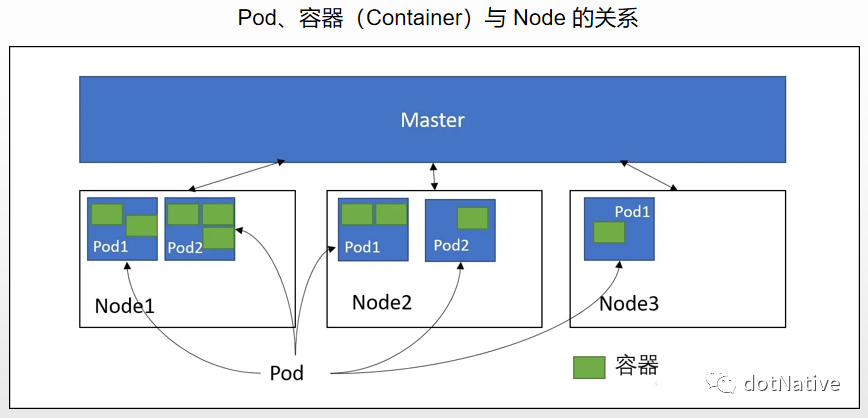
上一篇 《深入掌握 Pod》 文章我们介绍了 Pod 的知识点,接下来我们来继续学习 Pod 在 k8s 中的调度原理。在 k8s 平台上,通常情况下很少直接创建一个 Pod,大多情况下都是通过 Pod 的资源管理对象 来创建,例如:RC/RS、Deployment、DaemonSet、Job & CornJob 等控制器完成对一组 Pod 创建、调度及全生命周期的自动控制管理等任务。
k8s 调度器(kube-scheduler)
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是 集群控制面 的一部分。 如果你真的希望或者有这方面的需求,kube-scheduler 在设计上允许你自己编写一个调度组件并替换原有的 kube-scheduler。
对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的节点去运行这个 Pod。 然而,Pod 内的每一个容器对资源都有不同的需求, 而且 Pod 本身也有不同的需求。因此,Pod 在被调度到节点上之前, 根据这些特定的调度需求,需要对集群中的节点进行一次 过滤。
在一个集群中,满足一个 Pod 调度请求的所有节点称之为 可调度节点。 如果没有任何一个节点能满足 Pod 的资源请求, 那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有 可调度节点,然后根据一系列函数对这些可调度节点 打分, 选出其中得分最高的节点来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、 亲和以及反亲和要求、数据局部性、负载间的干扰等等。
了解【集群控制面】更多信息,请查看:https://kubernetes.io/zh-cn/docs/reference/glossary/?all=true#term-control-plane
kube-scheduler 调度流程
kube-scheduler 给一个 Pod 做调度选择时包含两个步骤:过滤 和 打分,如下流程所示:
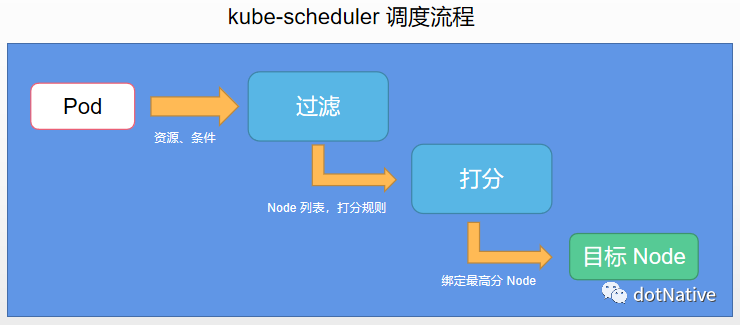
【过滤阶段】会将所有满足 Pod 调度需求的节点选出来。 例如,PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下, 这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
【打分阶段】调度器会为 Pod 从所有可调度节点中选取一个最合适的节点。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的节点上。 如果存在多个得分最高的节点,kube-scheduler 会从中随机选取一个。
支持以下两种方式配置 调度器的过滤和打分 行为:
【
调度策略】 允许你配置过滤所用的断言(Predicates)和打分所用的优先级(Priorities)。【
调度配置】允许你配置实现不同调度阶段的插件, 包括:QueueSort、Filter、Score、Bind、Reserve、Permit等等。 你也可以配置kube-scheduler运行不同的配置文件。
了解 kube-scheduler 更多信息,请查看:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/kube-scheduler/
Deployment & ReplicaSet,全自动调度
在早期的 k8s 版本中是没有这么多 Pod 副本控制器的,只有一个 Pod 副本控制器 RC(Replication Controller),RC 的设计实现:RC 独立于所控制的 Pod,并通过 Label 标签松耦合关联关系控制目标 Pod 实例的创建和销毁。在 k8s 的新版本中,RC 已经被 ReplicaSet(RS) 替换,RS 增强了 RC 的功能,RC 的标签选择器只能选择一个标签,而 RS 不但能选择标签,还拥有集合式的标签选择器,可以选择多个 Pod 标签,如下所示:
selector:matchLabels:tier: frontendmatchExpressions: - {key: tier, operator: In, values: [frontend]}RS 应用场景举例
