软活硬整,纳什又把RL翻出来讲了一遍,我以为是温故而知新,原来是在卖书。
不过温故而知新还是没啥毛病的。
PS:今天装Notepad++时看到的,我还以为现在连用个Notepad++都要给天线宝宝们捐款了。
文章目录
- PART 1
- 1 overview
- 2 highlights
- 3 Core concepts
- 3.1 R T R_T RT v.s. G t G_t Gt
- 3.2 value/advantage function
- 3.3 Bellman equation
- 3.4 MC v.s. TD
- 4 Policy Gradient
- 4.1 ∇ θ J ( θ ) ≈ ∑ t = 0 T − 1 ∇ θ log π θ ( A t ∣ S t ) ⏟ 方向 G t ⏟ 幅度与符号 ∇_θ J(θ) \approx \sum_{t=0}^{T-1} \underbrace{∇_θ \log π_θ(A_t|S_t)}_{\text{方向}} \underbrace{G_t}_{\text{幅度与符号}} ∇θJ(θ)≈∑t=0T−1方向 ∇θlogπθ(At∣St)幅度与符号 Gt
- 4.2 G t G_t Gt的高方差、信用分配问题
- 4.3 TRPO v.s. PPO
- 4.3.1 on-policy v.s. off-policy
- 5 RL v.s. SFT
- 6 DeepSeekMath Unified Paradigm
- PART 2
PART 1
video: https://www.bilibili.com/video/BV1i8TQzuEKs
code: https://github.com/chunhuizhang/modern_ai_for_beginners/blob/main/books_reading_notes/RL/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E7%9A%84%E6%95%B0%E5%AD%A6%E5%8E%9F%E7%90%86.ipynb
1 overview
https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning
- Chap1:基本概念
- Chap2-Chap8:value-based methods
- 先估计值再得到最优策略;
- 估计一个策略的 action value,就叫 policy evaluation,在此基础上选择更好的策略,再去进行采样然后不断地迭代循环;
- Chap2-3:Bellman equation
- Chap4:VI(Value Iteration)& PI(Policy Iteration)
- Chap5:MC (monte-carlo 方法,model-free)
- Chap7:TD
- 先估计值再得到最优策略;
- Chap9-10:policy-based methods,直接优化关于策略参数 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 的目标函数(通过优化这个目标函数直接得到最优策略)
- Chap9:PG(policy gradient)
- https://www.bilibili.com/video/BV1sd4y167NS
- 策略梯度定理
- simple code:
- https://www.datacamp.com/tutorial/policy-gradient-theorem
- simple code:
- Chap10:Actor-Critic (A2C),融合了基于策略和基于价值的两类方法
- Actor:策略更新
- Critic:价值更新
- Chap9:PG(policy gradient)
- 这本书跟神经网络或者DRL是兼容的
- 比如这里就有:
- 【强化学习的数学原理】课程:从零开始到透彻理解(完结):https://www.bilibili.com/video/BV1sd4y167NS
- 用函数(而非表格)表示时, v w ( s ) , π θ ( a ∣ s ) v_w(s), \pi_\theta(a|s) vw(s),πθ(a∣s) 均可以为神经网络 parameterized by w , θ w, \theta w,θ respectively
- 比如这里就有:
2 highlights
从现代应用的视角,rlhf (ppo), rl4llm (ppo-variants)
- policy gradient 之于 RL,犹如 attention 之于 transformer
- 很基础很本质,很核心
- 像一个分水岭,
- 往后就是一系列应用(rl4llm,policy-gradient based 方法是 most popular 的方法)
- 往前就是 RL 基础概念基本原理的准备;
3 Core concepts
3.1 R T R_T RT v.s. G t G_t Gt
J ( θ ) = E [ G t ] = E [ G 0 ] J ( θ ) = E τ ∼ π θ [ G 0 ] = E τ ∼ π θ [ ∑ t = 0 T − 1 γ t R t + 1 ] \begin{split} &J(\theta) = E[G_t]=E[G_0]\\ &J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[G_0] = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T-1} \gamma^t R_{t+1} \right] \end{split} J(θ)=E[Gt]=E[G0]J(θ)=Eτ∼πθ[G0]=Eτ∼πθ[t=0∑T−1γtRt+1]
- 奖励(reward, R t R_t Rt)与回报(return, G t G_t Gt)
- R t R_t Rt:智能体在特定时间点 t t t 完成某个动作后立即给予的反馈。
- ( s t , a t , r t + 1 ) (s_t, a_t, r_{t+1}) (st,at,rt+1)
- G t G_t Gt:回报是衡量从某一时刻开始,直到“一局游戏”结束,智能体能够获得的“总奖励”是多少。因为未来的奖励可能不如眼前的奖励那么确定或有价值,我们通常会给未来的奖励打个折扣。
- discounted cumulative future reward
- G t = ∑ k = t + 1 T γ k − t r k G_t = \sum_{k=t+1}^T γ^{k-t} r_k Gt=∑k=t+1Tγk−trk
- R t R_t Rt:智能体在特定时间点 t t t 完成某个动作后立即给予的反馈。
- 智能体的目标不是最大化瞬时奖励 R t R_t Rt,而是最大化累积奖励。
3.2 value/advantage function
- 状态价值函数: V ( s ) V(s) V(s)
- V π ( s ) = E π [ G t ∣ S t = s ] V_π(s) = E_π[G_t | S_t = s] Vπ(s)=Eπ[Gt∣St=s]
- 动作值函数: Q ( s , a ) Q(s,a) Q(s,a)
- Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q_π(s,a) = E_π[G_t | S_t = s, A_t = a] Qπ(s,a)=Eπ[Gt∣St=s,At=a]
- G t G_t Gt 是对 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ(st,at) 的无偏采样。
- 优势函数 (Advantage Function, A ( s , a ) A(s,a) A(s,a))
- A π ( s , a ) = Q π ( s , a ) − V π ( s ) A_π(s,a) = Q_π(s,a) - V_π(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
3.3 Bellman equation
贝尔曼期望方程 (Bellman Expectation Equations)
V π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V π ( s ′ ) ] Q π ( s , a ) = ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) Q π ( s ′ , a ′ ) ] V ( s ) = ∑ a ∈ A π ( a ∣ s ) Q ( s , a ) \begin{split} V^\pi(s) &= \sum_{a \in A} \pi(a|s) \sum_{s', r} P(s', r | s, a) [r + \gamma V^\pi(s')]\\ Q^\pi(s,a) &= \sum_{s', r} P(s', r | s, a) [r + \gamma \sum_{a' \in A} \pi(a'|s') Q^\pi(s',a')]\\ V(s) &= \sum_{a\in A}\pi(a|s)Q(s,a) \end{split} Vπ(s)Qπ(s,a)V(s)=a∈A∑π(a∣s)s′,r∑P(s′,r∣s,a)[r+γVπ(s′)]=s′,r∑P(s′,r∣s,a)[r+γa′∈A∑π(a′∣s′)Qπ(s′,a′)]=a∈A∑π(a∣s)Q(s,a)
或者,更简洁地,如果 V π ( s ′ ) V^\pi(s') Vπ(s′) 已知: Q π ( s , a ) = ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V π ( s ′ ) ] Q^\pi(s,a) = \sum_{s', r} P(s', r | s, a) [r + \gamma V^\pi(s')] Qπ(s,a)=∑s′,rP(s′,r∣s,a)[r+γVπ(s′)].
