背景介绍:单位实习,趁机摸鱼,由于电脑只安装了VSCode,所以算是从环境搭建写起。
目录
一、环境搭建
1. 安装Anaconda
2. 创建Python环境
3. 安装PyTorch
4. 安装其他必要库
二、在 VSCode 中配置环境
1. 安装Python扩展
2. 选择正确的 Python 解释器
三、实验过程
1. 实验代码
2. 运行结果和输出编辑
四、任务详细解析
1. 需求分析
2. 原理详解
1)数据预处理
2)CNN 网络结构分析
3)CNN 关键设计原理
4)特征提取原理
5)训练优化原理
3. 性能分析与优化
1)模型复杂度分析
2)性能优化策略
五、实验报告和讲解PPT
一、环境搭建
1. 安装Anaconda
1. 访问 Anaconda官网 下载适合你操作系统的版本,这里建议选择 Mimiconda 安装。
选择 Mimiconda 的原因:
轻量级: 只包含conda、Python和少量必要包,下载快速灵活性: 可以根据需要安装特定的包,避免不必要的软件
环境管理: 更好的虚拟环境管理功能
适合深度学习: 对于我们的PyTorch项目来说完全够用
按步骤下载安装,勾选时全部选上,其余按照默认即可。
安装完毕后,打开 cmd 验证是否安装成功,有版本输出即为安装成功。
conda --version
python --version

2. 安装完成后,打开Anaconda Prompt(Windows)或终端(Mac/Linux)
2. 创建Python环境
# 创建新的conda环境
conda create -n pytorch_env python=3.9
# 激活环境
conda activate pytorch_env
创建之后一定再次检查 python 版本,作业要求最好使用 3.9 版本

3. 安装PyTorch
访问 PyTorch官网 获取安装命令,或直接使用:
- CPU版本:
pip install torch torchvision torchaudio
- GPU版本(如果有NVIDIA显卡):此刻经历漫长的等待时间... ...
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
4. 安装其他必要库
pip install matplotlib numpy jupyter
二、在 VSCode 中配置环境
我安装环境时 已经在 VSCode 中进行了, 所以可以忽略第二步
1. 安装Python扩展
2. 选择正确的 Python 解释器
在 VSCode 中按 Ctrl+Shift+P
输入:Python: Select Interpreter
选择 pytorch_env 环境的 Python,例:
C:\Users\nnchen\AppData\Local\miniconda3\envs\pytorch_env\python.exe
三、实验过程
1. 实验代码
# 创建完整的手写数字识别代码 - 英文版图表
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用设备: {device}')# 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True
)test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True
)# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)print(f'训练集大小: {len(train_dataset)}')
print(f'测试集大小: {len(test_dataset)}')# 定义CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()# 第一个卷积层self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)self.pool1 = nn.MaxPool2d(2, 2)# 第二个卷积层self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.pool2 = nn.MaxPool2d(2, 2)# 第三个卷积层self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 全连接层self.fc1 = nn.Linear(128 * 7 * 7, 512)self.fc2 = nn.Linear(512, 128)self.fc3 = nn.Linear(128, 10)# Dropout层防止过拟合self.dropout = nn.Dropout(0.5)def forward(self, x):# 卷积层1 + ReLU + 池化x = self.pool1(F.relu(self.conv1(x)))# 卷积层2 + ReLU + 池化x = self.pool2(F.relu(self.conv2(x)))# 卷积层3 + ReLUx = F.relu(self.conv3(x))# 展平x = x.view(-1, 128 * 7 * 7)# 全连接层x = F.relu(self.fc1(x))x = self.dropout(x)x = F.relu(self.fc2(x))x = self.dropout(x)x = self.fc3(x)return x# 创建模型实例
