Laplace 噪声是一种特定概率分布(拉普拉斯分布)产生的随机扰动。它是差分隐私(Differential Privacy, DP)中最核心、最常用的噪声机制之一。它的核心作用是在不泄露个体信息的前提下,允许从包含敏感数据的数据库中提取有用的统计信息。目的: 直接保护数据库中的个体记录不被推断出来。即使攻击者拥有除目标个体之外的所有其他数据,也无法通过查询结果确认该目标个体是否在数据库中或其具体属性值。
1. 原理
-
通过在查询结果(如计数、求和、平均值等)上添加精心设计的、符合拉普拉斯分布的噪声,使得查询输出对数据库中任何单一个体记录的加入或移除变得“不敏感”。这种“不敏感”的程度由隐私参数
ε严格控制。 -
提供可量化、可证明的隐私保证。
ε值越小,添加的噪声越大,隐私保护强度越高(但数据可用性会降低)。
2. Laplace 噪声实现原理(核心:差分隐私)
Laplace 噪声在差分隐私中的运用原理:
-
邻近数据集: 考虑两个仅在一条个体记录上存在差异的数据集
D和D'。它们被称为“邻近数据集”。 -
查询函数: 定义一个查询函数
f(例如,“数据集中有多少人患有某种疾病?”,“工资总和是多少?”)。该函数作用于数据集并输出一个实数f(D)或实数向量f(D)=(f₁(D),f₂(D), ..., fₖ(D))。 -
全局敏感度: Laplace机制的核心参数。
-
定义:对于一个查询函数
 (输出 k 维实数向量),其
(输出 k 维实数向量),其 L1全局敏感度Δf定义为在所有邻近数据集(D,D')上,f(D)和f(D')的L1距离的最大值: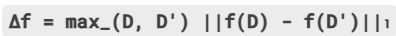
-
意义:
Δf衡量了查询函数f的输出结果,在任意一条记录改变时,最大可能改变多少。例如:-
计数查询: “数据集中满足某条件的人数”。改变一条记录最多只能让计数改变
1(满足条件的记录加入或移除)。所以Δf=1。 -
求和查询: “数据集中某数值型属性的总和”。假设单个记录的最大可能值是
M,那么改变一条记录最多能让总和改变M(一个值为M的记录加入或移除)。所以Δf=M。
-
-
-
Laplace 机制:
-
目标: 保护邻近数据集
D和D'上的查询结果f(D)和f(D')在概率分布上非常接近,使得攻击者难以区分查询是基于D还是D'进行的。 -
方法: 对于查询
f的(标量或向量)输出f(D),添加独立生成的拉普拉斯噪声:
M(D)=f(D)+(Y₁, Y₂, ..., Yₖ)
其中每个Yᵢ是独立同分布的随机变量,服从拉普拉斯分布Lap(0,b),其概率密度函数为: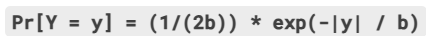
-
尺度参数
b的选择: 尺度参数b直接决定了噪声的大小。为了满足ε-差分隐私,b必须设置为:
b=Δf/ε-
ε:隐私预算,由数据所有者设定。ε越小,要求的隐私保护越强。 -
Δf:查询函数的全局敏感度。
-
-
原理证明(直观): 拉普拉斯分布的特性(指数衰减)使得添加噪声后的输出
M(D)和M(D')的概率密度比值 被有界地控制在
被有界地控制在 ε-差分隐私的数学定义所要求的。Δf决定了噪声的尺度b,从而保证了即使f(D)和f(D')差异最大(达到Δf)时,这个比值也不会超过e^ε。
-
3. 生成 Laplace 噪声的步骤 (编程实现)
要在代码中生成服从Lap(0,b)分布的噪声Y,可以使用以下方法:
-
生成均匀分布随机数: 生成两个独立的、在
[0,1)区间上均匀分布的随机数U₁和U₂。通常使用标准库的随机数生成器(如Math.random()in JS,random.random()in Python,rand()in C++)。 -
生成标准均匀分布随机数: 将
U₁转换为(-1,1)区间上的均匀分布。一种常见方法是:
U=U₁*2-1(现在U在[-1,1)上均匀分布) -
生成标准拉普拉斯噪声: 利用均匀分布随机数的反函数变换:
Y_standard=-sign(U)*ln(1-|U|)-
sign(U)是U的符号(U>=0时为1,U<0时为-1)。 -
ln(1-|U|)是自然对数。 -
Y_standard服从标准拉普拉斯分布Lap(0,1)。
-
-
缩放: 将标准拉普拉斯噪声
Y_standard乘以尺度参数b,得到最终需要的噪声:
Y=b*Y_standard
这个Y就服从Lap(0,b)分布。




)
中安装 python-maturin 的记录)




)
)
)


)