它为特定策略 π 下的状态价值函数 V π V_π Vπ (或动作价值函数 Q π Q_π Qπ) 提供了一个自洽的递归定义:当前状态的价值等于遵循该策略所能获得的即时奖励,加上所有可能的下一状态的折扣价值的期望。其关键作用是作为评估一个给定策略好坏的数学基石:通过求解该方程,可以精确计算出在该策略指导下,从每个状态出发能获得的长期期望回报,从而量化策略的性能,并成为策略迭代等算法中“策略评估”步骤的理论核心。
贝尔曼最优方程 (Bellman Optimality Equations):
V ( s ) = max a ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V ( s ′ ) ] Q ( s , a ) = ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ max a ′ Q ( s ′ , a ′ ) ] \begin{split} V(s) = \max_a \sum_{s', r} P(s', r | s, a) [r + \gamma V^(s')]\\ Q(s,a) = \sum_{s', r} P(s', r | s, a) [r + \gamma \max_{a'} Q(s',a')] \end{split} V(s)=amaxs′,r∑P(s′,r∣s,a)[r+γV(s′)]Q(s,a)=s′,r∑P(s′,r∣s,a)[r+γa′maxQ(s′,a′)] 且 V ( s ) = max a Q ( s , a ) V(s) = \max_a Q(s,a) V(s)=maxaQ(s,a)
想象你是一个寻宝者,在一张藏宝图(代表环境)上寻找价值最高的宝藏。地图上有很多地点(状态),你可以从一个地点移动到另一个地点(动作),每次移动可能会得到一些小奖励或付出一些代价,最终目标是找到一条路径,使得总奖励最大。
- 值迭代 (Value Iteration, VI):先搞清楚每个地点有多“值钱”,再决定怎么走。
- 迭代的是价值函数
- 策略迭代 (Policy Iteration, PI):先定个初步的行走计划,然后评估这个计划好不好,再改进计划,如此循环。
- 迭代的是策略 (虽然中间会计算价值函数)
值迭代算法直接将贝尔曼最优方程转化为一个迭代更新规则来寻找最优状态值函数 V ∗ ( s ) V^*(s) V∗(s)
- V k + 1 ( s ) ← max a ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V k ( s ′ ) ] V_{k+1}(s) \leftarrow \max_a \sum_{s', r} P(s', r | s, a) [r + \gamma V_k(s')] Vk+1(s)←maxa∑s′,rP(s′,r∣s,a)[r+γVk(s′)]
一旦得到 收敛后的值函数就是最优状态值函数 V ∗ ( s ) V^*(s) V∗(s),就可以从中提取出最优策略 π ∗ ( s ) = arg max a ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V ∗ ( s ′ ) ] \pi^*(s) = \arg\max_a \sum_{s', r} P(s', r | s, a) [r + \gamma V^*(s')] π∗(s)=argmaxa∑s′,rP(s′,r∣s,a)[r+γV∗(s′)]
3.4 MC v.s. TD
当任务是分幕式 (episodic) 的,即有明确的开始和结束(比如一盘棋,一次走迷宫)。
- 智能体需要完整地采样一条轨迹 (trajectory) τ = ( S 0 , A 0 , R 1 , S 1 , A 1 , R 2 , . . . , S T − 1 , A T − 1 , R T , S T ) \tau = (S_0, A_0, R_1, S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T, S_T) τ=(S0,A0,R1,S1,A1,R2,...,ST−1,AT−1,RT,ST),其中 T 是终止状态的时间步。
- 对于这条轨迹中的每一步 t,回报 G t G_t Gt 计算如下: G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + γ T − t − 1 R T = ∑ k = 0 T − t − 1 γ k R t + k + 1 G_t = R_{t+1} + γR_{t+2} + γ^2R_{t+3} + ... + γ^{T-t-1}R_T=\sum_{k=0}^{T-t-1}\gamma^kR_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+...+γT−t−1RT=∑k=0T−t−1γkRt+k+1 这里的 R t + 1 R_{t+1} Rt+1 是在状态 S t S_t St 执行动作 A t A_t At 后得到的即时奖励。 G t G_t Gt 是从 S t S_t St 状态之后,未来所有步骤能获得的折扣奖励总和。
- 计算的局限性,只要没抵达目标,就无法确定收益 G t G_t Gt 的值;
如果任务不是分幕式的 (continuing tasks),或者我们不想等到整个 episode 结束才计算回报(比如在时序差分学习 TD learning 中)
- 回报 G t G_t Gt 通常会用值函数来估计。 例如,在一步 TD 学习中,回报 G t G_t Gt (也称为 TD 目标) 可以估计为: G t ≈ R t + 1 + γ V ( S t + 1 ) G_t \approx R_{t+1} + γV(S_{t+1}) Gt≈Rt+1+γV(St+1)
- 这里 V ( S t + 1 ) V(S_{t+1}) V(St+1) 是对状态 S t + 1 S_{t+1} St+1 未来价值的一个估计。这就像是说:“我先拿上眼前的奖励 R t + 1 R_{t+1} Rt+1,然后估计一下我到达的新状态 S t + 1 S_{t+1} St+1 大概还能带来多少未来的折扣奖励 γ V ( S t + 1 ) γV(S_{t+1}) γV(St+1)。”
4 Policy Gradient
θ t + 1 ← θ t + α ∇ θ J ( θ t ) \theta_{t+1}\leftarrow \theta_t + \alpha \nabla_\theta J(\theta_t) θt+1←θt+α∇θJ(θt)
- 梯度方向,指向函数值增加最快的方向(梯度上升 => 最大化):在函数定义域内的任何一点,该点的梯度向量所指的方向是函数值上升最陡峭的方向
- y = − x 2 , y ′ = − 2 x y=-x^2, y'=-2x y=−x2,y′=−2x
- x ← x + 0.01 y ′ x\leftarrow x+0.01 y' x←x+0.01y′
- x = 1 , x = 1 − 0.02 x=1, x=1-0.02 x=1,x=1−0.02,向左移动(向 0 点靠近)
- x = − 1 , x = − 1 + 0.02 x=-1, x=-1+0.02 x=−1,x=−1+0.02,向右移动(向 0 点靠近)
- x ← x + 0.01 y ′ x\leftarrow x+0.01 y' x←x+0.01y′
- θ = θ + α ∗ ∇ θ f ( θ ) \theta = \theta + α * ∇_θ f(θ) θ=θ+α∗∇θf(θ)
- 梯度下降(gradient descent),沿着梯度的反方向,最小化目标;
- θ = θ − α ∗ ∇ θ f ( θ ) \theta = \theta - α * ∇_θ f(θ) θ=θ−α∗∇θf(θ)
- y = − x 2 , y ′ = − 2 x y=-x^2, y'=-2x y=−x2,y′=−2x
- ∇ θ log π θ ( A t ∣ S t ) ∇_θ \log π_θ(A_t|S_t) ∇θlogπθ(At∣St) 本身的方向就是使得 π θ ( A t ∣ S t ) π_θ(A_t|S_t) πθ(At∣St) 增加的方向。
- ∇ θ log π θ = ∇ θ π θ π θ \nabla_\theta \log\pi_\theta=\frac{\nabla_\theta \pi_\theta}{\pi_\theta} ∇θlogπθ=πθ∇θπθ, π θ \pi_\theta πθ 概率密度函数一定是 > 0 >0 >0 的;
- ∇ θ log π θ \nabla_\theta \log\pi_\theta ∇θlogπθ 方向与 ∇ θ π θ \nabla_\theta\pi_\theta ∇θπθ 方向相同,这个梯度方向显然就是 π θ \pi_\theta πθ 取值增加的方向
- 提升 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 的概率;
J ( θ ) = E [ G t ] = E τ ∼ π θ [ G 0 ] J(θ) = E[G_t]=E_{\tau\sim \pi_\theta}[G_0] J(θ)=E[Gt]=Eτ∼πθ[G0]
- https://en.wikipedia.org/wiki/Policy_gradient_method
- log-derivate trick:方便整理成策略的期望形式
- f ′ = f ∇ log f = f ( f ′ f ) f'=f\nabla \log f=f\left(\frac{f'}{f}\right) f′=f∇logf=f(ff′)