model = CNN().to(device)
print(model)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练函数
def train_model(model, train_loader, criterion, optimizer, epochs=10):model.train()train_losses = []train_accuracies = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)# 梯度清零optimizer.zero_grad()# 前向传播output = model(data)loss = criterion(output, target)# 反向传播loss.backward()optimizer.step()# 统计running_loss += loss.item()_, predicted = torch.max(output.data, 1)total += target.size(0)correct += (predicted == target).sum().item()if batch_idx % 200 == 0:print(f'Epoch [{epoch+1}/{epochs}], Step [{batch_idx}/{len(train_loader)}], 'f'Loss: {loss.item():.4f}')epoch_loss = running_loss / len(train_loader)epoch_acc = 100 * correct / totaltrain_losses.append(epoch_loss)train_accuracies.append(epoch_acc)print(f'Epoch [{epoch+1}/{epochs}] - Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%')return train_losses, train_accuracies# 测试函数
def test_model(model, test_loader):model.eval()correct = 0total = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)_, predicted = torch.max(output, 1)total += target.size(0)correct += (predicted == target).sum().item()accuracy = 100 * correct / totalprint(f'测试集准确率: {accuracy:.2f}%')return accuracy# 可视化函数 - 修改为英文标题
def visualize_predictions(model, test_loader, num_images=10):model.eval()images, labels = next(iter(test_loader))images, labels = images.to(device), labels.to(device)with torch.no_grad():outputs = model(images)_, predicted = torch.max(outputs, 1)# 移到CPU进行可视化images = images.cpu()labels = labels.cpu()predicted = predicted.cpu()fig, axes = plt.subplots(2, 5, figsize=(12, 6))for i in range(num_images):ax = axes[i//5, i%5]ax.imshow(images[i].squeeze(), cmap='gray')ax.set_title(f'True: {labels[i]}, Pred: {predicted[i]}')ax.axis('off')# 总标题plt.suptitle('MNIST Digit Recognition Results', fontsize=16)plt.tight_layout()plt.show()# 开始训练
print("开始训练模型...")
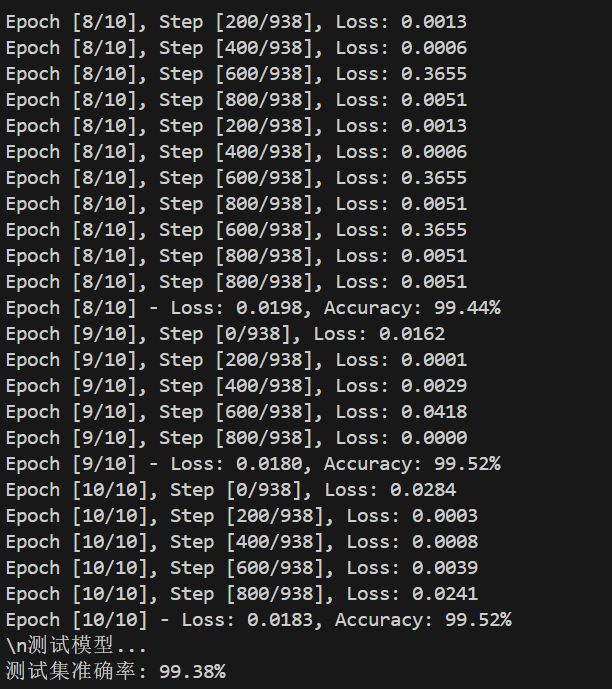
train_losses, train_accuracies = train_model(model, train_loader, criterion, optimizer, epochs=10)# 测试模型
print("\n测试模型...")