例如 frontend 应用发布了 v1 和 v2 两个版本,此时你希望 frontend 的 Pod 副本数保持为 3 个,并且可以同时包含 v1 和 v2 版本的 Pod,这种情况就可以使用 RS 来实现控制,写法如下:
selector:matchLabels:version: v2matchExpressions: - {key: version, operator: In, values: [v1,v2]}从这个例子中可以看出,在 k8s 中的 滚动更新 就是巧妙利用 ReplicaSet(RS) 特性来实现的。
Deployment 默认调度
前面文章介绍了 Deployment 资源对象,这里我们简单的回顾下 Deployment 对象的调用链:
kubectl(client) => Deployment => ReplicaSet => Pod => Container
在大多数情况下,通常都不会直接创建 Pod,而是使用 Deployment 对象来创建 Pod ,而 Deployment 对象底层也是通过 ReplicaSet 来控制 Pod 副本数量的,这也是 官方推荐的方式,而不是直接使用底层的 ReplicaSet 来创建 Pod。
上面举例的 Deployment 对象的 yaml 定义完整文件 nginx-deployment.yaml 如下:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3 # Pod 实例副本数selector:matchLabels:version: v2matchExpressions: - {key: version, operator: In, values: [v1,v2]}template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80运行命令创建 Deployment 对象:
kubectl create -f nginx-deployment.yaml查看 Deployment 的状态:
kubectl get deployments查看创建的 ReplicaSet(RS)对象:
kubectl get rs查看创建的 Pod 对象的详细信息:
kubectl get pods -o wide
# 等效命令
kubectl get pods --output=widek8s 中 Master 上的 Schedule 服务(kube-scheduler 进程)负责实现 Pod 的调度。整个调度过程通过执行一系列复杂的算法,最终为每个 Pod 都计算出一个最佳的目标节点,这一过程是自动完成的。
接下来我们详细的介绍 Pod 的几种调度模式,每种模式都应用于特定的场景。
NodeSelector,节点定向调度
nodeSelector 是节点选择约束的最简单推荐形式。你可以将 nodeSelector 字段添加到 Pod 的规约中设置你希望的目标节点所具有的节点标签。 **k8s 只会将 Pod 调度到拥有指定的标签的节点上**。
举例,将 Pod 调度到拥有 Lable 标签的 disktype: ssd 节点上,该 Pod 的 yaml 文件定义如下:
apiVersion: v1
kind: Pod
metadata:name: nginxlabels:env: test
spec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresentnodeSelector:disktype: ssdPod 亲和性调度
亲和性调度功能包括 节点亲和性(NodeAffinity) 和 Pod 亲和性(PodAffinity) 两个维度的设置。
NodeSelector 通过 Label 标签的方式,简单的实现了限制 Pod 所在节点的方法。亲和性调度机制则极大的扩展了 Pod 的调度能力,主要增强功能有以下几点:
亲和性、反亲和性语言的表达能力更强。
nodeSelector只能选择拥有所有指定标签的节点。 亲和性、反亲和性为你提供对选择逻辑的更强控制能力。可以使用
“软限制”、优先采用等限制方式,代替之前的“硬限制”,这样调度器在无法满足优先需求的情况下,会退而求其次,继续运行该 Pod。可以根据节点上正在运行的其他 Pod 的标签来进行限制,而非节点本身的标签。这样就可以定义一种规则来描述 Pod 之间的亲和性和互斥关系。