- ∇ π θ = π θ ∇ θ log π θ \nabla\pi_\theta=\pi_\theta\nabla_\theta\log\pi_\theta ∇πθ=πθ∇θlogπθ
- log-derivate trick:方便整理成策略的期望形式
∇ θ J ( θ ) = E s ∼ d π θ a ∼ π θ ( ⋅ ∣ s ) [ ∇ θ log π θ ( a ∣ s ) ⋅ R ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\substack{s \sim d^{\pi_\theta} \ a \sim \pi_\theta(\cdot|s)}} \left[ \nabla_\theta \log \pi_\theta(a|s) \cdot R(s,a) \right] ∇θJ(θ)=Es∼dπθ a∼πθ(⋅∣s)[∇θlogπθ(a∣s)⋅R(s,a)]
- R ( s , a ) R(s,a) R(s,a) (也可以理解为对当前状态 s s s 下选择动作 a a a 的奖励分配)的常见形式及其期望下标:
- G t G_t Gt (累积回报 Total Return): 这是 REINFORCE 算法中使用的形式。 ∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G t ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) G_t \right] ∇θJ(θ)=Eτ∼πθ[∑t=0T−1∇θlogπθ(at∣st)Gt]
- G t = ∑ k = t + 1 T γ k − t r k G_t=\sum_{k=t+1}^{T}\gamma^{k-t}r_k Gt=∑k=t+1Tγk−trk
- 如果在状态 s t s_t st 执行动作 a t a_t at 后,最终得到的未来总回报 G t G_t Gt 比较高,那么我们就应该增加在 s t s_t st 选择 a t a_t at 的概率(通过增大 log π θ ( a t ∣ s t ) \log \pi_\theta(a_t|s_t) logπθ(at∣st))。反之,如果 G t G_t Gt 比较低,就减小选择该动作的概率。
- 无偏估计: G t G_t Gt 是对 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ(st,at) 的无偏采样。
- $Q^{\pi_\theta}(s_t, a_t) = \mathbb{E}{\pi\theta} [G_t | S_t=s_t, A_t=a_t] $
- 高方差: G t G_t Gt 是通过(MC,monte carlo)采样一条完整的轨迹得到的(基于当前不完美的 π θ ( a t ∣ s t ) \pi_\theta(a_t|s_t) πθ(at∣st) 得到的),其随机性很大,导致梯度的方差很高,学习过程不稳定且收敛慢。(因此替换为 Q π θ ( s , a ) Q^{\pi_\theta}(s,a) Qπθ(s,a))
- Q π θ ( s , a ) Q^{\pi_\theta}(s,a) Qπθ(s,a): ∇ θ J ( θ ) = E s ∼ d π θ a ∼ π θ ( ⋅ ∣ s ) [ ∇ θ log π θ ( a ∣ s ) Q π θ ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\substack{s \sim d^{\pi_\theta} \\ a \sim \pi_\theta(\cdot|s)}} \left[ \nabla_\theta \log \pi_\theta(a|s) Q^{\pi_\theta}(s,a) \right] ∇θJ(θ)=Es∼dπθa∼πθ(⋅∣s)[∇θlogπθ(a∣s)Qπθ(s,a)]
- Q AC(Q actor critic)涉及两个模型: π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s), Q w ( s , a ) Q_w(s,a) Qw(s,a)
- Critic 负责评估在某个状态下执行某个动作有多好( Q w ( s , a ) Q_w(s,a) Qw(s,a)),Actor 则根据 Critic 的评估来调整自己的动作选择概率。如果 Critic 说某个动作好,Actor 就更倾向于选择它。
- 减小方差: Q w ( s , a ) Q_w(s,a) Qw(s,a) 通常是基于更多经验学习得到的,相比单次采样的 G t G_t Gt,它更为平滑,从而可以减小梯度的方差。
- A π θ ( s , a ) A^{\pi_\theta}(s,a) Aπθ(s,a) (优势函数 Advantage Function): ∇ θ J ( θ ) = E s ∼ d π θ a ∼ π θ ( ⋅ ∣ s ) [ ∇ θ log π θ ( a ∣ s ) A π θ ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\substack{s \sim d^{\pi_\theta} \\ a \sim \pi_\theta(\cdot|s)}} \left[ \nabla_\theta \log \pi_\theta(a|s) A^{\pi_\theta}(s,a) \right] ∇θJ(θ)=Es∼dπθa∼πθ(⋅∣s)[∇θlogπθ(a∣s)Aπθ(s,a)]
- A2C(Advantage Actor Critic),涉及两个模型 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s), V w ( s ) V_w(s) Vw(s)
- A π θ ( s , a ) = Q π θ ( s , a ) − V w ( s ) A^{\pi_\theta}(s,a) = Q^{\pi_\theta}(s,a) - V_w(s) Aπθ(s,a)=Qπθ(s,a)−Vw(s)
- 一种非常常见且有效的方式是使用 TD error 作为优势函数的估计: 对于一个在时间步 t t t 的转移 ( s t , a t , r t + 1 , s t + 1 ) (s_t,a_t,r_{t+1},s_{t+1}) (st,at,rt+1,st+1)
- Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ(st,at) 可以用一步 TD 目标来估计 r t + 1 + γ V w ( s t + 1 ) r_{t+1} + \gamma V_w(s_{t+1}) rt+1+γVw(st+1)
- 优势函数的估计 A ^ t \hat A_t A^t 就变成了: A ^ t = ( r t + 1 + γ V w ( s t + 1 ) ) − V w ( s t ) \hat{A}_t = (r_{t+1} + \gamma V_w(s_{t+1})) - V_w(s_t) A^t=(rt+1+γVw(st+1))−Vw(st)
- Actor( π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)) 根据 A ^ t \hat A_t A^t 来更新其参数 θ \theta θ。如果 A ^ t > 0 \hat A_t\gt 0 A^t>0,则增加 log π θ ( a t ∣ s t ) \log \pi_\theta(a_t|s_t) logπθ(at∣st);反之则减少。
- Critic( V w ( s ) V_w(s) Vw(s)),学习去最小化 TD error,即让 V ( s t ) V(s_t) V(st) 尽可能接近 r t + 1 + γ V w ( s t + 1 ) r_{t+1} + \gamma V_w(s_{t+1}) rt+1+γVw(st+1)
- 一种非常常见且有效的方式是使用 TD error 作为优势函数的估计: 对于一个在时间步 t t t 的转移 ( s t , a t , r t + 1 , s t + 1 ) (s_t,a_t,r_{t+1},s_{t+1}) (st,at,rt+1,st+1)
- G t G_t Gt (累积回报 Total Return): 这是 REINFORCE 算法中使用的形式。 ∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G t ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) G_t \right] ∇θJ(θ)=Eτ∼πθ[∑t=0T−1∇θlogπθ(at∣st)Gt]