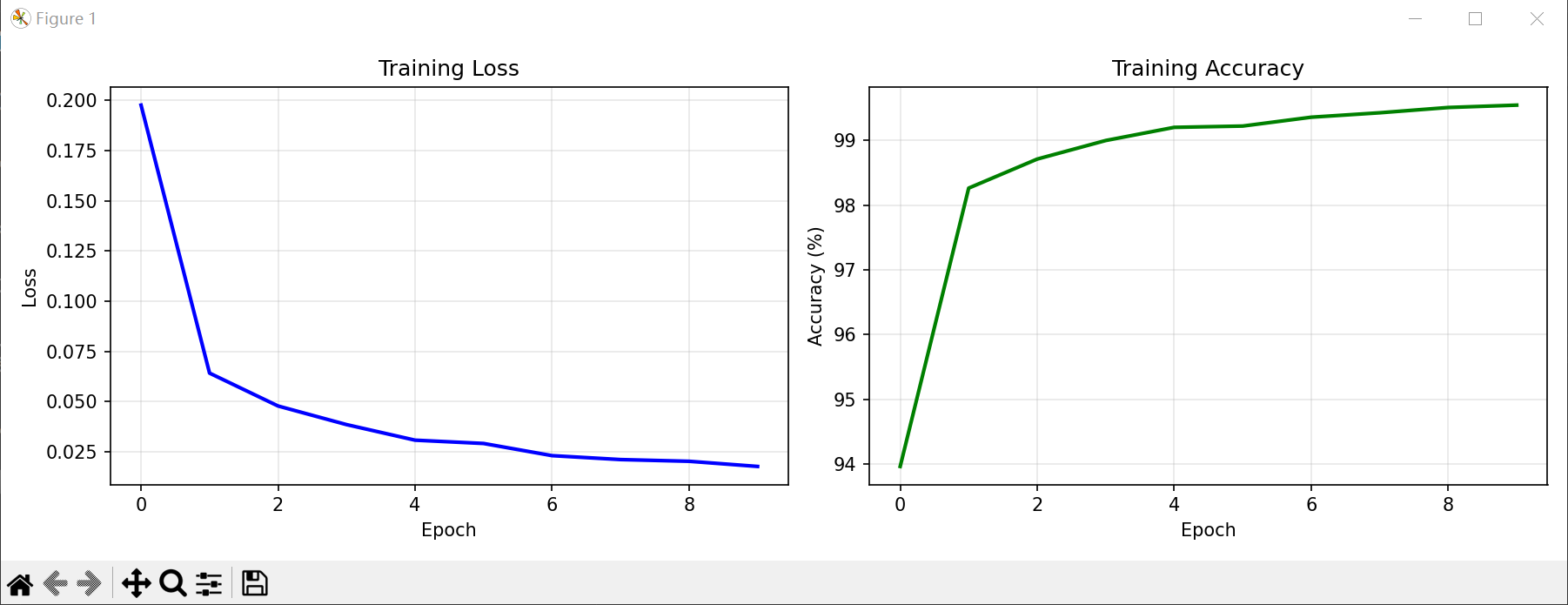
test_accuracy = test_model(model, test_loader)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)
plt.plot(train_losses, 'b-', linewidth=2)
plt.title('Training Loss') # 改为英文
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True, alpha=0.3)plt.subplot(1, 2, 2)
plt.plot(train_accuracies, 'g-', linewidth=2)
plt.title('Training Accuracy') # 改为英文
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.grid(True, alpha=0.3)plt.tight_layout()
plt.show()# 可视化预测结果
print("\n可视化预测结果...")
visualize_predictions(model, test_loader)# 保存模型
torch.save(model.state_dict(), 'mnist_cnn_model.pth')
print("\n模型已保存为 mnist_cnn_model.pth")print(f"\n实验完成!最终测试准确率: {test_accuracy:.2f}%")
if test_accuracy >= 98.0:print("✅ 成功达到98%以上的准确率要求!")