NodeAffinity 与 NodeSelector 类似,增强了上面前两点优势。Pod 的 PodAffinity(亲和性) 和 PodAntiAffinity(互斥性)限制则是通过 Pod 标签来实现的,而不是 Node 节点标签,Pod 亲和性和互斥性调度都具备上述提到的优点。
亲和性功能由两种类型的亲和性组成:
NodeAffinit功能类似于NodeSelector字段,但它的表达能力更强,并且允许你指定软规则。Pod 间亲和性/反亲和性允许你根据其他 Pod 的标签来约束 Pod。
NodeAffinity,节点亲和性调度
节点亲和性概念上类似于 nodeSelector, 它使你可以 根据节点上的 Label 标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution:(硬性规则)调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。preferredDuringSchedulingIgnoredDuringExecution:(软性规则)调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。对软性规则可设置权重weight,其取值范围 1- 100 之间。
使用 Pod 规约中的 .spec.affinity.nodeAffinity 字段来设置 NodeAffinity(节点亲和性)。举例: with-node-affinity.yaml 文件定义如下:
apiVersion: v1
kind: Pod
metadata:name: with-node-affinity
spec:affinity:# 节点亲和性nodeAffinity:# 硬性规则,必须满足条件requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: topology.kubernetes.io/zone # 地区operator: Invalues:- antarctica-east1 # 南极洲东部1- antarctica-west1 # 南极洲西部1- key: topology.kubernetes.io/arch # 架构operator: In # 设置逻辑操作符values:- amd64- arm64# 软性规则,尝试满足,优先满足,不是必须条件preferredDuringSchedulingIgnoredDuringExecution:# 权重,优先级- weight: 1preference:matchExpressions:- key: disk-type # another-node-label-key,匹配另一个节点标签的 keyoperator: Invalues:- ssd # another-node-label-value,匹配另一个节点标签的 valuecontainers:- name: with-node-affinityimage: k8s.gcr.io/pause:3.1从上面的 yaml 定义中可以看到 In 操作符,我们来回顾下 NodeAffinity 语法支持的操作符包括:In、NotIn、Exists、DoesNotExists、Gt、Lt。虽然没有节点互斥功能,但可以用 NotIn 和 DoesNotExists 来实现节点互斥功能。
说明:上面的 NodeAffinity 示例中,定义了两个硬性规则条件,分别是 地区(zone) 和 架构(arch ),另外定义了一个软性规则条件,那就是 硬盘类型(disk-type),k8s 的默认调度器 Schedule 服务(kube-scheduler 进程) 则遵循定义规则实现该 Pod 的调度,整个过程全部自动完成,无需人工干预。
逐个调度方案中设置节点亲和性
【特性状态】: Kubernetes v1.20 [beta]
在配置多个调度方案时, 如果某个调度方案仅适用于某组特殊的节点时,可以将该方案与节点亲和性关联起来, 这样做是很有用的。要实现这点,可以在 调度器配置 中为 NodeAffinity 插件的 args 字段添加 addedAffinity。
示例:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
...