∇ θ J ( θ ) ∝ ∑ s d π θ ( s ) ∑ a ( ∇ θ π θ ( a ∣ s ) ) Q π θ ( s , a ) (An intermediate step in Policy Gradient theorem derivation) The log-derivative trick states: ∇ x f ( x ) = f ( x ) ∇ x log f ( x ) . Applying this with f ( x ) = π θ ( a ∣ s ) (the policy) and variable θ : ∇ θ π θ ( a ∣ s ) = π θ ( a ∣ s ) ∇ θ log π θ ( a ∣ s ) . Substituting this identity back into the expression for ∇ θ J ( θ ) : ∇ θ J ( θ ) ∝ ∑ s d π θ ( s ) ∑ a ( π θ ( a ∣ s ) ∇ θ log π θ ( a ∣ s ) ) Q π θ ( s , a ) = ∑ s d π θ ( s ) ∑ a π θ ( a ∣ s ) [ ∇ θ log π θ ( a ∣ s ) Q π θ ( s , a ) ] = E s ∼ d π θ a ∼ π θ ( ⋅ ∣ s ) [ ∇ θ log π θ ( a ∣ s ) Q π θ ( s , a ) ] \begin{align*} \nabla_\theta J(\theta) &\propto \sum_s d^{\pi_\theta}(s) \sum_a (\nabla_\theta \pi_\theta(a|s)) Q^{\pi_\theta}(s,a) \\ &\quad \text{(An intermediate step in Policy Gradient theorem derivation)} \\ \\ &\text{The log-derivative trick states: } \nabla_x f(x) = f(x) \nabla_x \log f(x). \\ &\text{Applying this with } f(x) = \pi_\theta(a|s) \text{ (the policy) and variable } \theta: \\ \nabla_\theta \pi_\theta(a|s) &= \pi_\theta(a|s) \nabla_\theta \log \pi_\theta(a|s). \\ \\ &\text{Substituting this identity back into the expression for } \nabla_\theta J(\theta): \\ \nabla_\theta J(\theta) &\propto \sum_s d^{\pi_\theta}(s) \sum_a \left( \pi_\theta(a|s) \nabla_\theta \log \pi_\theta(a|s) \right) Q^{\pi_\theta}(s,a) \\ &= \sum_s d^{\pi_\theta}(s) \sum_a \pi_\theta(a|s) \left[ \nabla_\theta \log \pi_\theta(a|s) Q^{\pi_\theta}(s,a) \right] \\ &= \mathbb{E}_{\substack{s \sim d^{\pi_\theta} \\ a \sim \pi_\theta(\cdot|s)}} \left[ \nabla_\theta \log \pi_\theta(a|s) Q^{\pi_\theta}(s,a) \right] \end{align*} ∇θJ(θ)∇θπθ(a∣s)∇θJ(θ)∝s∑dπθ(s)a∑(∇θπθ(a∣s))Qπθ(s,a)(An intermediate step in Policy Gradient theorem derivation)The log-derivative trick states: ∇xf(x)=f(x)∇xlogf(x).Applying this with f(x)=πθ(a∣s) (the policy) and variable θ:=πθ(a∣s)∇θlogπθ(a∣s).Substituting this identity back into the expression for ∇θJ(θ):∝s∑dπθ(s)a∑(πθ(a∣s)∇θlogπθ(a∣s))Qπθ(s,a)=s∑dπθ(s)a∑πθ(a∣s)[∇θlogπθ(a∣s)Qπθ(s,a)]=Es∼dπθa∼πθ(⋅∣s)[∇θlogπθ(a∣s)Qπθ(s,a)]
- d π θ ( s ) d^{\pi_\theta}(s) dπθ(s): 在策略 π θ \pi_\theta πθ 下的状态分布
4.1 ∇ θ J ( θ ) ≈ ∑ t = 0 T − 1 ∇ θ log π θ ( A t ∣ S t ) ⏟ 方向 G t ⏟ 幅度与符号 ∇_θ J(θ) \approx \sum_{t=0}^{T-1} \underbrace{∇_θ \log π_θ(A_t|S_t)}_{\text{方向}} \underbrace{G_t}_{\text{幅度与符号}} ∇θJ(θ)≈∑t=0T−1方向 ∇θlogπθ(At∣St)幅度与符号 Gt
θ ← θ + α ⋅ ∇ θ J ( θ ) θ ← θ + α ⋅ ( ∑ t = 0 T − 1 ∇ θ log π θ ( A t ∣ S t ) G t ) \begin{split} &θ \leftarrow θ + \alpha \cdot ∇_θ J(θ)\\ &θ \leftarrow θ + \alpha \cdot \left( \sum_{t=0}^{T-1} ∇_θ \log π_θ(A_t|S_t) G_t \right) \end{split} θ←θ+α⋅∇θJ(θ)θ←θ+α⋅(t=0∑T−1∇θlogπθ(At∣St)Gt)
- 如果 G t G_t Gt 是正的且较大,说明从 ( S t , A t ) (S_t, A_t) (St,At) 开始的后续表现很好,那么我们就希望增加在 S t S_t St 状态下选择 A t A_t At 动作的概率。
- π θ ( A t ∣ S t ) ↑ \pi_\theta(A_t|S_t)\uparrow πθ(At∣St)↑
- ∇ θ log π θ ( A t ∣ S t ) ⋅ G t ∇_θ \log π_θ(A_t|S_t) \cdot G_t ∇θlogπθ(At∣St)⋅Gt 与 ∇ θ log π θ ( A t ∣ S t ) ∇_θ \log π_θ(A_t|S_t) ∇θlogπθ(At∣St) 方向相同
- 如果 G t G_t Gt 是负的或较小,说明后续表现不好,那么我们就希望减少在 S t S_t St 状态下选择 A t A_t At 动作的概率。
- π θ ( A t ∣ S t ) ↓ \pi_\theta(A_t|S_t)\downarrow πθ(At∣St)↓
- ∇ θ log π θ ( A t ∣ S t ) ⋅ G t ∇_θ \log π_θ(A_t|S_t) \cdot G_t ∇θlogπθ(At∣St)⋅Gt 与 ∇ θ log π θ ( A t ∣ S t ) ∇_θ \log π_θ(A_t|S_t) ∇θlogπθ(At∣St) 方向相反
- 书里边及老师的视频里有非常精彩的论述
- ∇ θ ln π ( a t ∣ s t , θ t ) = ∇ θ π ( a t ∣ s t , θ t ) π ( a t ∣ s t , θ t ) \nabla_\theta\ln \pi(a_t|s_t,\theta_t)=\frac{\nabla_\theta\pi(a_t|s_t,\theta_t)}{ \pi(a_t|s_t,\theta_t)} ∇θlnπ(at∣st,θt)=π(at∣st,θt)∇θπ(at∣st,θt)
- θ t + 1 = θ t + α ∇ θ ln π ( a t ∣ s t , θ t ) q t ( s t , a t ) = θ t + α ( q t ( s t , a t ) π ( a t ∣ s t , θ t ) ) ⏟ β t ∇ θ π ( a t ∣ s t , θ t ) . \begin{align*} \theta_{t+1} &= \theta_t + \alpha \nabla_\theta \ln \pi(a_t | s_t, \theta_t) q_t(s_t, a_t) \\ &= \theta_t + \alpha \underbrace{\left( \frac{q_t(s_t, a_t)}{\pi(a_t | s_t, \theta_t)} \right)}_{\beta_t} \nabla_\theta \pi(a_t | s_t, \theta_t). \end{align*} θt+1=θt+α∇θlnπ(at∣st,θt)qt(st,at)=θt+αβt (π(at∣st,θt)qt(st,at))∇θπ(at∣st,θt).
- θ t + 1 = θ t + α β t ∇ θ π ( a t ∣ s t , θ t ) \textcolor{blue}{\theta_{t+1} = \theta_t + \alpha \textcolor{red}{\beta_t} \nabla_\theta \pi(a_t | s_t, \theta_t)} θt+1=θt+αβt∇θπ(at∣st,θt)
- β t > 0 \beta_t\gt 0 βt>0:梯度上升,提升 π ( a t ∣ s t , θ t ) \pi(a_t|s_t,\theta_t) π(at∣st,θt)
- β t < 0 \beta_t\lt 0 βt<0:梯度下降,降低 π ( a t ∣ s t , θ t ) \pi(a_t|s_t,\theta_t) π(at∣st,θt)
4.2 G t G_t Gt的高方差、信用分配问题
- 如果一个完整的回答(一条轨迹 Trajectory)最终获得了很高的总奖励 ,那么就调高这条轨迹中每一步动作(生成每一个 token)的概率。反之,如果总奖励很低,就降低这些动作的概率。它直接使用蒙特卡洛采样得到的累积奖励 Gt 来指导策略更新。
- Prompt: “法国的首都是哪里?”