else:print("⚠️ 未达到98%准确率要求,可以尝试调整超参数或增加训练轮数")
2. 运行结果和输出

四、任务详细解析
1. 需求分析
-
目标:构建一个能够识别手写数字(0-9)的深度学习模型
-
数据集:MNIST手写数字数据集
-
期望准确率:≥98%
-
技术要求:使用卷积神经网络(CNN)实现
# 功能需求
✅ 数据加载与预处理
✅ CNN模型设计与实现
✅ 模型训练与验证
✅ 性能评估与可视化
解决方案
数据加载 → 数据预处理 → 模型设计 → 训练 → 测试 → 可视化
↓ ↓ ↓ ↓ ↓ ↓
MNIST 标准化处理 CNN架构 优化器 评估 图表
2. 原理详解
1)数据预处理
标准化处理:
transforms.Normalize((0.1307,), (0.3081,))
原理解析:
均值: 0.1307 是MNIST数据集的全局均值
标准差: 0.3081 是MNIST数据集的全局标准差
公式:
作用机制:
# 原始像素值范围:[0, 255] → [0, 1] (ToTensor)
# 标准化后范围:约[-2, 2],均值≈0,标准差≈1
2)CNN 网络结构分析
输入: 1×28×28 (灰度图像)↓
Conv1: 1→32, 3×3, padding=1↓ (32×28×28)
MaxPool1: 2×2↓ (32×14×14)
Conv2: 32→64, 3×3, padding=1↓ (64×14×14)
MaxPool2: 2×2↓ (64×7×7)
Conv3: 64→128, 3×3, padding=1↓ (128×7×7)
Flatten: 128×7×7 = 6272↓
FC1: 6272→512↓
Dropout(0.5)↓
FC2: 512→128↓
Dropout(0.5)↓
FC3: 128→10 (输出层)
3)CNN 关键设计原理
卷积层设计:
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
- kernel_size=3:3×3卷积核,平衡感受野和计算效率
- padding=1:保持特征图尺寸不变
- 通道数递增:32→64→128,逐步提取复杂特征
池化层作用:
self.pool1 = nn.MaxPool2d(2, 2)
- 降采样:减少参数量和计算量
- 平移不变性:增强模型鲁棒性
- 感受野扩大:捕获更大范围特征
Dropout 机制:
self.dropout = nn.Dropout(0.5)
- 正则化:随机丢弃50%神经元
- 防止过拟合:提高泛化能力
- 集成学习效果:相当于训练多个子网络
4)特征提取原理
层级特征学习:
# 第一层:边缘检测
Conv1 → 检测基本边缘、线条# 第二层:形状组合
Conv2 → 组合边缘形成简单形状# 第三层:复杂模式
Conv3 → 识别数字的复杂模式和结构
感受野计算:
# 感受野公式:RF = (RF_prev - 1) * stride + kernel_size
Layer 1: RF = 3
Layer 2: RF = (3-1)*2 + 3 = 7
Layer 3: RF = (7-1)*2 + 3 = 15
5)训练优化原理
Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
交叉熵损失:
criterion = nn.CrossEntropyLoss()
3. 性能分析与优化
1)模型复杂度分析
参数量计算:
Conv1: 1×32×3×3 + 32 = 320
Conv2: 32×64×3×3 + 64 = 18,496
Conv3: 64×128×3×3 + 128 = 73,856
FC1: 6272×512 + 512 = 3,211,776
FC2: 512×128 + 128 = 65,664
FC3: 128×10 + 10 = 1,290总参数量 ≈ 3.37M
计算复杂度:
# FLOPs (浮点运算次数)
Conv层: O(H×W×C_in×C_out×K²)
FC层: O(N_in×N_out)总FLOPs ≈ 50M (前向传播)
2)性能优化策略
数据增强:
# 可添加的数据增强
transforms.Compose([transforms.RandomRotation(10), # 随机旋转transforms.RandomAffine(0, translate=(0.1, 0.1)), # 平移transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])
学习率调度:
# 学习率衰减
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
早停机制:
# 防止过拟合
if val_loss > best_val_loss:patience_counter += 1if patience_counter >= patience:break
五、实验报告和讲解PPT
想看?不给,嘿嘿嘿





 和管理平台之unleash)



)








)