profiles:- schedulerName: default-scheduler- schedulerName: foo-schedulerpluginConfig:- name: NodeAffinityargs:addedAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: scheduler-profileoperator: Invalues:- foo这里的 addedAffinity 除遵从 Pod 规约 space 中设置的 NodeAffinity(节点亲和性) 之外, 还适用于将 .spec.schedulerName 设置为 foo-scheduler。 换言之,为了匹配 Pod,node 节点需要满足 addedAffinity 和 Pod 的 .spec.NodeAffinity。
注意:由于
addedAffinity对最终用户不可见,其行为可能对用户而言是出乎意料的。 应该使用与调度方案名称有明确关联的节点标签。
说明:DaemonSet 控制器为 DaemonSet 创建 Pods, 但该控制器不理会调度方案。 DaemonSet 控制器创建 Pod 时,默认的 Kubernetes 调度器(kube-scheduler)负责放置 Pod, 并遵从 DaemonSet 控制器中奢侈的 nodeAffinity 规则。
NodeAffinity 规则设置说明
如果同时定义了
nodeSelector和NodeAffinity,这两个条件必须满足(and 关系),Pod 才能最终运行在指定的 Node 上。如果
NodeAffinity指定了多个nodeSelectorTerms,其中一个条件能够匹配成功即可(or 关系)。如果在
nodeSelectorTerms中有多个matchExpressions,则目标 Node 必须满足所有matchExpressions才能运行该 Pod(and 关系)。
节点亲和性权重(weight)
可以为 preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置 weight 字段,其 取值范围是 1 到 100。 当调度器找到能够满足 Pod 的其他调度请求的 node 节点时,调度器会遍历 node 满足的所有的偏好性规则, 并将对应表达式的 weight 值加和。
最终的加和值会添加到该节点的其他优先级函数的评分之上。 在调度器为 Pod 作出调度决定时,总分最高的节点的优先级也最高。
Pod 规约的 with-affinity-anti-affinity.yaml 文件定义示例:
apiVersion: v1
kind: Pod
metadata:name: with-affinity-anti-affinity
spec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/osoperator: Invalues:- linuxpreferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: label-1operator: Invalues:- key-1- weight: 50preference:matchExpressions:- key: label-2operator: Invalues:- key-2containers:- name: with-node-affinityimage: k8s.gcr.io/pause:3.1如果存在两个候选节点,都满足 preferredDuringSchedulingIgnoredDuringExecution 规则, 其中一个节点具有标签 label-1:key-1,另一个节点具有标签 label-2:key-2, 调度器会考察各个节点的 weight 取值,并将该权重值添加到节点的其他得分值之上。
说明:如果你希望 k8s 能够成功地调度此例中的 Pod,你必须拥有打了
kubernetes.io/os=linux标签的节点。
Pod 间亲和性和互斥性调度(PodAffinity & PodAntiAffinity)
【特性状态】: Kubernetes v1.4 引入
Pod 间亲和性(PodAffinity)与反亲和性(也叫互斥性,PodAntiAffinity)使你可以 基于已经在节点上运行的 Pod 的标签来约束 Pod 可以调度到的节点,而不是基于节点上的标签。
PodAffinity 与 PodAntiAffinity 的 规则格式 为 “如果 **X** 上已经运行了一个或多个满足规则 **Y** 的 Pod, 则这个 Pod 应该(或者在反亲和性的情况下不应该)运行在 **X** 上”。 这里的 **X** 可以是节点、机架、云提供商可用区或地理区域或类似的拓扑域, **Y** 则是 Kubernetes 尝试满足的规则。
topology.kubernetes.io/hostname,节点topology.kubernetes.io/zone,机架topology.kubernetes.io/region,区域
通过 标签选择算符 的形式来表达规则 (Y),并可根据需要指定选择关联的 Namespace(名字空间) 列表。 Pod 在 k8s 中是 Namespace 作用域的对象,因此 Pod 的标签也隐式地具有 Namespace 属性。 针对 Pod 标签的所有标签选择算符都要指定 Namespace,k8s 会在指定的 Namespace 内寻找 Label 标签。
通过 topologyKey 来表达 拓扑域 (X) 的概念,其取值是系统用来表示域的 节点标签键。 相关示例可参见常用 标签、注解和污点。