- “法国的首都是巴黎” 奖励模型评估: 这是一个完全正确、简洁的回答。给予高分奖励,比如 +10分。
- “法国的首都是里昂” 奖励模型评估: 这是一个事实性错误。尽管大部分内容都很好,但核心信息是错的。奖励模型会给予一个很低的惩罚性分数,比如 -10分。
{"巴黎": 90%, "里昂": 8%, "马赛": 2%}
- REINFORCE 的学习规则是:用最终的总奖励,去等同地“奖赏”或“惩罚”这条路上的每一个决策(每一个生成的 token)。
- 请看 “法国”、“的”、“首都”、“是” 这四个完全正确的、在两个场景中一模一样的 token。
- 在场景一中,它们的概率被提升了。
- 在场景二中,它们的概率被降低了。
- 模型收到了完全相反的训练信号。仅仅因为最后一个词的“运气不好”,导致前面所有正确的努力都被全盘否定。
- 请看 “法国”、“的”、“首都”、“是” 这四个完全正确的、在两个场景中一模一样的 token。
- Prompt: “法国的首都是哪里?”
- 这就是**高方差(High Variance)**的根源。对于模型来说,它完全搞不清楚自己到底做对了什么,做错了什么。它只知道“有时候我这么说会被奖励,有时候会被惩罚,看起来像纯粹的运气”。这种充满噪声和矛盾的梯度信号,使得模型很难稳定地学习到真正有用的知识,训练过程自然会剧烈波动且收敛缓慢。
- 这就是为什么 PPO 等算法要引入 Critic 网络来学习优势函数 (Advantage Function)。Critic 的作用就像一个更聪明的老师,它不只看总分,还会尝试去评估“在当前情况下,生成这个词比生成其他词好多少”,从而给出更精确、方差更低的指导信号,解决了 REINFORCE 的这个核心缺陷。而 REINFORCE++ 则是通过优势归一化等技巧,在不引入 Critic 的情况下,试图达到类似降低方差的效果。
- 信用分配不公的核心(稀疏 reward 的场景下):用一个全局的、最终的结果( G t G_t Gt),去评价一系列局部的、具体的行为( a t a_t at),导致了“一荣俱荣,一损俱损”的局面。
4.3 TRPO v.s. PPO
4.3.1 on-policy v.s. off-policy
- on-policy 同策略,off-policy 异策略
- 行为策略(rollout 产生数据的策略),目标策略(待学习的目标策略);
- 智能体学习的策略(目标策略)与它用来生成经验数据(行为策略)的策略是同一个。
- 结合策略梯度定义的相关代码分析
- https://www.datacamp.com/tutorial/policy-gradient-theorem
- 没有经验回放 (Experience Replay):代码中没有使用经验回放机制。经验回放通常用于 off-policy 算法,它允许智能体从过去由不同策略(可能是旧版本的策略或完全不同的探索策略)生成的经验中学习。而这里的代码是直接使用当前 episode 产生的数据进行更新。
- REINFORCE 是一种经典的 on-policy 策略梯度算法。
- IS (importance sampling):ratio 从哪里来的
E x ∼ p [ f ( x ) ] = ∫ p ( x ) f ( x ) d x = ∫ q ( x ) p ( x ) q ( x ) f ( x ) d x = E x ∼ q [ p ( x ) q ( x ) f ( x ) ] \begin{align*} \mathbb{E}_{x \sim p}[f(x)] &= \int p(x)f(x)dx \\ &= \int q(x) \frac{p(x)}{q(x)} f(x)dx \\ &= \mathbb{E}_{x \sim q}\left[\frac{p(x)}{q(x)}f(x)\right] \end{align*} Ex∼p[f(x)]=∫p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=Ex∼q[q(x)p(x)f(x)]
# Figure 10.2
import numpy as np
import matplotlib.pyplot as pltN_SAMPLES = 300 # 样本数量
p0_dist = {1: 0.5, -1: 0.5}
p1_dist = {1: 0.8, -1: 0.2}sample_values = np.array([1, -1])
probabilities_p1 = np.array([p1_dist[1], p1_dist[-1]])
generated_samples = np.random.choice(sample_values, size=N_SAMPLES, p=probabilities_p1)sample_indices = np.arange(1, N_SAMPLES + 1)cumulative_mean_p1 = np.cumsum(generated_samples) / sample_indicesimportance_weights = np.zeros(N_SAMPLES)
importance_weights = np.where(generated_samples == 1,p0_dist[1] / p1_dist[1],p0_dist[-1] / p1_dist[-1]
)weighted_samples = generated_samples * importance_weights
cumulative_mean_importance_sampling = np.cumsum(weighted_samples) / sample_indicesplt.figure(figsize=(7, 5)) # 图表尺寸,尽量与原图比例一致color_samples = '#ED1C24' # 红色 (样本点)
color_average_p1 = '#0072BD' # 蓝色 (p1平均值)
color_importance = '#6EAF46' # 绿色 (重要性采样平均值)
color_zeroline = 'darkgrey' # y=0 参考线颜色plt.plot(sample_indices, generated_samples, 'o',markerfacecolor='none',markeredgecolor=color_samples,markersize=6,label='samples')plt.plot(sample_indices, cumulative_mean_p1,linestyle=':',color=color_average_p1,linewidth=2,label='average')plt.plot(sample_indices, cumulative_mean_importance_sampling,linestyle='-',color=color_importance,linewidth=2,label='importance sampling')plt.axhline(0, color=color_zeroline, linestyle='-', linewidth=0.8)
plt.xlabel('Sample index', fontsize=12)
plt.xlim(0, N_SAMPLES)
plt.ylim(-2, 2.5)
plt.xticks(np.arange(0, N_SAMPLES + 1, 50), fontsize=11)
plt.yticks(np.arange(-2, 3, 1), fontsize=11)
plt.legend(fontsize=10, frameon=True, loc='upper right')plt.tight_layout()
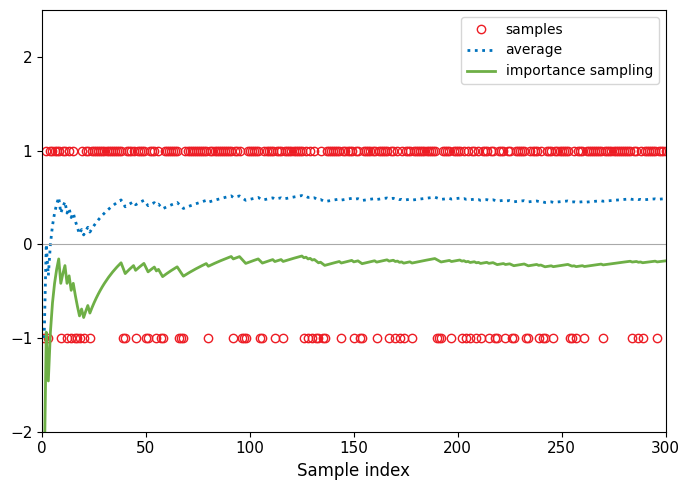
- PG可以知道参数更新的方向,但无法保证更新的步幅
maximize θ L θ o l d ( θ ) = E s ∼ ρ θ o l d , a ∼ π θ o l d [ π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A π θ o l d ( s , a ) ] subject to E s ∼ ρ θ o l d [ D K L ( π θ o l d ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ] ≤ δ \begin{aligned} \text{maximize}_{\theta} \quad & L_{\theta_{old}}(\theta) = \mathbb{E}_{s \sim \rho_{\theta_{old}}, a \sim \pi_{\theta_{old}}} \left[ \frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)} A^{\pi_{\theta_{old}}}(s,a) \right] \\ \text{subject to} \quad & \mathbb{E}_{s \sim \rho_{\theta_{old}}} [D_{KL}(\pi_{\theta_{old}}(\cdot|s) || \pi_\theta(\cdot|s))] \le \delta \end{aligned} maximizeθsubject toLθold(θ)=Es∼ρθold,a∼πθold[πθold(a∣s)πθ(a∣s)Aπθold(s,a)]Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
