEmbeddingModel;
import org.springframework.ai.zhipuai.api.ZhiPuAiApi;import java.util.ArrayList;
import java.util.List;public class VectorStoreDocumentRetrieverTest {public static void main(String[] args) {// 将文档放入向量数据库,这里需要使用EmbeddingModel模型。这里使用智谱的线上模型,需要付费的var zhiPuAiApi = new ZhiPuAiApi("你的智谱API KEY");var zhiPuAiEmbeddingModel = new ZhiPuAiEmbeddingModel(zhiPuAiApi, MetadataMode.EMBED);SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(zhiPuAiEmbeddingModel).build();simpleVectorStore.add(getDocuments());// 组装向量查询条件var b = new FilterExpressionBuilder().eq("source", "官方网站").build();DocumentRetriever retriever = VectorStoreDocumentRetriever.builder().vectorStore(simpleVectorStore).similarityThreshold(0.3).topK(2).filterExpression(b).build();// 查询List<Document> documents = retriever.retrieve(new Query("ChatGLM3是哪个国家的大模型?"));// 打印int i = 0;for (Document document: documents){System.out.println("-----" + (++i) + "-----");System.out.println(document.getText());}}private static List<Document> getDocuments(){Document document1 = new Document("""ChatGLM3 是北京智谱华章科技有限公司和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了更多的特性。\n北京智谱华章科技有限公司是一家来自中国的公司,致力于打造新一代认知智能大模型,专注于做大模型创新。""");document1.getMetadata().put("source", "官方网站");Document document2 = new Document("""OpenAI,是一家开放人工智能研究和部署公司,其使命是确保通用人工智能造福全人类。创立于2015年12月,总部位于美国旧金山。现由营利性公司OpenAI LP及非营利性母公司OpenAI Inc组成。""");document2.getMetadata().put("source", "官方网站");Document document3 = new Document("""ChatGLM3是由智谱清言开发的,是北京智谱华章科技有限公司推出的生成式AI助手,于2023年8月31日正式上线。 2024年8月29日,智谱清言APP支持视频通话功能。智谱清言基于智谱AI自主研发的中英双语对话模型还开发了ChatGLM、ChatGLM2、ChatGLM3、ChatGLM4等大模型。""");document3.getMetadata().put("source", "官方网站");Document document4 = new Document("""ChatGLM3 是由清华大学技术成果转化企业智谱AI研发的支持中英双语的对话机器人,基于千亿参数基座模型GLM架构开发。该模型通过多阶段训练流程形成通用对话能力,具备问答交互、代码生成、创意写作等功能,其开源版本ChatGLM-6B自2023年3月启动内测以来已形成广泛影响力。\n截至2024年3月,智谱AI通过该技术实现了2000多家生态合作伙伴的应用落地,并在多模态技术上持续突破,推出了视频生成等创新功能。清华大学是中国排名top2的学校。""");document4.getMetadata().put("source", "百度百科");List<Document> list = new ArrayList<>();list.add(document1);list.add(document2);list.add(document3);list.add(document4);return list;}
}

2.2.2 DocumentJoiner
DocumentJoiner:用于将根据多个查询从多个数据源检索到的文档组合成一个单一文档集合的组件。在组合过程中,它还能处理重复文档以及互惠排序策略。简单来说,就是对检索后的内容进行再一次处理。目前有一个实现类ConcatenationDocumentJoiner 。
ConcatenationDocumentJoiner:用于将根据多个查询从多个数据源检索到的文档组合成一个单一文档集合的组件。在组合过程中,它还能处理重复文档以及互惠排序策略。该组件实现了《Multi-Query》和《RAG-Fusion》这种多问题查询后的文档合并为一个集合。
示例说明:利用ConcatenationDocumentJoiner模拟将多查询结果合并去重
import org.springframework.ai.document.Document;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.retrieval.join.ConcatenationDocumentJoiner;
import org.springframework.ai.rag.retrieval.join.DocumentJoiner;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class ConcatenationDocumentJoinerTest {public static void main(String[] args) {// 模拟多查询后的结果Map<Query, List<List<Document>>> documentsForQuery = getDocumentsMap();// 使用ConcatenationDocumentJoiner合并DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();List<Document> documents = documentJoiner.join(documentsForQuery);// 打印int i = 0;for (Document document: documents){System.out.println("-----" + (++i) + "-----");System.out.println(document.getText());}}private static Map<Query, List<List<Document>>> getDocumentsMap(){Document document1 = new Document("""ChatGLM3 是北京智谱华章科技有限公司和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了更多的特性。\n北京智谱华章科技有限公司是一家来自中国的公司,致力于打造新一代认知智能大模型,专注于做大模型创新。""");document1.getMetadata().put("source", "官方网站");Document document2 = new Document("""OpenAI,是一家开放人工智能研究和部署公司,其使命是确保通用人工智能造福全人类。创立于2015年12月,总部位于美国旧金山。现由营利性公司OpenAI LP及非营利性母公司OpenAI Inc组成。""");document2.getMetadata().put("source", "官方网站");Document document3 = new Document("""ChatGLM3是由智谱清言开发的,是北京智谱华章科技有限公司推出的生成式AI助手,于2023年8月31日正式上线。 2024年8月29日,智谱清言APP支持视频通话功能。智谱清言基于智谱AI自主研发的中英双语对话模型还开发了ChatGLM、ChatGLM2、ChatGLM3、ChatGLM4等大模型。""");document3.getMetadata().put("source", "官方网站");Document document4 = new Document("""ChatGLM3 是由清华大学技术成果转化企业智谱AI研发的支持中英双语的对话机器人,基于千亿参数基座模型GLM架构开发。该模型通过多阶段训练流程形成通用对话能力,具备问答交互、代码生成、创意写作等功能,其开源版本ChatGLM-6B自2023年3月启动内测以来已形成广泛影响力。\n截至2024年3月,智谱AI通过该技术实现了2000多家生态合作伙伴的应用落地,并在多模态技术上持续突破,推出了视频生成等创新功能。清华大学是中国排名top2的学校。""");document4.getMetadata().put("source", "百度百科");Query query1 =Query.builder().text("ChatGLM3是哪个国家的大模型?").build();List<Document> list1 = new ArrayList<>();list1.add(document1);list1.add(document2);Query query2 =Query.builder().text("ChatGLM3 的研发国家是哪个?").build();List<Document> list2 = new ArrayList<>();list2.add(document1);list2.add(document3);Map<Query, List<List<Document>>> map = new HashMap<>();map.put(query1,List.of(list1));map.put(query2,List.of(list2));return map;}
}