【标签、注解和污点】参考文档:,https://kubernetes.io/zh-cn/docs/reference/labels-annotations-taints/。
【说明】
Pod 间亲和性和反亲和性都需要相当的计算量,因此会在大规模集群中显著降低调度速度。不建议在包含数百个节点的集群中使用这类设置。Pod 反亲和性需要节点上存在一致性的标签(交集)。换言之, 集群中每个节点都必须拥有与topologyKey匹配的标签。 如果某些或者所有节点上不存在所指定的topologyKey标签,调度行为可能与预期的不同。
Pod 间亲和性与反亲和性类型
与节点亲和性(NodeAffinity)类似,Pod 间的 PodAffinity & PodAntiAffinity (亲和性与反亲和性)也有两种类型:
requiredDuringSchedulingIgnoredDuringExecution,硬性条件,必须满足。preferredDuringSchedulingIgnoredDuringExecution,软性条件,尝试满足(优先级依据权重weight)。
要使用 Pod 间亲和性(PodAffinity),可以使用 Pod 规约 spec 中的 spec.affinity.podAffinity 字段。 对于 Pod 间反亲和性(PodAntiAffinity ),可以使用 Pod 规约中的 spec.affinity.podAntiAffinity 字段。
Pod 间亲和性与反亲和性示例
with-pod-affinity.yaml 定义文件
apiVersion: v1
kind: Pod
metadata:name: with-pod-affinity
spec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: securityoperator: Invalues:- S1topologyKey: topology.kubernetes.io/zonepodAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 100podAffinityTerm:labelSelector:matchExpressions:- key: securityoperator: Invalues:- S2topologyKey: topology.kubernetes.io/zonecontainers:- name: with-pod-affinityimage: k8s.gcr.io/pause:3.1with-pod-affinity.yaml 文件定义说明:
亲和性(podAffinity.requiredDuringSchedulingIgnoredDuringExecution)规则表示,仅当节点和至少一个已运行且有security=S1的标签的 Pod 处于同一区域时,才可以将该 Pod 调度到节点上。 更确切的说,调度器必须将 Pod 调度到具有topology.kubernetes.io/zone=V标签的节点上,并且集群中至少有一个位于该可用区的节点上运行着带有 security=S1 标签的 Pod。反亲和性(podAntiAffinity.preferredDuringSchedulingIgnoredDuringExecution)规则表示,如果节点处于 Pod 所在的同一可用区且至少一个 Pod 具有security=S2标签,则该 Pod 不应被调度到该节点上。 更确切地说, 如果同一可用区中存在其他运行着带有security=S2标签的 Pod 节点, 并且节点具有标签topology.kubernetes.io/zone=R,Pod 不能被调度到该节点上。
Pod 间亲和性与反亲和性(PodAffinity & PodAntiAffinity)为其 operator(操作符) 字段使用 In、NotIn、Exists、 DoesNotExist 、Gt、Lt 值。
topologyKey 限制规则
原则上,topologyKey(拓扑逻辑) 可以是任何合法的 标签键。出于性能和安全原因,topologyKey 有一些限制:
对于 Pod 亲和性而言,在
requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中,topologyKey不允许为空。对于
requiredDuringSchedulingIgnoredDuringExecution要求的 Pod 反亲和性, 如果Admission controller(准入控制器)包含了LimitPodHardAntiAffinityTopology,针对requiredDuringScheduling的 Pod 互斥性要求topologyKey只能是kubernetes.io/hostname。如果要使用其他定制或自定义的topologyKey,需要更改或禁用该Admission controller。在
requiredDuringScheduling类型的 Pod 互斥性定义中,空的topologyKey会被解释为kubernetes.io/hostname、failure-domain.beta.kubernetes.io/zone 及 failure-domain.beta.kubernetes.io/region的组合。除开上述情况,可以使用任意合法的
topologyKey。
PodAffinity 规则设置说明
除了
labelSelector和topologyKey,你也可以指定labelSelector要匹配的Namespace(命名空间)列表,方法是在labelSelector和topologyKey所在层同一层次上设置namespaces。 如果namespaces被忽略或者为空(""),则默认为 Pod 亲和性/反亲和性的定义所在的namespaces命名空间。在所关联的