L C L I P ( θ ) = E t [ min ( r t ( θ ) A t π θ o l d , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t π θ o l d ) ] L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) A_t^{\pi_{\theta_{old}}}, \quad \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t^{\pi_{\theta_{old}}} \right) \right] LCLIP(θ)=Et[min(rt(θ)Atπθold,clip(rt(θ),1−ϵ,1+ϵ)Atπθold)]
5 RL v.s. SFT

在监督学习中,优化过程可以分解为两个核心步骤:
- 梯度计算: ∇ θ L ( θ ) = E x ∼ D [ ∇ θ ℓ ( f θ ( x ) , y ) ] \nabla_\theta \mathcal{L}(\theta) = \mathbb{E}_{x \sim \mathcal{D}}[\nabla_\theta \ell(f_\theta(x), y)] ∇θL(θ)=Ex∼D[∇θℓ(fθ(x),y)]
- 参数更新: θ t + 1 = θ t − α ∇ θ L ( θ t ) \theta_{t+1} = \theta_t - \alpha \nabla_\theta \mathcal{L}(\theta_t) θt+1=θt−α∇θL(θt)
其中梯度可以分解为两部分:
- 一阶导函数 g ( x ) = ∇ θ ℓ ( f θ ( x ) , y ) g(x) = \nabla_\theta \ell(f_\theta(x), y) g(x)=∇θℓ(fθ(x),y):描述损失函数的局部几何特性
- 数据点 x x x:从固定分布 D \mathcal{D} D 中采样得到
关键特点:数据分布 D \mathcal{D} D 是静态的,与参数 θ \theta θ 无关。即使步长选择不当,梯度方向通常仍然指向合理的优化方向。
强化学习中的 Policy Gradient 方法引入了额外的复杂性:
- 轨迹采样: τ ∼ p π θ ( τ ) = p ( s 0 ) ∏ t = 0 T − 1 π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \tau \sim p_{\pi_\theta}(\tau) = p(s_0) \prod_{t=0}^{T-1} \pi_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t) τ∼pπθ(τ)=p(s0)∏t=0T−1πθ(at∣st)p(st+1∣st,at)
- 梯度估计: ∇ θ J ( θ ) = E τ ∼ p π θ ( τ ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) A π θ ( s t , a t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim p_{\pi_\theta}(\tau)}[\sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) A^{\pi_\theta}(s_t, a_t)] ∇θJ(θ)=Eτ∼pπθ(τ)[∑t=0T−1∇θlogπθ(at∣st)Aπθ(st,at)]
- 参数更新: θ t + 1 = θ t + α ∇ θ J ( θ t ) \theta_{t+1} = \theta_t + \alpha \nabla_\theta J(\theta_t) θt+1=θt+α∇θJ(θt)
与监督学习不同,这里的"数据" τ \tau τ 来自于当前策略 π θ \pi_\theta πθ 与环境的交互。这导致了一个关键的循环依赖:
策略质量 → 轨迹质量 → 梯度估计质量 → 策略更新质量 \text{策略质量} \rightarrow \text{轨迹质量} \rightarrow \text{梯度估计质量} \rightarrow \text{策略更新质量} 策略质量→轨迹质量→梯度估计质量→策略更新质量
- RL 中的数据是智能体与环境交互的经验;
- learning from data (learning from interaction)
6 DeepSeekMath Unified Paradigm
∇ θ J A ( θ ) = E [ ( q , o ) ∼ D ] ⏟ Data Source ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ G C A ( q , o , t , π r f ) ⏟ Gradient Coefficient ∇ θ log π θ ( o t ∣ q , o < t ) ) \nabla_{\theta} \mathcal{J}_{\textcolor{red}{\mathcal{A}}}(\theta) = \underbrace{\mathbb{E}[(q, o) \sim \textcolor{red}{\mathcal{D}}]}_{\text{Data Source}} \left( \frac{1}{|o|} \sum_{t=1}^{|o|} \underbrace{GC_{\mathcal{A}}(q, o, t, \textcolor{red}{\pi_{rf}})}_{\text{Gradient Coefficient}} \nabla_{\theta} \log \pi_{\theta}(o_t | q, o_{<t}) \right) ∇θJA(θ)=Data Source E[(q,o)∼D] ∣o∣1t=1∑∣o∣Gradient Coefficient GCA(q,o,t,πrf)∇θlogπθ(ot∣q,o<t)
-
π r f \pi_{rf} πrf: reward function
-
the gradient coefficient GC that determines the magnitude of the penalty or reinforcement for the data.
-
log σ ( β R ( o + ) − β R ( o − ) ) \log\sigma(\beta R(o^+)-\beta R(o^-)) logσ(βR(o+)−βR(o−))
- R ( o ) = 1 ∣ o ∣ ∑ log π θ π r e f R(o)=\frac1{|o|}\sum\log\frac{\pi_\theta}{\pi_{ref}} R(o)=∣o∣1∑logπrefπθ
- ∇ log σ ( Δ ) = σ ( Δ ) ( 1 − σ ( Δ ) ) σ ( Δ ) = ( 1 − σ ( Δ ) ) = σ ( − Δ ) \nabla \log\sigma(\Delta)=\frac{\sigma(\Delta)(1-\sigma(\Delta))}{\sigma(\Delta)}=(1-\sigma(\Delta))=\sigma(-\Delta) ∇logσ(Δ)=σ(Δ)σ(Δ)(1−σ(Δ))=(1−σ(Δ))=σ(−Δ)
-
∇ π θ = π θ ∇ log π θ \nabla\pi_\theta=\pi_\theta\nabla\log\pi_\theta ∇πθ=πθ∇logπθ ( f ′ = f ∇ log f f'=f\nabla\log f f′=f∇logf)