2.3 Post-Retrieval
Post-Retrieval:负责对检索到的文档进行处理,以获得最佳的生成结果。简单来说就是可扩展的后置处理。
2.3.1 DocumentPostProcessor
DocumentPostProcessor :该组件能够根据查询对检索到的文档进行后处理,解决了诸如信息丢失在中间位置、模型带来的上下文长度限制以及减少检索信息中的噪声和冗余等问题。例如,它可以根据文档与查询的关联程度对其进行排序,剔除不相关或冗余的文档,或者对每个文档的内容进行压缩,以减少噪音和冗余信息。目前Spring AI并没有提供真正实现,需要用户自己实现。
比如可以使用该组件实现《RAG-Fusion》的RRF重排序。这里就不演示,在下一章中的RetrievalAugmentationAdvisor整体案例再演示。
2.4 Generation
Generation:负责根据用户查询以及检索到的文档生成最终的响应。也就是将前面所有步骤通过一个提示词利用大模型最终合并为问题。
2.4.1 QueryAugmenter
QueryAugmenter :用于为输入查询添加额外数据的组件,有助于为大型语言模型提供必要的背景信息,从而回答用户的问题。目前实现类只有一个ContextualQueryAugmenter。
ContextualQueryAugmenter :一种用于为输入查询添加额外数据的组件,有助于为大型语言模型提供必要的背景信息,从而能够回答用户的问题。
示例说明:利用ContextualQueryAugmenter的提示模版,将文档和问题生成最终问题
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;
import org.springframework.ai.rag.generation.augmentation.QueryAugmenter;import java.util.ArrayList;
import java.util.List;public class ContextualQueryAugmenterTest {public static void main(String[] args) {Document document1 = new Document("""ChatGLM3 是北京智谱华章科技有限公司和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了更多的特性。\n北京智谱华章科技有限公司是一家来自中国的公司,致力于打造新一代认知智能大模型,专注于做大模型创新。""");document1.getMetadata().put("source", "官方网站");Document document2 = new Document("""OpenAI,是一家开放人工智能研究和部署公司,其使命是确保通用人工智能造福全人类。创立于2015年12月,总部位于美国旧金山。现由营利性公司OpenAI LP及非营利性母公司OpenAI Inc组成。""");document2.getMetadata().put("source", "官方网站");List<Document> list = new ArrayList<>();list.add(document1);list.add(document2);PromptTemplate promptTemplate = new PromptTemplate("""以下为相关背景信息。---------------------{context}---------------------根据提供的背景信息且没有先入为主的观念,回答问题。请遵循以下规则:1. 如果答案不在所提供的信息中,那就直接说你不知道。2. 避免使用诸如“根据上下文……”或“所提供的信息……”这样的表述。查询:{query}回答:""");QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder().promptTemplate(promptTemplate).build();Query query =Query.builder().text("ChatGLM3是哪个国家的大模型?").build();System.out.println(queryAugmenter.augment(query, list).text());}
}

结语:本章针对Spring AI的RAG模块RetrievalAugmentationAdvisor进行详细的说明,同时对每个模块的功能进行了演示。下一章通过一个整合的完整案例,演示RetrievalAugmentationAdvisor的整体流程。
Spring AI系列上一章:《Spring AI 系列之十 - RAG-进阶QuestionAnswerAdvisor》
Spring AI系列下一章:《Spring AI 系列之十二 - RAG-进阶RetrievalAugmentationAdvisor案例》
![[TOOL] ubuntu 使用 ffmpeg 操作 gif、mp4](http://pic.xiahunao.cn/[TOOL] ubuntu 使用 ffmpeg 操作 gif、mp4)

)














 函数)