requiredDuringSchedulingIgnoredDuringExecution的matchExpressions全部满足之后,系统才能将 Pod 调度到某个 Node 上。
关于【亲和性】更多信息,请查看:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/#affinity-and-anti-affinity
Namespaces 选择算符
【特性状态】: Kubernetes v1.24 [stable]
我们也可以使用 namespaceSelector 选择匹配的 namespaces,namespaceSelector 是对名字空间集合进行标签查询的机制。 亲和性条件会应用到 namespaceSelector 所选择的名字空间和 namespaces 字段中所列举的名字空间之上。 注意,空的 namespaceSelector({}) 会匹配所有名字空间,而 null 或者空 的 namespaces 列表以及 null 值 namespaceSelector 意味着 “当前 Pod 的名字空间”。
生产环境中更多的实际示例
Pod 间亲和性与反亲和性在与更高级别的集合(例如 ReplicaSet、StatefulSet、 Deployment 等)一起使用时,它们可能更加有用。 这些规则使得你可以配置一组工作负载,使其位于所定义的同一拓扑中; 例如优先将两个相关的 Pod 置于相同的节点上。
以一个三 node 的集群为例,使用 Pod 间的 PodAffinity & PodAntiAffinity 来尽可能地将该 Web 服务器与缓存服务器(例如:Redis)并置,部署规格如下列表:
| node-1 | node-2 | node-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
redis-cache_web-server.yaml 文件定义如下:
apiVersion: apps/v1
kind: Deployment
metadata:name: redis-cache
spec:selector:matchLabels:app: storereplicas: 3 # 设置 Pod 实例副本数量template:metadata:labels:app: storespec:affinity:# Pod 反亲和性(互斥性)podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: "kubernetes.io/hostname"containers:- name: redis-serverimage: redis:7.0.4-alpine
---
apiVersion: apps/v1
kind: Deployment
metadata:name: web-server
spec:selector:matchLabels:app: web-storereplicas: 3template:metadata:labels:app: web-storespec:affinity:# Pod 反亲和性(互斥性)podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- web-storetopologyKey: "kubernetes.io/hostname"podAffinity:# Pod 亲和性requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: "kubernetes.io/hostname"containers:- name: web-appimage: nginx:1.23.1-alpine创建上面的 Deployment 对象资源:
kubectl create -f redis-cache_web-server.yaml查看创建的 Deployment 对象信息:
kubectl get deployment redis-cache, web-server参考文档:
将 Pod 指派给节点,https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/
Taints & Tolerations,污点和容忍调度
上面介绍的 NodeAffinity (节点亲和性),是在 Pod 上定义的一种属性,使得 Pod 能够被调度到一类特定的节点 (这可能出于一种偏好或软性条件,也可能是硬性强制要求)。接下来我们介绍的 Taints(污点)则与之相反,它 让 Node 拒绝运行 Pod(排斥一类特定的 Pod)。
同样 Toleration 也是 Pod 的属性,容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应 Taints(污点) 的 Pod。 容忍度允许调度但并不保证调度:作为其功能的一部分, 调度器也会评估其他参数。
Taint(污点)需要和 Toleration(容忍调度)配合使用,可以用来避免 Pod 被分配到不合适的 Node 上。在每个 node 上都可以设置一个或多个 Taint ,除非 Pod 明确声明能够 Toleration(容忍)这些 Taint ,否则无法在这些 Node 上运行该 Pod。
使用命令为 Node 设置 Taint 信息:
kubectl taint nodes k8s-node-01 key=value:NoSchedule接下来在 Pod 上申明 Toleration 属性,如下示例:
tolerations:
- key: "key"operator: "Equal"value: "value"effect: "NoSchedule"或者
tolerations:
- key: "key"operator: "Exists"effect: "NoSchedule"Pod 的 Toleration 声明中的 key 和 effect 需要与 Taint 的设置保持一致,并且满足以下条件之一:
operator 的值是 Exists(无需指定 value)。
operator 的值是 Equal 需要设置 value 并且相等。
如果不指定 operator(操作符),默认值是 Equal 。另外,还有两个特例如下:
空("")的 key 配合 Exists 操作符能够匹配所有的 key 和 value。
空("")的 effect 匹配所有的 effect。
在上面的示例中,effect 设置调度优先级,其取值为:NoSchedule,PreferNoSchedule、NoExecute。
PreferNoSchedule 可以看作是 NoSchedule 的软限制版,一个 Pod 如果没有声明容忍这个 Taint,则系统会尽量避免把这个 Pod 调度到对应 Taint 标记的 Node 上,但不是强制的。
k8s 系统允许在同一个 Node 上设置多个 Taint,也可以在 Pod 上设置多个 Toleration。
调度器处理污点和容忍的逻辑顺序
k8s 调度器(kube-scheduler) 处理多个 Taint(污点) 和 Toleration(容忍) 的逻辑顺序:
首先列出 node 中的所有 Taint;
然后忽略 Pod 的 Toleration 能够匹配的部分;
剩余的没有忽略 Taint 的 node 就是对 Pod 的效果了。
在剩余的没有忽略 Taint 的 node 中,有以下几种特殊情况:
如果在剩余的
Taint中存在effect=NoSchedule,则调度器不会把该 Pod 调度到这个 node 上。如果在剩余的
Taint中没有NoSchedule效果,但是有PreferNoSchedule效果,则调度器会尝试不把该 Pod 指派给这个node上。如果在剩余的
Taint中有NoExecute效果,并且这个 Pod 已经在该 Node 上运行,则会被驱逐;如果没有在该Node上运行,则也不会再被调度到该Node上运行。
使用 Toleration 的 Pod 示例
apiVersion: v1
kind: Pod
metadata:name: nginxlabels:env: test
spec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresenttolerations:- key: "example-key"operator: "Exists"effect: "NoSchedule"Taint 和 Toleration 应用示例
举例,我们使用一个 node(名称为 k8s-node-01) 进行 Taint 设置:
kubectl taint nodes k8s-node-01 key1=value1:NoSchedule
kubectl taint nodes k8s-node-01 key1=value1:NoExecute
kubectl taint nodes k8s-node-01 key2=value2:NoSchedule然后在 Pod 上设置两个 Toleration :
tolerations:
- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"
- key: "key1"operator: "Equal"value: "value1"effect: "NoExecute"这样的 Toleration 的设置结果是 Pod 无法调度到 k8s-node-01 上,因为上面命令行中第三个 Taint 没有匹配的 Toleration。但是如果该 Pod 已经在 k8s-node-01 上运行了,那么在运行时设置第三个 Taint,该 Pod 还能继续在 k8s-node-01 上运行,因为该 Pod 可以容忍前两个 Taint。
一般情况,如果给 Node 加上 effect=NoSchedule 的 Taint,那么在该 Node 上运行的所有无对应 Toleration 的 Pod 都会被立刻驱逐,而具有相应 Toleration 属性的 Pod 永远不会被驱逐。不过,k8s 系统允许给具有 NoExecute 效果的 Toleration 加入一个可选的 tolerationSeconds 字段,这个字段设置表明 Pod 可以在 Taint 添加到 Node 之后还能在这个 Node 上运行多久(单位:s)。如下示例:
tolerations:
- key: "key1"operator: "Equal"value: "value1"effect: "NoExecute"tolerationSeconds: 3600上面 yaml 定义的意思是,如果 Pod 正在运行,所在 node 都被加入一个匹配的 Taint,这个 Pod 会持续在该 node 上存活 3600s 后被驱逐出。如果在这个宽限期内 Taint 被移除,则不会触发驱逐事件。
Taint 和 Toleration 常见用例
通过上面的示例,可以得知 Taint 和 Toleration 是一种处理 node 并且让 Pod 进行规避或者驱逐 Pod 的弹性处理方式,接下来我们列举一些常见的用例。
1. 专用(或独占)node
如果想想要拿出一部分 node 专门给特定的应用使用,则可以为 node 添加这样的 Taint,如下所示:
kubectl taint nodes nodename dedicated=groupName:NoSchedule然后给这些应用 Pod 加入 Taint 对应的 Toleration。这样,带有合适 Toleration 的 Pod 就会被允许使用其他节点一样使用 Taint 的 node。
通过自定义 Admission Controller 也可以实现这一目标,如果希望让这些应用独占一批 node,并且确保它们只能使用这些 node,则还可以给这些 Taint 节点加人类似的标签 dedicated=groupName,然后 Admission Controller 需要加入 NodeAffinity(节点亲和性) 设置,要求 Pod 只会被调度到具有这一标签的 node 上。
2. 具有特殊硬件设备的 node
在集群里可能有一小部分节点安装了特殊的硬件设备(如 GPU芯片),希望把不需要占用这类硬件的 Pod 排除在外,以确保对这类硬件有需求的 Pod 能够被顺利调度到这些节点。
可以用下面的命令为 node 设置 Taint:
kubectl taint nodes nodename special=true:Roschedule
kubectl taint nodes nodename special=true:PrefezNoschedule然后在 Pod 中利用对应的 Toleration 来保障特定的 Pod 能够使用特定的硬件环境。
和上面的 独占 node 的示例类似,使用 Admission Controller 来完成这一任务会更方便。例如,Admission Controller 使用 Pod 的一些特征来判断这些 Pod,如果可以使用这些硬件,就添加 Toleration 来完成这一工作。要保障需要使用特殊硬件的 Pod 只被调度到安装这些硬件的节点上,则还需要一些额外的工作,比如:将这些特殊资源使用 opaque-int-resource 的方式对自定义资源进行量化,然后在 PodSpec 中进行请求;也可以使用标签的方式来标注这些安装有特别硬件的节点,然后在 Pod 中定义 NodeAffinity(节点亲和性)来实现这个目标。
3. 基于 Taint(污点)的驱逐
【特性状态】: Kubernetes v1.18 [stable]
定义 Pod 驱逐行为,以应对 node 故障,这是在每个 Pod 中配置的在 node 出现问题时的驱逐行为。前面提到的 NoExecute 这个 Taint 效果对 node 上正在运行的 Pod 有以下影响。
没有设置 Toleration 的 Pod 会被立刻驱逐。
配置了对应 Toleration 的 Pod,如果没有为
tolerationSeconds赋值,则会一直留在这一 node 中。配置了对应 Toleration 的 Pod 且指定了
tolerationSeconds值,则会在指定时间段后驱逐。
举例,当网络出现故障时(网络中断),对于一个与节点本地状态有着深度绑定的应用而言,仍然停留在当前节点上运行一段较长的时间,以等待网络恢复以避免被驱逐。 此时可以为 Pod 设置的容忍度,如下所示:
tolerations:
- key: "node.kubernetes.io/unreachable"operator: "Exists"effect: "NoExecute"tolerationSeconds: 6000说明: Kubernetes 会自动给 Pod 添加针对
node.kubernetes.io/not-ready和node.kubernetes.io/unreachable的容忍度,且配置 tolerationSeconds=300, 除非用户自身或者某控制器显式设置此容忍度。 这些自动添加的容忍度意味着 Pod 可以在检测到对应的问题之一时,在 5 分钟内保持绑定在该节点上。
DaemonSet 中的 Pod 被创建时,针对以下污点自动添加的 NoExecute 的容忍度将不会指定 tolerationSeconds:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
这保证了出现上述问题时 DaemonSet 中的 Pod 永远不会被驱逐。
4. 基于 node 状态添加 Taint(污点)
控制平面使用 节点控制器 自动创建 与 节点状况 对应的、效果为 NoSchedule 的 Taint(污点)。
调度器在进行调度时检查污点,而不是检查节点状况。这确保节点状况不会直接影响调度。
例如:
如果
DiskPressure节点状况处于活跃状态,则控制平面添加node.kubernetes.io/disk-pressure污点并且不会调度新的 Pod 到受影响的节点。如果
MemoryPressure节点状况处于活跃状态,则控制平面添加node.kubernetes.io/memory-pressure污点并且不会调度新的 Pod 到受影响的节点。
推荐参考文档:
《污点和容忍度》https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/taint-and-toleration/
《众所周知的标签、注解和污点》https://kubernetes.io/zh-cn/docs/reference/labels-annotations-taints/
未完待续
“夜好深了,纸窗里怎么亮着?” 好了先分享到这里,下一篇文章我们继续讲解,比如:Pod 优先级调度、DaemonSet 调度,Job 批处理调度,CronJob 定时任务 以及 自定义调度器。感兴趣的小伙伴,欢迎关注我,一起学习,一起成长哦!

)





)

)


)



方法 - Python 教程 - 自强学堂)
依赖注入 —— 比较依赖范围)