∇ θ L DPO ( π θ , π ref ) = − β E ( x , y w , y l ) ∼ D [ σ ( r ^ θ ( x , y ℓ ) − r ^ θ ( x , y w ) ) ⏟ higher weight when reward estimate is wrong [ ∇ θ log π ( y w ∣ x ) ⏟ increase likelihood of y w − ∇ θ log π ( y ℓ ∣ x ) ⏟ decrease likelihood of y ℓ ] ] \nabla_{\theta} \mathcal{L}_{\text{DPO}}(\pi_{\theta}, \pi_{\text{ref}}) = \\ -\beta \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \underbrace{\sigma(\hat{r}_{\theta}(x, y_\ell) - \hat{r}_{\theta}(x, y_w))}_{\text{higher weight when reward estimate is wrong}} \left[ \underbrace{\nabla_{\theta} \log \pi(y_w | x)}_{\text{increase likelihood of } y_w} - \underbrace{\nabla_{\theta} \log \pi(y_\ell | x)}_{\text{decrease likelihood of } y_\ell} \right] \right] ∇θLDPO(πθ,πref)=−βE(x,yw,yl)∼D higher weight when reward estimate is wrong σ(r^θ(x,yℓ)−r^θ(x,yw)) increase likelihood of yw ∇θlogπ(yw∣x)−decrease likelihood of yℓ ∇θlogπ(yℓ∣x)
PART 2
纳什现在RL4LLM合集里面什么都放了,6.8更了一期RL的内容,这期还是PG的内容
[RL insights] 推导和理解 Policy Gradient 算法,PG vs. MLE/SFT,采样及训练过程
code
参考资料:
- https://rail.eecs.berkeley.edu/deeprlcourse/
强化学习的终极目标:
J ( θ ) = E τ [ R ( τ ) ] J ( θ ) = E τ ∼ p θ ( τ ) [ ∑ t r ( s t , a t ) ] θ ⋆ = arg max E τ ∼ p θ ( τ ) [ ∑ t r ( s t , a t ) ] = arg max ∑ t = 1 T E ( s t , a t ) ∼ p θ ( s t , a t ) [ r ( s t , a t ) ] \begin{split} J(θ) &= E_τ[R(τ)]\\ J(\theta) &=E_{\tau\sim p_\theta(\tau)}\left[\sum_tr(s_t,a_t)\right]\\ \theta^\star&=\arg\max E_{\tau\sim p_\theta(\tau)}\left[\sum_tr(s_t,a_t)\right]\\ &=\arg\max\sum_{t=1}^TE_{(s_t,a_t)\sim p_\theta(s_t,a_t)}[r(s_t,a_t)] \end{split} J(θ)J(θ)θ⋆=Eτ[R(τ)]=Eτ∼pθ(τ)[t∑r(st,at)]=argmaxEτ∼pθ(τ)[t∑r(st,at)]=argmaxt=1∑TE(st,at)∼pθ(st,at)[r(st,at)]
-
最大化所有可能轨迹对应的回报的期望(an expected value under the trajectory distribution of the sum of rewards)
- p θ ( τ ) = p θ ( s 1 , a 1 , s 2 , a 2 , ⋯ , s T , a T ) = p ( s 1 ) Π t = 1 T π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) p_\theta(\tau)=p_\theta(s_1,a_1,s_2,a_2,\cdots,s_T,a_T)=p(s_1)\Pi_{t=1}^T\pi_\theta(a_t|s_t)p(s_{t+1}|s_t,a_t) pθ(τ)=pθ(s1,a1,s2,a2,⋯,sT,aT)=p(s1)Πt=1Tπθ(at∣st)p(st+1∣st,at)
- 绝不仅仅只是当前即时的 reward( r ( s , a ) r(s,a) r(s,a)),比如开车开得很快即时的奖励可能很高,但后续可能会有危险(low reward)的结果
- 期望一定是关于某一概率分布的,这里是关于轨迹( p θ ( τ ) p_\theta(\tau) pθ(τ))的回报的期望;
- standard RL objective:无法直接优化,才有了后续的易于优化的 policy gradient,ppo 等
- 对比看下 soft rl,dpo;
- ∑ t = 1 T E ( s t , a t ) ∼ p θ ( s t , a t ) [ r ( s t , a t ) ] \sum_{t=1}^TE_{(s_t,a_t)\sim p_\theta(s_t,a_t)}[r(s_t,a_t)] ∑t=1TE(st,at)∼pθ(st,at)[r(st,at)]:先对 r ( s t , a t ) r(s_t,a_t) r(st,at) 求期望再加和
- p ( s t + 1 , a t + 1 ∣ s t , a t ) = p ( s t + 1 ∣ s t , a t ) π θ ( a t + 1 ∣ s t + 1 ) p(s_{t+1},a_{t+1}|s_t,a_t)=p(s_{t+1}|s_t,a_t)\pi_\theta(a_{t+1}|s_{t+1}) p(st+1,at+1∣st,at)=p(st+1∣st,at)πθ(at+1∣st+1)
- 从“评估无数条完整路径的平均总分”,转变为“评估在每个时间步的平均得分,然后把它们加起来”。
-
J ( θ ) = ∫ P ( τ ∣ θ ) ⋅ R ( τ ) d τ J(θ) = ∫ P(τ|θ) \cdot R(τ) dτ J(θ)=∫P(τ∣θ)⋅R(τ)dτ
- 直接尝试对 RL objective 求导
- ∇ θ J ( θ ) = ∇ θ ∫ P ( τ ∣ θ ) ⋅ R ( τ ) d τ ∇_θ J(θ) = ∇_θ ∫ P(τ|θ) \cdot R(τ) dτ ∇θJ(θ)=∇θ∫P(τ∣θ)⋅R(τ)dτ
- ∇ θ J ( θ ) = ∫ [ ∇ θ P ( τ ∣ θ ) ] ⋅ R ( τ ) d τ ∇_θ J(θ) = ∫ [∇_θ P(τ|θ)] \cdot R(τ) dτ ∇θJ(θ)=∫[∇θP(τ∣θ)]⋅R(τ)dτ
- 我们没法直接计算 ∇ θ P ( τ ∣ θ ) ∇_θ P(τ|θ) ∇θP(τ∣θ),更重要的是,梯度算子作用在了概率分布 P ( τ ∣ θ ) P(τ|θ) P(τ∣θ) 上,这使得我们无法通过采样(sampling)来估计这个积分。我们需要把 ∇ θ ∇_θ ∇θ 从 P ( τ ∣ θ ) P(τ|θ) P(τ∣θ) 上“挪开”。
- ∇ θ P ( τ ∣ θ ) ∇_θ P(τ|θ) ∇θP(τ∣θ) 不是概率分布(可正可负,刻画的是 改变策略参数 θ θ θ 时,轨迹 τ τ τ 发生的概率会如何变化)
- ∇ θ P ( τ ∣ θ ) = P ( τ ∣ θ ) ⋅ ∇ θ log P ( τ ∣ θ ) ∇_θ P(τ|θ) = P(τ|θ) \cdot ∇_θ \log P(τ|θ) ∇θP(τ∣θ)=P(τ∣θ)⋅∇θlogP(τ∣θ)
- ∇ f = f ∇ log f \nabla f=f\nabla \log f ∇f=f∇logf
- 我们没法直接计算 ∇ θ P ( τ ∣ θ ) ∇_θ P(τ|θ) ∇θP(τ∣θ),更重要的是,梯度算子作用在了概率分布 P ( τ ∣ θ ) P(τ|θ) P(τ∣θ) 上,这使得我们无法通过采样(sampling)来估计这个积分。我们需要把 ∇ θ ∇_θ ∇θ 从 P ( τ ∣ θ ) P(τ|θ) P(τ∣θ) 上“挪开”。
- ∇ θ J ( θ ) = ∫ P ( τ ∣ θ ) ⋅ [ R ( τ ) ⋅ ∇ θ log P ( τ ∣ θ ) ] d τ ∇_θ J(θ) = ∫ P(τ|θ) \cdot [R(τ) \cdot ∇_θ \log P(τ|θ)] dτ ∇θJ(θ)=∫P(τ∣θ)⋅[R(τ)⋅∇θlogP(τ∣θ)]dτ
- P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ):属于可以被采样的概率分布
- ∑ t ∇ θ log π θ ( a t ∣ s t ) ∑_t ∇_θ \log π_θ(a_t|s_t) ∑t∇θlogπθ(at∣st),这是可以通过策略网络的反向传播计算的
- ∇ θ J ( θ ) = E τ [ R ( τ ) ⋅ ∇ θ log P ( τ ∣ θ ) ] ∇_θ J(θ) = E_τ [ R(τ) \cdot ∇_θ \log P(τ|θ)] ∇θJ(θ)=Eτ[R(τ)⋅∇θlogP(τ∣θ)]
- P ( τ ∣ θ ) = p ( s 0 ) ⋅ π θ ( a 0 ∣ s 0 ) ⋅ p ( s 1 ∣ s 0 , a 0 ) ⋅ π θ ( a 1 ∣ s 1 ) ⋅ . . . P(τ|θ) = p(s_0) \cdot π_θ(a_0|s_0) \cdot p(s_1|s_0, a_0) \cdot π_θ(a_1|s_1) \cdot ... P(τ∣θ)=p(s0)⋅πθ(a0∣s0)⋅p(s1∣s0,a0)⋅πθ(a1∣s1)⋅...
- ∇ θ log P ( τ ∣ θ ) = ∇ θ [ log p ( s 0 ) + ∑ t log π θ ( a t ∣ s t ) + ∑ t log p ( s t + 1 ∣ s t , a t ) ] ∇_θ \log P(τ|θ) = ∇_θ [ \log p(s_0) + ∑_t \log π_θ(a_t|s_t) + ∑_t \log p(s_{t+1}|s_t, a_t) ] ∇θlogP(τ∣θ)=∇θ[logp(s0)+∑tlogπθ(at∣st)+∑tlogp(st+1∣st,at)]
- 环境的状态转移概率 p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t, a_t) p(st+1∣st,at) 和初始状态概率 p ( s 0 ) p(s_0) p(s0) 都与我们的策略参数 θ θ θ 无关,所以它们的梯度为0。只剩下策略部分:
- ∇ θ log P ( τ ∣ θ ) = ∑ t ∇ θ log π θ ( a t ∣ s t ) ∇_θ \log P(τ|θ) = ∑_t ∇_θ \log π_θ(a_t|s_t) ∇θlogP(τ∣θ)=∑t∇θlogπθ(at∣st)
∇ θ J ( θ ) = E τ [ R ( τ ) ⋅ ( ∑ t ∇ θ log π θ ( a t ∣ s t ) ) ] ∇_θ J(θ) = E_τ [ R(τ) \cdot (∑_t ∇_θ \log π_θ(a_t|s_t)) ] ∇θJ(θ)=Eτ[R(τ)⋅(t∑∇θlogπθ(at∣st))]
- ∇ θ log P ( τ ∣ θ ) = ∑ t ∇ θ log π θ ( a t ∣ s t ) ∇_θ \log P(τ|θ) = ∑_t ∇_θ \log π_θ(a_t|s_t) ∇θlogP(τ∣θ)=∑t∇θlogπθ(at∣st)
-
整个过程
- 我们用当前策略 π θ π_θ πθ 运行 N 次,得到 N 条轨迹 τ 1 , τ 2 , . . . , τ N τ_1, τ_2, ..., τ_N τ1,τ2,...,τN。这等价于从 P ( τ ∣ θ ) P(τ|θ) P(τ∣θ) 中采样。
- J ( θ ) = E τ ∼ p θ ( τ ) [ ∑ t r ( s t , a t ) ] ≈ 1 N ∑ i ∑ t r ( s i , t , a i , t ) J(\theta) = E_{\tau \sim p_\theta(\tau)} \left[ \sum_t r(\mathbf{s}_t, \mathbf{a}_t) \right] \approx \frac{1}{N} \sum_i \sum_t r(\mathbf{s}_{i,t}, \mathbf{a}_{i,t}) J(θ)=Eτ∼pθ(τ)[∑tr(st,at)]≈N1∑i∑tr(si,t,ai,t)
- 对于每一条轨迹 τ i τ_i τi,我们计算一个值 V i = R ( τ i ) ⋅ ∇ θ log P ( τ i ∣ θ ) V_i = R(τ_i)\cdot∇_θ \log P(τ_i|θ) Vi=R(τi)⋅∇θlogP(τi∣θ)
- 平均: ∇ θ J ( θ ) ≈ ( 1 / N ) ∗ ∑ V i ∇_θ J(θ) ≈ (1/N) * ∑ V_i ∇θJ(θ)≈(1/N)∗∑Vi。
- 梯度上升
- 我们用当前策略 π θ π_θ πθ 运行 N 次,得到 N 条轨迹 τ 1 , τ 2 , . . . , τ N τ_1, τ_2, ..., τ_N τ1,τ2,...,τN。这等价于从 P ( τ ∣ θ ) P(τ|θ) P(τ∣θ) 中采样。
-
两个可以优化的地方
- 因果性 (Causality):在 t t t 时刻的决策,不应该被 t t t 时刻之前的奖励所影响。所以,对于 t t t 时刻的策略梯度 ∇ θ log π θ ( a t ∣ s t ) ∇_θ \log π_θ(a_t|s_t) ∇θlogπθ(at∣st),我们只应该乘以它未来的回报 G t = ∑ k = t T r k G_t = ∑_{k=t}^T r_k Gt=∑k=tTrk(return to go ),而不是整个轨迹的回报 R ( τ ) R(τ) R(τ)。
- 高方差 (High Variance):回报值本身波动很大。我们可以减去一个基线 (Baseline) b ( s t ) b(s_t) b(st) 来减小方差,而不改变梯度的期望值。最常用的基线就是状态价值函数 V ( s t ) V(s_t) V(st)。
- 经过这两个优化,我们将乘数项从 R ( τ ) R(τ) R(τ) 变成了 优势函数 (Advantage Function) A t = G t − V ( s t ) A_t = G_t - V(s_t) At=Gt−V(st)。
| 变换前 (Problematic Form) | 变换后 (Solvable Form) | |
|---|---|---|
| 积分形式 | ∫ [∇_θ P(τ|θ)] * R(τ) dτ | ∫ P(τ|θ) * [R(τ) * ∇_θ log P(τ|θ)] dτ |
| 采样分布 | ∇_θ P(τ|θ) (不是概率分布, 无法采样) | P(τ|θ) (是概率分布, 可以采样) |
| 待求值的函数 | R(τ) | R(τ) * ∇_θ log P(τ|θ) |
| 可行性 | 无法通过蒙特卡洛方法估算 | 可以通过蒙特卡洛方法估算 |
我们精心设计一个损失函数 L(θ),使得最小化 L(θ) 的效果等同于最大化 J(θ)。
L ( θ ) = − E [ ∑ t ( log π θ ( a t ∣ s t ) ⋅ G t ) ] L(θ) = - E [ ∑_t (\log π_θ(a_t|s_t) \cdot G_t) ] L(θ)=−E[t∑(logπθ(at∣st)⋅Gt)]
-
∇ θ L ( θ ) = − ∇ θ J ( θ ) ∇_θ L(θ) = -∇_θ J(θ) ∇θL(θ)=−∇θJ(θ)
- ∇ θ L ( θ ) ∇_θ L(θ) ∇θL(θ):
loss.backward()
- ∇ θ L ( θ ) ∇_θ L(θ) ∇θL(θ):
-
在很多优化问题中,我们真正想优化的“原始目标”(True Objective)往往很难处理(比如包含期望、不可微等)。因此,我们会构造一个更容易处理的**“代理目标” (Surrogate Objective)**。我们对代理目标的要求是:优化这个代理目标,能够保证我们的原始目标也得到改善。
- ppo-clip 也是一种代理目标;
-
pg vs. mle (sft)
- mle:一视同仁增加所有动作的概率(专家数据,无负样本)
- pg:根据奖励值进行增加或减少,高回报 trajectory 的 log p 会提升,低回报 trajectory 的 log p 会降低
- weighted version of mle

![[附源码+数据库+毕业论文]基于Spring+MyBatis+MySQL+Maven+jsp实现的校园服务平台管理系统,推荐!](http://pic.xiahunao.cn/[附源码+数据库+毕业论文]基于Spring+MyBatis+MySQL+Maven+jsp实现的校园服务平台管理系统,推荐!)
)


相关设置项)













